 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-SCEND: Test-time Scalable MCTS-enhanced Diffusion Model
Feb 04, 2025



We introduce Test-time Scalable MCTS-enhanced Diffusion Model (T-SCEND), a novel framework that significantly improves diffusion model's reasoning capabilities with better energy-based training and scaling up test-time computation. We first show that na\"ively scaling up inference budget for diffusion models yields marginal gain. To address this, the training of T-SCEND consists of a novel linear-regression negative contrastive learning objective to improve the performance-energy consistency of the energy landscape, and a KL regularization to reduce adversarial sampling. During inference, T-SCEND integrates the denoising process with a novel hybrid Monte Carlo Tree Search (hMCTS), which sequentially performs best-of-N random search and MCTS as denoising proceeds. On challenging reasoning tasks of Maze and Sudoku, we demonstrate the effectiveness of T-SCEND's training objective and scalable inference method. In particular, trained with Maze sizes of up to $6\times6$, our T-SCEND solves $88\%$ of Maze problems with much larger sizes of $15\times15$, while standard diffusion completely fails.Code to reproduce the experiments can be found at https://github.com/AI4Science-WestlakeU/t_scend.
Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization
Feb 03, 2025



Preference optimization for diffusion models aims to align them with human preferences for images. Previous methods typically leverage Vision-Language Models (VLMs) as pixel-level reward models to approximate human preferences. However, when used for step-level preference optimization, these models face challenges in handling noisy images of different timesteps and require complex transformations into pixel space. In this work, we demonstrate that diffusion models are inherently well-suited for step-level reward modeling in the latent space, as they can naturally extract features from noisy latent images. Accordingly, we propose the Latent Reward Model (LRM), which repurposes components of diffusion models to predict preferences of latent images at various timesteps. Building on LRM, we introduce Latent Preference Optimization (LPO), a method designed for step-level preference optimization directly in the latent space. Experimental results indicate that LPO not only significantly enhances performance in aligning diffusion models with general, aesthetic, and text-image alignment preferences, but also achieves 2.5-28$\times$ training speedup compared to existing preference optimization methods. Our code will be available at https://github.com/casiatao/LPO.
Ocean-OCR: Towards General OCR Application via a Vision-Language Model
Jan 26, 2025



Multimodal large language models (MLLMs) have shown impressive capabilities across various domains, excelling in processing and understanding information from multiple modalities. Despite the rapid progress made previously, insufficient OCR ability hinders MLLMs from excelling in text-related tasks. In this paper, we present \textbf{Ocean-OCR}, a 3B MLLM with state-of-the-art performance on various OCR scenarios and comparable understanding ability on general tasks. We employ Native Resolution ViT to enable variable resolution input and utilize a substantial collection of high-quality OCR datasets to enhance the model performance. We demonstrate the superiority of Ocean-OCR through comprehensive experiments on open-source OCR benchmarks and across various OCR scenarios. These scenarios encompass document understanding, scene text recognition, and handwritten recognition, highlighting the robust OCR capabilities of Ocean-OCR. Note that Ocean-OCR is the first MLLM to outperform professional OCR models such as TextIn and PaddleOCR.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Are They the Same? Exploring Visual Correspondence Shortcomings of Multimodal LLMs
Jan 08, 2025



Recent advancements in multimodal models have shown a strong ability in visual perception, reasoning abilities, and vision-language understanding. However, studies on visual matching ability are missing, where finding the visual correspondence of objects is essential in vision research. Our research reveals that the matching capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings, even with current strong MLLMs models, GPT-4o. In particular, we construct a Multimodal Visual Matching (MMVM) benchmark to fairly benchmark over 30 different MLLMs. The MMVM benchmark is built from 15 open-source datasets and Internet videos with manual annotation. We categorize the data samples of MMVM benchmark into eight aspects based on the required cues and capabilities to more comprehensively evaluate and analyze current MLLMs. In addition, we have designed an automatic annotation pipeline to generate the MMVM SFT dataset, including 220K visual matching data with reasoning annotation. Finally, we present CoLVA, a novel contrastive MLLM with two novel technical designs: fine-grained vision expert with object-level contrastive learning and instruction augmentation strategy. CoLVA achieves 51.06\% overall accuracy (OA) on the MMVM benchmark, surpassing GPT-4o and baseline by 8.41\% and 23.58\% OA, respectively. The results show the effectiveness of our MMVM SFT dataset and our novel technical designs. Code, benchmark, dataset, and models are available at https://github.com/zhouyiks/CoLVA.
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Jan 07, 2025



