 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Anomaly Detection Using Einstein Fuzzy Computing and Quantum Neural Network
May 06, 2026In the remote sensing (RS) field, hyperspectral imagery provides rich spectral information and facilitates numerous critical applications, such as material identification. Among these applications, hyperspectral anomaly detection (HAD) aims to detect substances whose spectral characteristics deviate from background spectra, which are termed anomalies. However, many widely used HAD algorithms in the RS community identify anomalies by relying on a ``background reconstruction'' strategy. Furthermore, the lack of prior target hyperspectrum and real-world limitations collectively reduces the spectral discrepancy between anomaly and background, limiting the performance of mainstream detections. By exploring the widely applicable fuzzy theory in the RS field, this study develops an unsupervised hybrid quantum-fuzzy multi-criteria decision framework (HyFuHAD) to detect anomalies from multiple perspectives. In our HyFuHAD, each pixel is first fuzzified using multiple HAD-based membership functions (MFs), including morphological, geometrical, and statistical MFs, to obtain various types of fuzzy degrees. Then, a multi-fuzzy-rule system, empowered by Einstein fuzzy computing, infers the classical fuzzy detection from these fuzzy degrees with sub-second-level computing. The Einstein sum and product provide significantly smoother transitions compared to typical min-max-based fuzzy ``OR'' and ``AND'' during the fuzzy matching and inference steps, thereby enabling effective detections. Moreover, a lightweight quantum defuzzifier obtains the quantum fuzzy detection from fuzzy features derived from the proposed fuzzy feature aggregation network. Experiments demonstrate that our HyFuHAD algorithm achieves state-of-the-art performance by fusing the information from the quantum and classical detectors. The demo code will be publicly available at https://github.com/IHCLab/HyFuHAD.
Training a Student Expert via Semi-Supervised Foundation Model Distillation
Apr 04, 2026Foundation models deliver strong perception but are often too computationally heavy to deploy, and adapting them typically requires costly annotations. We introduce a semi-supervised knowledge distillation (SSKD) framework that compresses pre-trained vision foundation models (VFMs) into compact experts using limited labeled and abundant unlabeled data, and instantiate it for instance segmentation where per-pixel labels are particularly expensive. The framework unfolds in three stages: (1) domain adaptation of the VFM(s) via self-training with contrastive calibration, (2) knowledge transfer through a unified multi-objective loss, and (3) student refinement to mitigate residual pseudo-label bias. Central to our approach is an instance-aware pixel-wise contrastive loss that fuses mask and class scores to extract informative negatives and enforce clear inter-instance margins. By maintaining this contrastive signal across both adaptation and distillation, we align teacher and student embeddings and more effectively leverage unlabeled images. On Cityscapes and ADE20K, our $\approx 11\times$ smaller student improves over its zero-shot VFM teacher(s) by +11.9 and +8.6 AP, surpasses adapted teacher(s) by +3.4 and +1.5 AP, and outperforms state-of-the-art SSKD methods on benchmarks.
NaviDriveVLM: Decoupling High-Level Reasoning and Motion Planning for Autonomous Driving
Mar 09, 2026Vision-language models (VLMs) have emerged as a promising direction for end-to-end autonomous driving (AD) by jointly modeling visual observations, driving context, and language-based reasoning. However, existing VLM-based systems face a trade-off between high-level reasoning and motion planning: large models offer strong semantic understanding but are costly to adapt for precise control, whereas small VLM models can be fine-tuned efficiently but often exhibit weaker reasoning. We propose NaviDriveVLM, a decoupled framework that separates reasoning from action generation using a large-scale Navigator and a lightweight trainable Driver. This design preserves reasoning ability, reduces training cost, and provides an explicit interpretable intermediate representation for downstream planning. Experiments on the nuScenes benchmark show that NaviDriveVLM outperforms large VLM baselines in end-to-end motion planning.
CAST: Contrastive Adaptation and Distillation for Semi-Supervised Instance Segmentation
May 29, 2025Instance segmentation demands costly per-pixel annotations and large models. We introduce CAST, a semi-supervised knowledge distillation (SSKD) framework that compresses pretrained vision foundation models (VFM) into compact experts using limited labeled and abundant unlabeled data. CAST unfolds in three stages: (1) domain adaptation of the VFM teacher(s) via self-training with contrastive pixel calibration, (2) distillation into a compact student via a unified multi-objective loss that couples standard supervision and pseudo-labels with our instance-aware pixel-wise contrastive term, and (3) fine-tuning on labeled data to remove residual pseudo-label bias. Central to CAST is an \emph{instance-aware pixel-wise contrastive loss} that fuses mask and class scores to mine informative negatives and enforce clear inter-instance margins. By maintaining this contrastive signal across both adaptation and distillation, we align teacher and student embeddings and fully leverage unlabeled images. On Cityscapes and ADE20K, our ~11X smaller student surpasses its adapted VFM teacher(s) by +3.4 AP (33.9 vs. 30.5) and +1.5 AP (16.7 vs. 15.2) and outperforms state-of-the-art semi-supervised approaches.
