 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus-Steered Query Expansion with Large Language Models
Feb 28, 2024



Recent studies demonstrate that query expansions generated by large language models (LLMs) can considerably enhance information retrieval systems by generating hypothetical documents that answer the queries as expansions. However, challenges arise from misalignments between the expansions and the retrieval corpus, resulting in issues like hallucinations and outdated information due to the limited intrinsic knowledge of LLMs. Inspired by Pseudo Relevance Feedback (PRF), we introduce Corpus-Steered Query Expansion (CSQE) to promote the incorporation of knowledge embedded within the corpus. CSQE utilizes the relevance assessing capability of LLMs to systematically identify pivotal sentences in the initially-retrieved documents. These corpus-originated texts are subsequently used to expand the query together with LLM-knowledge empowered expansions, improving the relevance prediction between the query and the target documents. Extensive experiments reveal that CSQE exhibits strong performance without necessitating any training, especially with queries for which LLMs lack knowledge.
A Survey on Knowledge Distillation of Large Language Models
Feb 23, 2024



In the era of Large Language Models (LLMs), Knowledge Distillation (KD) emerges as a pivotal methodology for transferring advanced capabilities from leading proprietary LLMs, such as GPT-4, to their open-source counterparts like LLaMA and Mistral. Additionally, as open-source LLMs flourish, KD plays a crucial role in both compressing these models, and facilitating their self-improvement by employing themselves as teachers. This paper presents a comprehensive survey of KD's role within the realm of LLM, highlighting its critical function in imparting advanced knowledge to smaller models and its utility in model compression and self-improvement. Our survey is meticulously structured around three foundational pillars: \textit{algorithm}, \textit{skill}, and \textit{verticalization} -- providing a comprehensive examination of KD mechanisms, the enhancement of specific cognitive abilities, and their practical implications across diverse fields. Crucially, the survey navigates the intricate interplay between data augmentation (DA) and KD, illustrating how DA emerges as a powerful paradigm within the KD framework to bolster LLMs' performance. By leveraging DA to generate context-rich, skill-specific training data, KD transcends traditional boundaries, enabling open-source models to approximate the contextual adeptness, ethical alignment, and deep semantic insights characteristic of their proprietary counterparts. This work aims to provide an insightful guide for researchers and practitioners, offering a detailed overview of current methodologies in KD and proposing future research directions. Importantly, we firmly advocate for compliance with the legal terms that regulate the use of LLMs, ensuring ethical and lawful application of KD of LLMs. An associated Github repository is available at https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs.
Model Tailor: Mitigating Catastrophic Forgetting in Multi-modal Large Language Models
Feb 19, 2024



Catastrophic forgetting emerges as a critical challenge when fine-tuning multi-modal large language models (MLLMs), where improving performance on unseen tasks often leads to a significant performance drop on the original tasks. This paper presents a comprehensive analysis of catastrophic forgetting in MLLMs and introduces a post-training adjustment method called Model Tailor. Our method primarily preserves the pre-trained parameters while replacing a small number ($\leq$ 10\%) of fine-tuned parameters, maintaining $\sim$ 99\% effectiveness on original tasks versus pre-training, and achieving $\sim$ 97\% on new tasks compared to standard fine-tuning. Specifically, we derive a sparse mask to identify the "model patch", based on a fusion strategy that integrates salience and sensitivity analysis. Subsequently, a compensation mechanism is introduced to "decorate the patch", enhancing the model's performance on both target and original tasks. Additionally, our method is adaptable to multi-task scenarios. Through extensive experiments on InstructBLIP and LLaVA-1.5 in both image captioning and visual question answering tasks, our approach demonstrates significant task adaptability while preserving inherent pre-trained capabilities.
Rethinking Human-like Translation Strategy: Integrating Drift-Diffusion Model with Large Language Models for Machine Translation
Feb 16, 2024



Large language models (LLMs) have demonstrated promising potential in various downstream tasks, including machine translation. However, prior work on LLM-based machine translation has mainly focused on better utilizing training data, demonstrations, or pre-defined and universal knowledge to improve performance, with a lack of consideration of decision-making like human translators. In this paper, we incorporate Thinker with the Drift-Diffusion Model (Thinker-DDM) to address this issue. We then redefine the Drift-Diffusion process to emulate human translators' dynamic decision-making under constrained resources. We conduct extensive experiments under the high-resource, low-resource, and commonsense translation settings using the WMT22 and CommonMT datasets, in which Thinker-DDM outperforms baselines in the first two scenarios. We also perform additional analysis and evaluation on commonsense translation to illustrate the high effectiveness and efficacy of the proposed method.
Training-time Neuron Alignment through Permutation Subspace for Improving Linear Mode Connectivity and Model Fusion
Feb 02, 2024


