 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Few-Shot Vision-Language Model Adaptation
Jun 05, 2025Pretrained VLMs achieve strong performance on downstream tasks when adapted with just a few labeled examples. As the adapted models inevitably encounter out-of-distribution (OOD) test data that deviates from the in-distribution (ID) task-specific training data, enhancing OOD generalization in few-shot adaptation is critically important. We study robust few-shot VLM adaptation, aiming to increase both ID and OOD accuracy. By comparing different adaptation methods (e.g., prompt tuning, linear probing, contrastive finetuning, and full finetuning), we uncover three key findings: (1) finetuning with proper hyperparameters significantly outperforms the popular VLM adaptation methods prompt tuning and linear probing; (2) visual encoder-only finetuning achieves better efficiency and accuracy than contrastively finetuning both visual and textual encoders; (3) finetuning the top layers of the visual encoder provides the best balance between ID and OOD accuracy. Building on these findings, we propose partial finetuning of the visual encoder empowered with two simple augmentation techniques: (1) retrieval augmentation which retrieves task-relevant data from the VLM's pretraining dataset to enhance adaptation, and (2) adversarial perturbation which promotes robustness during finetuning. Results show that the former/latter boosts OOD/ID accuracy while slightly sacrificing the ID/OOD accuracy. Yet, perhaps understandably, naively combining the two does not maintain their best OOD/ID accuracy. We address this dilemma with the developed SRAPF, Stage-wise Retrieval Augmentation-based Adversarial Partial Finetuning. SRAPF consists of two stages: (1) partial finetuning the visual encoder using both ID and retrieved data, and (2) adversarial partial finetuning with few-shot ID data. Extensive experiments demonstrate that SRAPF achieves the state-of-the-art ID and OOD accuracy on the ImageNet OOD benchmarks.
Towards Continual Egocentric Activity Recognition: A Multi-modal Egocentric Activity Dataset for Continual Learning
Jan 26, 2023



With the rapid development of wearable cameras, a massive collection of egocentric video for first-person visual perception becomes available. Using egocentric videos to predict first-person activity faces many challenges, including limited field of view, occlusions, and unstable motions. Observing that sensor data from wearable devices facilitates human activity recognition, multi-modal activity recognition is attracting increasing attention. However, the deficiency of related dataset hinders the development of multi-modal deep learning for egocentric activity recognition. Nowadays, deep learning in real world has led to a focus on continual learning that often suffers from catastrophic forgetting. But the catastrophic forgetting problem for egocentric activity recognition, especially in the context of multiple modalities, remains unexplored due to unavailability of dataset. In order to assist this research, we present a multi-modal egocentric activity dataset for continual learning named UESTC-MMEA-CL, which is collected by self-developed glasses integrating a first-person camera and wearable sensors. It contains synchronized data of videos, accelerometers, and gyroscopes, for 32 types of daily activities, performed by 10 participants. Its class types and scale are compared with other publicly available datasets. The statistical analysis of the sensor data is given to show the auxiliary effects for different behaviors. And results of egocentric activity recognition are reported when using separately, and jointly, three modalities: RGB, acceleration, and gyroscope, on a base network architecture. To explore the catastrophic forgetting in continual learning tasks, four baseline methods are extensively evaluated with different multi-modal combinations. We hope the UESTC-MMEA-CL can promote future studies on continual learning for first-person activity recognition in wearable applications.
A Review of 3D Face Reconstruction From a Single Image
Nov 06, 2021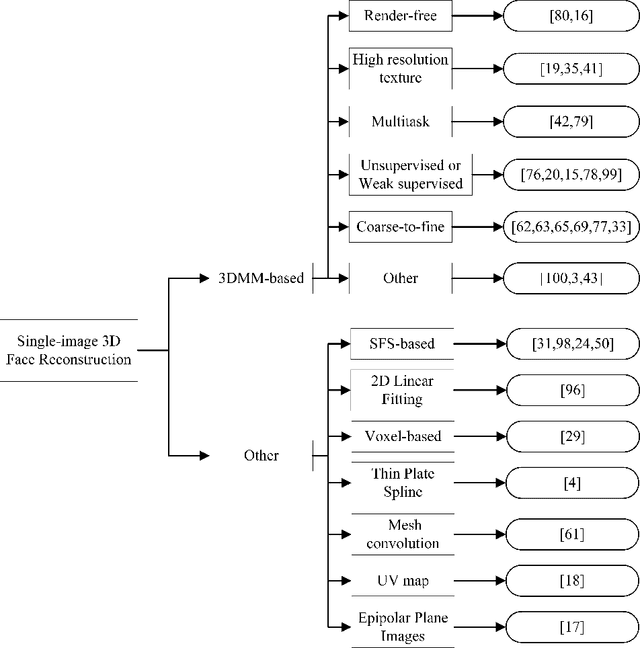
3D face reconstruction is a challenging problem but also an important task in the field of computer vision and graphics. Recently, many researchers put attention to the problem and a large number of articles have been published. Single image reconstruction is one of the branches of 3D face reconstruction, which has a lot of applications in our life. This paper is a review of the recent literature on 3D face reconstruction from a single image.