SwinMTL: A Shared Architecture for Simultaneous Depth Estimation and Semantic Segmentation from Monocular Camera Images
Mar 15, 2024



This research paper presents an innovative multi-task learning framework that allows concurrent depth estimation and semantic segmentation using a single camera. The proposed approach is based on a shared encoder-decoder architecture, which integrates various techniques to improve the accuracy of the depth estimation and semantic segmentation task without compromising computational efficiency. Additionally, the paper incorporates an adversarial training component, employing a Wasserstein GAN framework with a critic network, to refine model's predictions. The framework is thoroughly evaluated on two datasets - the outdoor Cityscapes dataset and the indoor NYU Depth V2 dataset - and it outperforms existing state-of-the-art methods in both segmentation and depth estimation tasks. We also conducted ablation studies to analyze the contributions of different components, including pre-training strategies, the inclusion of critics, the use of logarithmic depth scaling, and advanced image augmentations, to provide a better understanding of the proposed framework. The accompanying source code is accessible at \url{https://github.com/PardisTaghavi/SwinMTL}.
Real-Time Semantic Segmentation using Hyperspectral Images for Mapping Unstructured and Unknown Environments
Mar 27, 2023



Autonomous navigation in unstructured off-road environments is greatly improved by semantic scene understanding. Conventional image processing algorithms are difficult to implement and lack robustness due to a lack of structure and high variability across off-road environments. The use of neural networks and machine learning can overcome the previous challenges but they require large labeled data sets for training. In our work we propose the use of hyperspectral images for real-time pixel-wise semantic classification and segmentation, without the need of any prior training data. The resulting segmented image is processed to extract, filter, and approximate objects as polygons, using a polygon approximation algorithm. The resulting polygons are then used to generate a semantic map of the environment. Using our framework. we show the capability to add new semantic classes in run-time for classification. The proposed methodology is also shown to operate in real-time and produce outputs at a frequency of 1Hz, using high resolution hyperspectral images.
Design, Modeling, and Evaluation of Separable Tendon-Driven Robotic Manipulator with Long, Passive, Flexible Proximal Section
Jan 01, 2023



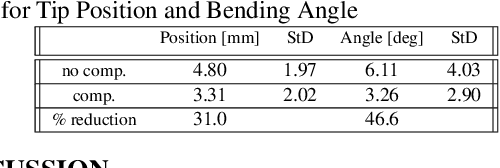
The purpose of this work was to tackle practical issues which arise when using a tendon-driven robotic manipulator with a long, passive, flexible proximal section in medical applications. A separable robot which overcomes difficulties in actuation and sterilization is introduced, in which the body containing the electronics is reusable and the remainder is disposable. A control input which resolves the redundancy in the kinematics and a physical interpretation of this redundancy are provided. The effect of a static change in the proximal section angle on bending angle error was explored under four testing conditions for a sinusoidal input. Bending angle error increased for increasing proximal section angle for all testing conditions with an average error reduction of 41.48% for retension, 4.28% for hysteresis, and 52.35% for re-tension + hysteresis compensation relative to the baseline case. Two major sources of error in tracking the bending angle were identified: time delay from hysteresis and DC offset from the proximal section angle. Examination of these error sources revealed that the simple hysteresis compensation was most effective for removing time delay and re-tension compensation for removing DC offset, which was the primary source of increasing error. The re-tension compensation was also tested for dynamic changes in the proximal section and reduced error in the final configuration of the tip by 89.14% relative to the baseline case.
