 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM^2C-EvDet: Multi-Domain Multi-Order Cross-Modal Knowledge Distillation for Event-based Object Detection
Jun 23, 2026Event-based object Detection (EvDet), as a biologically inspired visual perception paradigm, demonstrates superior performance in scenarios demanding high temporal resolution and a wide dynamic range. Nevertheless, the inherent sparse representations and inadequate visual semantics of event data result in a considerable performance disparity between EvDet and frame-based object detection. Previous works attempt to alleviate this cross-modal discrepancy through knowledge distillation, yet they only focus on spatial visual semantics or pair-wise relational information, thus limiting performance in more complex scenarios. To address this challenge, this paper proposes M^2C-EvDet, a Multi-domain and Multi-order Cross-modal knowledge distillation framework for EvDet. Built upon frequency learning and hypergraph computation, M^2C-EvDet integrates two specialized modules: Adaptive Frequency-Decoupled Feature Distillation (AF^2D^2) and Multi-Order Relational Distillation (MORD).
Count Anything
May 29, 2026Object counting remains fragmented across domain-specific datasets and task formulations, despite rapid progress in generalist vision models. Existing counting models are often tailored to scenarios such as crowds, vehicles, cells, crops, or remote-sensing objects, and thus struggle to generalize across categories, visual domains, object scales, and density distributions. In this paper, we study text-guided object counting across domains, where a model takes an image and a natural-language query as input and returns an instance-grounded set of target points whose cardinality gives the count. This formulation unifies category-conditioned counting with interpretable spatial localization. To support this setting, we construct CLOC, a Cross-domain Large-scale Object Counting dataset that reorganizes diverse public data sources into a unified benchmark. CLOC covers six visual domains: General Scene, Remote Sensing, Histopathology, Cellular Microscopy, Agriculture, and Microbiology, with about 220K images, 619 categories, and 15M object instances. Based on CLOC, we propose Count Anything, a generalist model for text-guided object counting. Unlike density-map-based methods, which dominate counting models, Count Anything adopts discrete instance points and performs dual-granularity instance enumeration. A Region-level Sparse Counter provides object-level anchors for large and sparse targets, while a Pixel-level Dense Counter handles small, crowded, and weakly bounded targets via dense point prediction. A point-centric supervision strategy enables learning from heterogeneous annotations, and Complementary Count Fusion combines both counters in a parameter-free manner. Extensive experiments show that Count Anything achieves strong accuracy and multi-domain generalization, outperforming existing open-world counting methods. Code is available at: https://github.com/Mengqi-Lei/count-anything.
RACANet: Reliability-Aware Crowd Anchor Network for RGB-T Crowd Counting
Apr 27, 2026RGB-Thermal (T) crowd counting aims to integrate visible-spectrum and thermal infrared information to improve the robustness of crowd density estimation in complex scenes. Although existing studies generally improve counting accuracy through cross-modal feature fusion, most current methods rely on implicit cross-modal fusion strategies and lack explicit modeling of local spatial discrepancies as well as fine-grained characterization of modality reliability at the positional level, thereby limiting the accuracy and interpretability of the fusion process. To address these issues, this paper proposes a two-stage fusion framework, RACANet, a Reliability-Aware Crowd Anchor Network for RGB-T crowd counting. First, we introduce a lightweight cross-modal alignment pretraining stage, which explicitly learns cross-modal semantic correspondences through crowd-prior supervision and local bidirectional soft matching. Then, based on the priors learned during pretraining, a Local Anchor Fusion Module (LAFM) is introduced in the formal training stage. This module generates local semantic anchors by aggregating features from highly reliable regions and further enables adaptive pixel-level feature redistribution with a local attention mechanism. In addition, we propose a discrepancy-aware consistency constraint to dynamically coordinate the reliability of regions where modal representations are consistent. Experiments conducted on two widely used benchmark datasets, RGBT-CC and Drone-RGBT, demonstrate that RACANet outperforms existing methods. The anonymous code is available at https://anonymous.4open.science/r/RACANet-9985.
Sparse Hypergraph-Enhanced Frame-Event Object Detection with Fine-Grained MoE
Apr 13, 2026Integrating frame-based RGB cameras with event streams offers a promising solution for robust object detection under challenging dynamic conditions. However, the inherent heterogeneity and data redundancy of these modalities often lead to prohibitive computational overhead or suboptimal feature fusion. In this paper, we propose Hyper-FEOD, a high-performance and efficient detection framework, which synergistically optimizes multi-modal interaction through two core components. First, we introduce Sparse Hypergraph-enhanced Cross-Modal Fusion (S-HCF), which leverages the inherent sparsity of event streams to construct an event-guided activity map. By performing high-order hypergraph modeling exclusively on selected motion-critical sparse tokens, S-HCF captures complex non-local dependencies between RGB and event data while overcoming the traditional complexity bottlenecks of hypergraph computation. Second, we design a Fine-Grained Mixture of Experts (FG-MoE) Enhancement module to address the diverse semantic requirements of different image regions. This module employs specialized hypergraph experts tailored for object boundaries, internal textures, and backgrounds, utilizing a pixel-level spatial gating mechanism to adaptively route and enhance features. Combined with a load-balancing loss and zero-initialization strategy, FG-MoE ensures stable training and precise feature refinement without disrupting the pre-trained backbone's distribution. Experimental results on mainstream RGB-Event benchmarks demonstrate that Hyper-FEOD achieves a superior accuracy-efficiency trade-off, outperforming state-of-the-art methods while maintaining a lightweight footprint suitable for real-time edge deployment.
FedVideoMAE: Efficient Privacy-Preserving Federated Video Moderation
Dec 21, 2025