This work presents Sa2VA, the first unified model for dense grounded understanding of both images and videos. Unlike existing multi-modal large language models, which are often limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including referring segmentation and conversation, with minimal one-shot instruction tuning. Sa2VA combines SAM-2, a foundation video segmentation model, with LLaVA, an advanced vision-language model, and unifies text, image, and video into a shared LLM token space. Using the LLM, Sa2VA generates instruction tokens that guide SAM-2 in producing precise masks, enabling a grounded, multi-modal understanding of both static and dynamic visual content. Additionally, we introduce Ref-SAV, an auto-labeled dataset containing over 72k object expressions in complex video scenes, designed to boost model performance. We also manually validate 2k video objects in the Ref-SAV datasets to benchmark referring video object segmentation in complex environments. Experiments show that Sa2VA achieves state-of-the-art across multiple tasks, particularly in referring video object segmentation, highlighting its potential for complex real-world applications.
Generative Regression Based Watch Time Prediction for Video Recommendation: Model and Performance
Dec 28, 2024



Watch time prediction (WTP) has emerged as a pivotal task in short video recommendation systems, designed to encapsulate user interests. Predicting users' watch times on videos often encounters challenges, including wide value ranges and imbalanced data distributions, which can lead to significant bias when directly regressing watch time. Recent studies have tried to tackle these issues by converting the continuous watch time estimation into an ordinal classification task. While these methods are somewhat effective, they exhibit notable limitations. Inspired by language modeling, we propose a novel Generative Regression (GR) paradigm for WTP based on sequence generation. This approach employs structural discretization to enable the lossless reconstruction of original values while maintaining prediction fidelity. By formulating the prediction problem as a numerical-to-sequence mapping, and with meticulously designed vocabulary and label encodings, each watch time is transformed into a sequence of tokens. To expedite model training, we introduce the curriculum learning with an embedding mixup strategy which can mitigate training-and-inference inconsistency associated with teacher forcing. We evaluate our method against state-of-the-art approaches on four public datasets and one industrial dataset. We also perform online A/B testing on Kuaishou, a leading video app with about 400 million DAUs, to demonstrate the real-world efficacy of our method. The results conclusively show that GR outperforms existing techniques significantly. Furthermore, we successfully apply GR to another regression task in recommendation systems, i.e., Lifetime Value (LTV) prediction, which highlights its potential as a novel and effective solution to general regression challenges.
RAG-Star: Enhancing Deliberative Reasoning with Retrieval Augmented Verification and Refinement
Dec 17, 2024



Existing large language models (LLMs) show exceptional problem-solving capabilities but might struggle with complex reasoning tasks. Despite the successes of chain-of-thought and tree-based search methods, they mainly depend on the internal knowledge of LLMs to search over intermediate reasoning steps, limited to dealing with simple tasks involving fewer reasoning steps. In this paper, we propose \textbf{RAG-Star}, a novel RAG approach that integrates the retrieved information to guide the tree-based deliberative reasoning process that relies on the inherent knowledge of LLMs. By leveraging Monte Carlo Tree Search, RAG-Star iteratively plans intermediate sub-queries and answers for reasoning based on the LLM itself. To consolidate internal and external knowledge, we propose an retrieval-augmented verification that utilizes query- and answer-aware reward modeling to provide feedback for the inherent reasoning of LLMs. Our experiments involving Llama-3.1-8B-Instruct and GPT-4o demonstrate that RAG-Star significantly outperforms previous RAG and reasoning methods.
THESAURUS: Contrastive Graph Clustering by Swapping Fused Gromov-Wasserstein Couplings
Dec 16, 2024