Design and validation of zero-slack separable manipulator for Intracardiac Echocardiography
Apr 01, 2022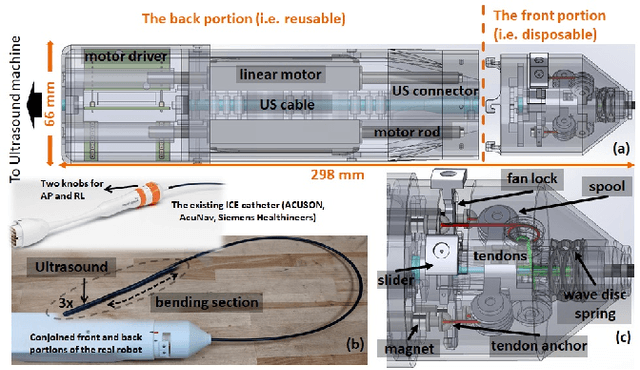
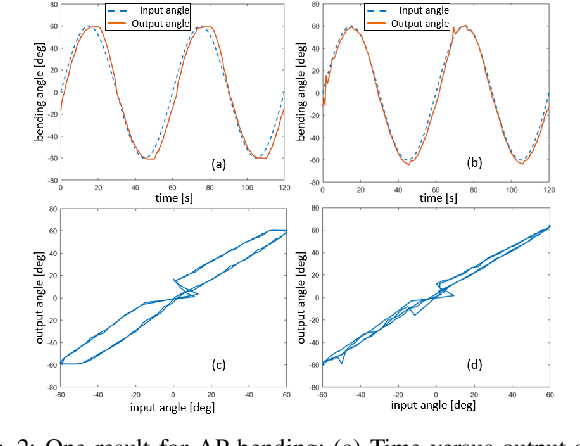
Clinicians require substantial training and experience to become comfortable with steering Intracardiac echocardiography (ICE) catheter to localize and measure the area of treatment to watch for complications while device catheters are deployed in another access. Thus, it is reasonable that a robotic-assist system to hold and actively manipulate the ICE catheter could ease the workload of the physician. Existing commercially-available robotic systems and research prototypes all use existing commercially available ICE catheters based on multiple tendon-sheath mechanism (TSM). To motorize the existing TSM-based ICE catheter, the actuators interface with the outer handle knobs to manipulate four internal tendons. However, in practice, the actuators are located at a sterile, safe place far away from the ICE handle. Thus, to interface with knobs, there exist multiple coupled gear structures between two, leading to a highly nonlinear behavior (e.g. various slack, elasticity) alongside hysteresis phenomena in TSM. Since ICE catheters are designed for single use, the expensive actuators need to be located in a safe place so as to be reusable. Moreover, these actuators should interface as directly as possible with the tendons for accurate tip controls. In this paper, we introduce a separable ICE catheter robot with four tendon actuation: one part reusable and another disposable. Moreover, we propose a practical model and calibration method for our proposed mechanism so that four tendons are actuated simultaneously allowing for precise tip control and mitigating issues with conventional devices such as dead-zone and hysteresis with simple linear compensation. We consider an open-loop controller since many available ICE catheters are used without position-tracking sensors at the tip due to costs and single use
A Computational Approach for Human-like Motion Generation in Upper Limb Exoskeletons Supporting Scapulohumeral Rhythms
Dec 19, 2017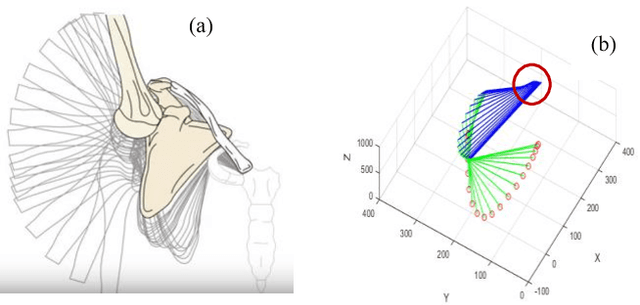
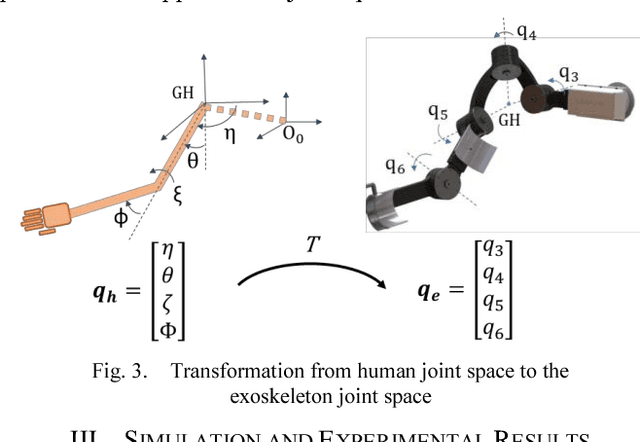
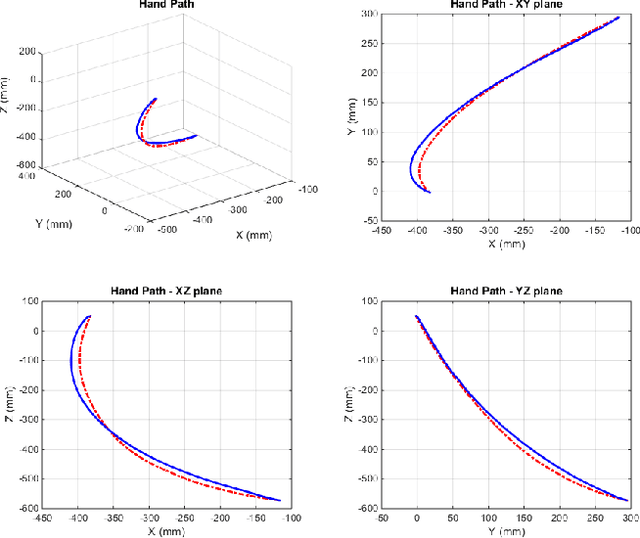
This paper proposes a computational approach for generation of reference path for upper-limb exoskeletons considering the scapulohumeral rhythms of the shoulder. The proposed method can be used in upper-limb exoskeletons with 3 Degrees of Freedom (DoF) in shoulder and 1 DoF in elbow, which are capable of supporting shoulder girdle. The developed computational method is based on Central Nervous System (CNS) governing rules. Existing computational reference generation methods are based on the assumption of fixed shoulder center during motions. This assumption can be considered valid for reaching movements with limited range of motion (RoM). However, most upper limb motions such as Activities of Daily Living (ADL) include large scale inward and outward reaching motions, during which the center of shoulder joint moves significantly. The proposed method generates the reference motion based on a simple model of human arm and a transformation can be used to map the developed motion for other exoskeleton with different kinematics. Comparison of the model outputs with experimental results of healthy subjects performing ADL, show that the proposed model is able to reproduce human-like motions.
