 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNes2Net: A Lightweight Nested Architecture for Foundation Model Driven Speech Anti-spoofing
Apr 08, 2025Speech foundation models have significantly advanced various speech-related tasks by providing exceptional representation capabilities. However, their high-dimensional output features often create a mismatch with downstream task models, which typically require lower-dimensional inputs. A common solution is to apply a dimensionality reduction (DR) layer, but this approach increases parameter overhead, computational costs, and risks losing valuable information. To address these issues, we propose Nested Res2Net (Nes2Net), a lightweight back-end architecture designed to directly process high-dimensional features without DR layers. The nested structure enhances multi-scale feature extraction, improves feature interaction, and preserves high-dimensional information. We first validate Nes2Net on CtrSVDD, a singing voice deepfake detection dataset, and report a 22% performance improvement and an 87% back-end computational cost reduction over the state-of-the-art baseline. Additionally, extensive testing across four diverse datasets: ASVspoof 2021, ASVspoof 5, PartialSpoof, and In-the-Wild, covering fully spoofed speech, adversarial attacks, partial spoofing, and real-world scenarios, consistently highlights Nes2Net's superior robustness and generalization capabilities. The code package and pre-trained models are available at https://github.com/Liu-Tianchi/Nes2Net.
Multi-Stage Face-Voice Association Learning with Keynote Speaker Diarization
Jul 25, 2024



The human brain has the capability to associate the unknown person's voice and face by leveraging their general relationship, referred to as ``cross-modal speaker verification''. This task poses significant challenges due to the complex relationship between the modalities. In this paper, we propose a ``Multi-stage Face-voice Association Learning with Keynote Speaker Diarization''~(MFV-KSD) framework. MFV-KSD contains a keynote speaker diarization front-end to effectively address the noisy speech inputs issue. To balance and enhance the intra-modal feature learning and inter-modal correlation understanding, MFV-KSD utilizes a novel three-stage training strategy. Our experimental results demonstrated robust performance, achieving the first rank in the 2024 Face-voice Association in Multilingual Environments (FAME) challenge with an overall Equal Error Rate (EER) of 19.9%. Details can be found in https://github.com/TaoRuijie/MFV-KSD.
Temporal-Channel Modeling in Multi-head Self-Attention for Synthetic Speech Detection
Jun 25, 2024Recent synthetic speech detectors leveraging the Transformer model have superior performance compared to the convolutional neural network counterparts. This improvement could be due to the powerful modeling ability of the multi-head self-attention (MHSA) in the Transformer model, which learns the temporal relationship of each input token. However, artifacts of synthetic speech can be located in specific regions of both frequency channels and temporal segments, while MHSA neglects this temporal-channel dependency of the input sequence. In this work, we proposed a Temporal-Channel Modeling (TCM) module to enhance MHSA's capability for capturing temporal-channel dependencies. Experimental results on the ASVspoof 2021 show that with only 0.03M additional parameters, the TCM module can outperform the state-of-the-art system by 9.25% in EER. Further ablation study reveals that utilizing both temporal and channel information yields the most improvement for detecting synthetic speech.
Emphasized Non-Target Speaker Knowledge in Knowledge Distillation for Automatic Speaker Verification
Sep 26, 2023Knowledge distillation (KD) is used to enhance automatic speaker verification performance by ensuring consistency between large teacher networks and lightweight student networks at the embedding level or label level. However, the conventional label-level KD overlooks the significant knowledge from non-target speakers, particularly their classification probabilities, which can be crucial for automatic speaker verification. In this paper, we first demonstrate that leveraging a larger number of training non-target speakers improves the performance of automatic speaker verification models. Inspired by this finding about the importance of non-target speakers' knowledge, we modified the conventional label-level KD by disentangling and emphasizing the classification probabilities of non-target speakers during knowledge distillation. The proposed method is applied to three different student model architectures and achieves an average of 13.67% improvement in EER on the VoxCeleb dataset compared to embedding-level and conventional label-level KD methods.
Estimation of speaker age and height from speech signal using bi-encoder transformer mixture model
Mar 22, 2022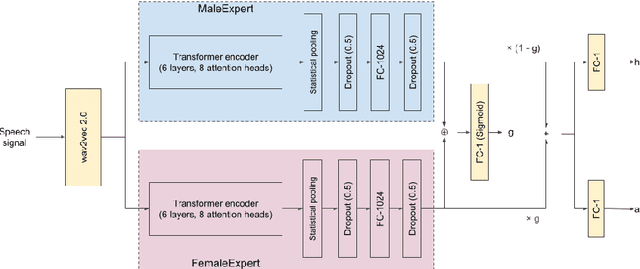
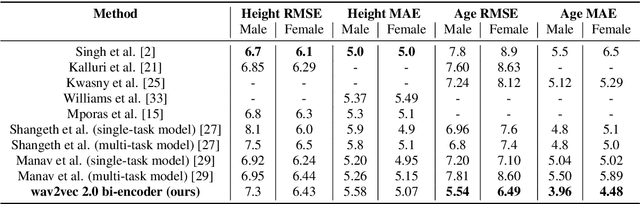


The estimation of speaker characteristics such as age and height is a challenging task, having numerous applications in voice forensic analysis. In this work, we propose a bi-encoder transformer mixture model for speaker age and height estimation. Considering the wide differences in male and female voice characteristics such as differences in formant and fundamental frequencies, we propose the use of two separate transformer encoders for the extraction of specific voice features in the male and female gender, using wav2vec 2.0 as a common-level feature extractor. This architecture reduces the interference effects during backpropagation and improves the generalizability of the model. We perform our experiments on the TIMIT dataset and significantly outperform the current state-of-the-art results on age estimation. Specifically, we achieve root mean squared error (RMSE) of 5.54 years and 6.49 years for male and female age estimation, respectively. Further experiment to evaluate the relative importance of different phonetic types for our task demonstrate that vowel sounds are the most distinguishing for age estimation.