 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaïve Exposure of Generative AI Capabilities Undermines Deepfake Detection
Mar 11, 2026Generative AI systems increasingly expose powerful reasoning and image refinement capabilities through user-facing chatbot interfaces. In this work, we show that the naïve exposure of such capabilities fundamentally undermines modern deepfake detectors. Rather than proposing a new image manipulation technique, we study a realistic and already-deployed usage scenario in which an adversary uses only benign, policy-compliant prompts and commercial generative AI systems. We demonstrate that state-of-the-art deepfake detection methods fail under semantic-preserving image refinement. Specifically, we show that generative AI systems articulate explicit authenticity criteria and inadvertently externalize them through unrestricted reasoning, enabling their direct reuse as refinement objectives. As a result, refined images simultaneously evade detection, preserve identity as verified by commercial face recognition APIs, and exhibit substantially higher perceptual quality. Importantly, we find that widely accessible commercial chatbot services pose a significantly greater security risk than open-source models, as their superior realism, semantic controllability, and low-barrier interfaces enable effective evasion by non-expert users. Our findings reveal a structural mismatch between the threat models assumed by current detection frameworks and the actual capabilities of real-world generative AI. While detection baselines are largely shaped by prior benchmarks, deployed systems expose unrestricted authenticity reasoning and refinement despite stringent safety controls in other domains.
Scores Know Bobs Voice: Speaker Impersonation Attack
Mar 03, 2026Advances in deep learning have enabled the widespread deployment of speaker recognition systems (SRSs), yet they remain vulnerable to score-based impersonation attacks. Existing attacks that operate directly on raw waveforms require a large number of queries due to the difficulty of optimizing in high-dimensional audio spaces. Latent-space optimization within generative models offers improved efficiency, but these latent spaces are shaped by data distribution matching and do not inherently capture speaker-discriminative geometry. As a result, optimization trajectories often fail to align with the adversarial direction needed to maximize victim scores. To address this limitation, we propose an inversion-based generative attack framework that explicitly aligns the latent space of the synthesis model with the discriminative feature space of SRSs. We first analyze the requirements of an inverse model for score-based attacks and introduce a feature-aligned inversion strategy that geometrically synchronizes latent representations with speaker embeddings. This alignment ensures that latent updates directly translate into score improvements. Moreover, it enables new attack paradigms, including subspace-projection-based attacks, which were previously infeasible due to the absence of a faithful feature-to-audio mapping. Experiments show that our method significantly improves query efficiency, achieving competitive attack success rates with on average 10x fewer queries than prior approaches. In particular, the enabled subspace-projection-based attack attains up to 91.65% success using only 50 queries. These findings establish feature-aligned inversion as a key tool for evaluating the robustness of modern SRSs against score-based impersonation threats.
Non-Adaptive Adversarial Face Generation
Jul 16, 2025


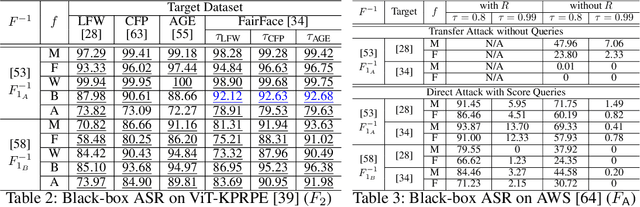
Adversarial attacks on face recognition systems (FRSs) pose serious security and privacy threats, especially when these systems are used for identity verification. In this paper, we propose a novel method for generating adversarial faces-synthetic facial images that are visually distinct yet recognized as a target identity by the FRS. Unlike iterative optimization-based approaches (e.g., gradient descent or other iterative solvers), our method leverages the structural characteristics of the FRS feature space. We figure out that individuals sharing the same attribute (e.g., gender or race) form an attributed subsphere. By utilizing such subspheres, our method achieves both non-adaptiveness and a remarkably small number of queries. This eliminates the need for relying on transferability and open-source surrogate models, which have been a typical strategy when repeated adaptive queries to commercial FRSs are impossible. Despite requiring only a single non-adaptive query consisting of 100 face images, our method achieves a high success rate of over 93% against AWS's CompareFaces API at its default threshold. Furthermore, unlike many existing attacks that perturb a given image, our method can deliberately produce adversarial faces that impersonate the target identity while exhibiting high-level attributes chosen by the adversary.
IDFace: Face Template Protection for Efficient and Secure Identification
Jul 16, 2025As face recognition systems (FRS) become more widely used, user privacy becomes more important. A key privacy issue in FRS is protecting the user's face template, as the characteristics of the user's face image can be recovered from the template. Although recent advances in cryptographic tools such as homomorphic encryption (HE) have provided opportunities for securing the FRS, HE cannot be used directly with FRS in an efficient plug-and-play manner. In particular, although HE is functionally complete for arbitrary programs, it is basically designed for algebraic operations on encrypted data of predetermined shape, such as a polynomial ring. Thus, a non-tailored combination of HE and the system can yield very inefficient performance, and many previous HE-based face template protection methods are hundreds of times slower than plain systems without protection. In this study, we propose IDFace, a new HE-based secure and efficient face identification method with template protection. IDFace is designed on the basis of two novel techniques for efficient searching on a (homomorphically encrypted) biometric database with an angular metric. The first technique is a template representation transformation that sharply reduces the unit cost for the matching test. The second is a space-efficient encoding that reduces wasted space from the encryption algorithm, thus saving the number of operations on encrypted templates. Through experiments, we show that IDFace can identify a face template from among a database of 1M encrypted templates in 126ms, showing only 2X overhead compared to the identification over plaintexts.