Cleverarm: A Novel Exoskeleton For Rehabilitation Of Upper Limb Impairments
Dec 19, 2017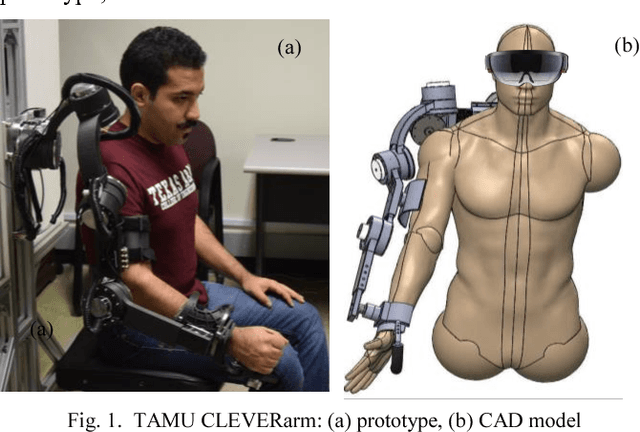
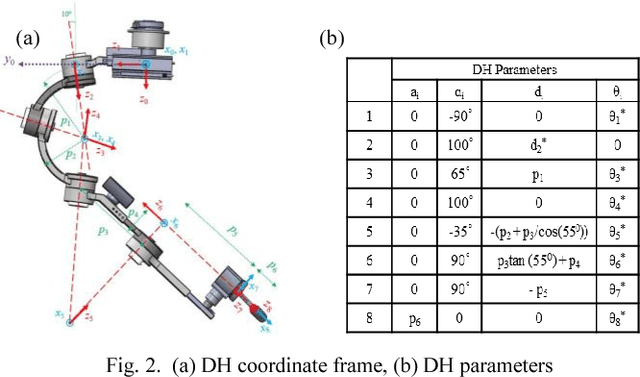
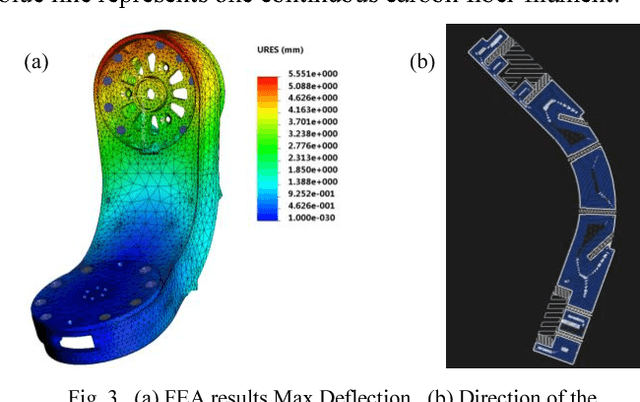
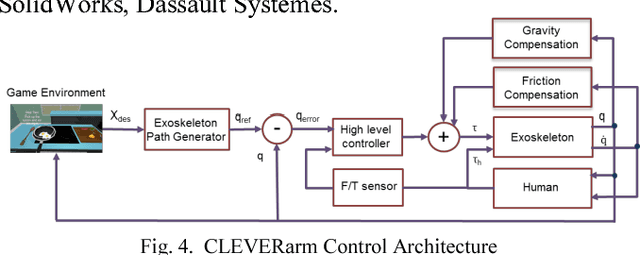
CLEVERarm (Compact, Low-weight, Ergonomic, Virtual and Augmented Reality Enhanced Rehabilitation arm) is a novel exoskeleton with eight degrees of freedom supporting the motion of shoulder girdle, glenohumeral joint, elbow and wrist. Of the eight degrees of freedom of the exoskeleton, six are active and the two degrees of freedom supporting the motion of wrist are passive. This paper briefly outlines the design of CLEVERarm and its control architectures.