The rapid growth of short-form video platforms increases the need for privacy-preserving moderation, as cloud-based pipelines expose raw videos to privacy risks, high bandwidth costs, and inference latency. To address these challenges, we propose an on-device federated learning framework for video violence detection that integrates self-supervised VideoMAE representations, LoRA-based parameter-efficient adaptation, and defense-in-depth privacy protection. Our approach reduces the trainable parameter count to 5.5M (~3.5% of a 156M backbone) and incorporates DP-SGD with configurable privacy budgets and secure aggregation. Experiments on RWF-2000 with 40 clients achieve 77.25% accuracy without privacy protection and 65-66% under strong differential privacy, while reducing communication cost by $28.3\times$ compared to full-model federated learning. The code is available at: {https://github.com/zyt-599/FedVideoMAE}
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
May 21, 2025
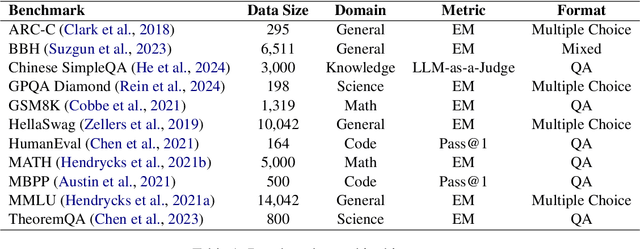
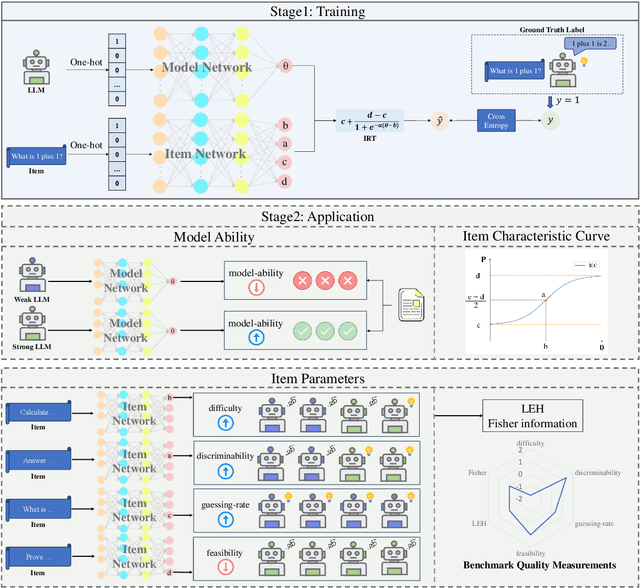

The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining main-stream prominent LLM benchmarks using results from diverse models. We first propose a new framework for accurate and reliable estimations of item characteristics and model abilities. Specifically, we propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. Based on PSN-IRT, we conduct extensive analysis which reveals significant and varied shortcomings in the measurement quality of current benchmarks. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.
Federated PCA on Grassmann Manifold for IoT Anomaly Detection
Jul 10, 2024