Graph node clustering is a fundamental unsupervised task. Existing methods typically train an encoder through selfsupervised learning and then apply K-means to the encoder output. Some methods use this clustering result directly as the final assignment, while others initialize centroids based on this initial clustering and then finetune both the encoder and these learnable centroids. However, due to their reliance on K-means, these methods inherit its drawbacks when the cluster separability of encoder output is low, facing challenges from the Uniform Effect and Cluster Assimilation. We summarize three reasons for the low cluster separability in existing methods: (1) lack of contextual information prevents discrimination between similar nodes from different clusters; (2) training tasks are not sufficiently aligned with the downstream clustering task; (3) the cluster information in the graph structure is not appropriately exploited. To address these issues, we propose conTrastive grapH clustEring by SwApping fUsed gRomov-wasserstein coUplingS (THESAURUS). Our method introduces semantic prototypes to provide contextual information, and employs a cross-view assignment prediction pretext task that aligns well with the downstream clustering task. Additionally, it utilizes Gromov-Wasserstein Optimal Transport (GW-OT) along with the proposed prototype graph to thoroughly exploit cluster information in the graph structure. To adapt to diverse real-world data, THESAURUS updates the prototype graph and the prototype marginal distribution in OT by using momentum. Extensive experiments demonstrate that THESAURUS achieves higher cluster separability than the prior art, effectively mitigating the Uniform Effect and Cluster Assimilation issues
Wavelet Diffusion Neural Operator
Dec 06, 2024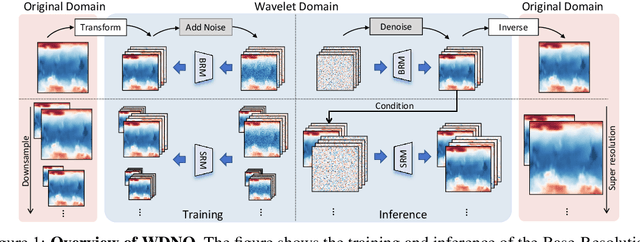
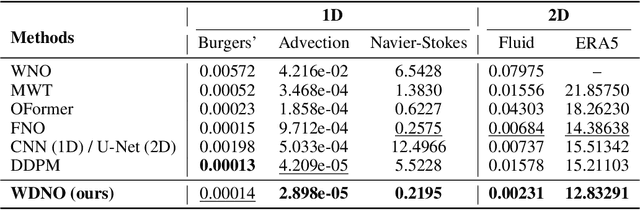
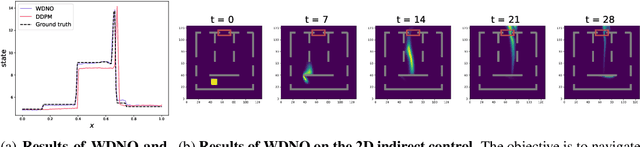
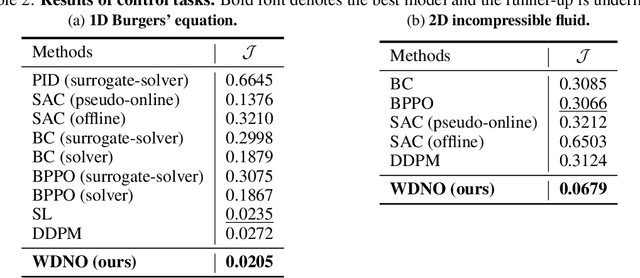
Simulating and controlling physical systems described by partial differential equations (PDEs) are crucial tasks across science and engineering. Recently, diffusion generative models have emerged as a competitive class of methods for these tasks due to their ability to capture long-term dependencies and model high-dimensional states. However, diffusion models typically struggle with handling system states with abrupt changes and generalizing to higher resolutions. In this work, we propose Wavelet Diffusion Neural Operator (WDNO), a novel PDE simulation and control framework that enhances the handling of these complexities. WDNO comprises two key innovations. Firstly, WDNO performs diffusion-based generative modeling in the wavelet domain for the entire trajectory to handle abrupt changes and long-term dependencies effectively. Secondly, to address the issue of poor generalization across different resolutions, which is one of the fundamental tasks in modeling physical systems, we introduce multi-resolution training. We validate WDNO on five physical systems, including 1D advection equation, three challenging physical systems with abrupt changes (1D Burgers' equation, 1D compressible Navier-Stokes equation and 2D incompressible fluid), and a real-world dataset ERA5, which demonstrates superior performance on both simulation and control tasks over state-of-the-art methods, with significant improvements in long-term and detail prediction accuracy. Remarkably, in the challenging context of the 2D high-dimensional and indirect control task aimed at reducing smoke leakage, WDNO reduces the leakage by 33.2% compared to the second-best baseline.