With the proliferation of the Internet of Things (IoT) and the rising interconnectedness of devices, network security faces significant challenges, especially from anomalous activities. While traditional machine learning-based intrusion detection systems (ML-IDS) effectively employ supervised learning methods, they possess limitations such as the requirement for labeled data and challenges with high dimensionality. Recent unsupervised ML-IDS approaches such as AutoEncoders and Generative Adversarial Networks (GAN) offer alternative solutions but pose challenges in deployment onto resource-constrained IoT devices and in interpretability. To address these concerns, this paper proposes a novel federated unsupervised anomaly detection framework, FedPCA, that leverages Principal Component Analysis (PCA) and the Alternating Directions Method Multipliers (ADMM) to learn common representations of distributed non-i.i.d. datasets. Building on the FedPCA framework, we propose two algorithms, FEDPE in Euclidean space and FEDPG on Grassmann manifolds. Our approach enables real-time threat detection and mitigation at the device level, enhancing network resilience while ensuring privacy. Moreover, the proposed algorithms are accompanied by theoretical convergence rates even under a subsampling scheme, a novel result. Experimental results on the UNSW-NB15 and TON-IoT datasets show that our proposed methods offer performance in anomaly detection comparable to nonlinear baselines, while providing significant improvements in communication and memory efficiency, underscoring their potential for securing IoT networks.
* Accepted for publication at IEEE/ACM Transactions on Networking
Search Intenion Network for Personalized Query Auto-Completion in E-Commerce
Mar 05, 2024



Query Auto-Completion(QAC), as an important part of the modern search engine, plays a key role in complementing user queries and helping them refine their search intentions.Today's QAC systems in real-world scenarios face two major challenges:1)intention equivocality(IE): during the user's typing process,the prefix often contains a combination of characters and subwords, which makes the current intention ambiguous and difficult to model.2)intention transfer (IT):previous works make personalized recommendations based on users' historical sequences, but ignore the search intention transfer.However, the current intention extracted from prefix may be contrary to the historical preferences.
Bridging the Gap: Fine-to-Coarse Sketch Interpolation Network for High-Quality Animation Sketch Inbetweening
Aug 25, 2023The 2D animation workflow is typically initiated with the creation of keyframes using sketch-based drawing. Subsequent inbetweens (i.e., intermediate sketch frames) are crafted through manual interpolation for smooth animations, which is a labor-intensive process. Thus, the prospect of automatic animation sketch interpolation has become highly appealing. However, existing video interpolation methods are generally hindered by two key issues for sketch inbetweening: 1) limited texture and colour details in sketches, and 2) exaggerated alterations between two sketch keyframes. To overcome these issues, we propose a novel deep learning method, namely Fine-to-Coarse Sketch Interpolation Network (FC-SIN). This approach incorporates multi-level guidance that formulates region-level correspondence, sketch-level correspondence and pixel-level dynamics. A multi-stream U-Transformer is then devised to characterize sketch inbewteening patterns using these multi-level guides through the integration of both self-attention and cross-attention mechanisms. Additionally, to facilitate future research on animation sketch inbetweening, we constructed a large-scale dataset - STD-12K, comprising 30 sketch animation series in diverse artistic styles. Comprehensive experiments on this dataset convincingly show that our proposed FC-SIN surpasses the state-of-the-art interpolation methods. Our code and dataset will be publicly available.
Handling Heavy Occlusion in Dense Crowd Tracking by Focusing on the Heads
Apr 27, 2023



With the rapid development of deep learning, object detection and tracking play a vital role in today's society. Being able to identify and track all the pedestrians in the dense crowd scene with computer vision approaches is a typical challenge in this field, also known as the Multiple Object Tracking (MOT) challenge. Modern trackers are required to operate on more and more complicated scenes. According to the MOT20 challenge result, the pedestrian is 4 times denser than the MOT17 challenge. Hence, improving the ability to detect and track in extremely crowded scenes is the aim of this work. In light of the occlusion issue with the human body, the heads are usually easier to identify. In this work, we have designed a joint head and body detector in an anchor-free style to boost the detection recall and precision performance of pedestrians in both small and medium sizes. Innovatively, our model does not require information on the statistical head-body ratio for common pedestrians detection for training. Instead, the proposed model learns the ratio dynamically. To verify the effectiveness of the proposed model, we evaluate the model with extensive experiments on different datasets, including MOT20, Crowdhuman, and HT21 datasets. As a result, our proposed method significantly improves both the recall and precision rate on small & medium sized pedestrians and achieves state-of-the-art results in these challenging datasets.