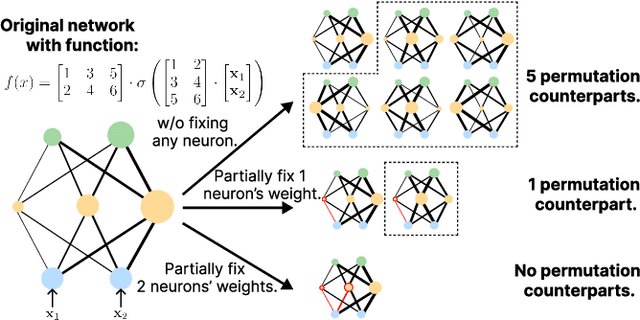
In deep learning, stochastic gradient descent often yields functionally similar yet widely scattered solutions in the weight space even under the same initialization, causing barriers in the Linear Mode Connectivity (LMC) landscape. Overcoming these barriers is crucial for understanding deep learning dynamics and enhancing model-fusion algorithms. Previous studies highlight the role of permutation symmetry in reducing post-training barriers through network permutation. However, these post-hoc methods, demanding extra computations, are less effective for larger, complex models (e.g., ViT, LLM) due to numerous permutation matrices. Thus, in this paper, we study training-time neuron alignment. Our hypothesis suggests that training-time permutation subspace can reduce LMC barriers for free. We find that pruning at initialization supports this. Beyond pruning, we introduce TNA-PFN, a simple yet lossless algorithm using a partial gradient mask during training. TNA-PFN is theoretically and empirically validated for reducing LMC barriers. It excels in wide model fusion applications, especially in federated learning, two algorithms based on TNA-FPN that are proposed to show its prospects even under heterogeneous datasets. Moreover, TNA-PFN can enhance the generalization of model soup for vision transformers and ColD fusion for pretrained language models.
Leveraging Large Language Models for NLG Evaluation: A Survey
Jan 13, 2024



In the rapidly evolving domain of Natural Language Generation (NLG) evaluation, introducing Large Language Models (LLMs) has opened new avenues for assessing generated content quality, e.g., coherence, creativity, and context relevance. This survey aims to provide a thorough overview of leveraging LLMs for NLG evaluation, a burgeoning area that lacks a systematic analysis. We propose a coherent taxonomy for organizing existing LLM-based evaluation metrics, offering a structured framework to understand and compare these methods. Our detailed exploration includes critically assessing various LLM-based methodologies, as well as comparing their strengths and limitations in evaluating NLG outputs. By discussing unresolved challenges, including bias, robustness, domain-specificity, and unified evaluation, this survey seeks to offer insights to researchers and advocate for fairer and more advanced NLG evaluation techniques.
Good Questions Help Zero-Shot Image Reasoning
Dec 04, 2023



Aligning the recent large language models (LLMs) with computer vision models leads to large vision-language models (LVLMs), which have paved the way for zero-shot image reasoning tasks. However, LVLMs are usually trained on short high-level captions only referring to sparse focus regions in images. Such a ``tunnel vision'' limits LVLMs to exploring other relevant contexts in complex scenes. To address this challenge, we introduce Question-Driven Visual Exploration (QVix), a novel prompting strategy that enhances the exploratory capabilities of LVLMs in zero-shot reasoning tasks. QVix leverages LLMs' strong language prior to generate input-exploratory questions with more details than the original query, guiding LVLMs to explore visual content more comprehensively and uncover subtle or peripheral details. QVix enables a wider exploration of visual scenes, improving the LVLMs' reasoning accuracy and depth in tasks such as visual question answering and visual entailment. Our evaluations on various challenging zero-shot vision-language benchmarks, including ScienceQA and fine-grained visual classification, demonstrate that QVix significantly outperforms existing methods, highlighting its effectiveness in bridging the gap between complex visual data and LVLMs' exploratory abilities.
Thread of Thought Unraveling Chaotic Contexts
Nov 15, 2023



Large Language Models (LLMs) have ushered in a transformative era in the field of natural language processing, excelling in tasks related to text comprehension and generation. Nevertheless, they encounter difficulties when confronted with chaotic contexts (e.g., distractors rather than long irrelevant context), leading to the inadvertent omission of certain details within the chaotic context. In response to these challenges, we introduce the "Thread of Thought" (ThoT) strategy, which draws inspiration from human cognitive processes. ThoT systematically segments and analyzes extended contexts while adeptly selecting pertinent information. This strategy serves as a versatile "plug-and-play" module, seamlessly integrating with various LLMs and prompting techniques. In the experiments, we utilize the PopQA and EntityQ datasets, as well as a Multi-Turn Conversation Response dataset (MTCR) we collected, to illustrate that ThoT significantly improves reasoning performance compared to other prompting techniques.
Enhancing Secrecy Capacity in PLS Communication with NORAN based on Pilot Information Codebooks
Oct 02, 2023



In recent research, non-orthogonal artificial noise (NORAN) has been proposed as an alternative to orthogonal artificial noise (AN). However, NORAN introduces additional noise into the channel, which reduces the capacity of the legitimate channel (LC). At the same time, selecting a NORAN design with ideal security performance from a large number of design options is also a challenging problem. To address these two issues, a novel NORAN based on a pilot information codebook is proposed in this letter. The codebook associates different suboptimal NORANs with pilot information as the key under different channel state information (CSI). The receiver interrogates the codebook using the pilot information to obtain the NORAN that the transmitter will transmit in the next moment, in order to eliminate the NORAN when receiving information. Therefore, NORAN based on pilot information codebooks can improve the secrecy capacity (SC) of the communication system by directly using suboptimal NORAN design schemes without increasing the noise in the LC. Numerical simulations and analyses show that the introduction of NORAN with a novel design using pilot information codebooks significantly enhances the security and improves the SC of the communication system.
Re-Reading Improves Reasoning in Language Models
Sep 12, 2023Reasoning presents a significant and challenging issue for Large Language Models (LLMs). The predominant focus of research has revolved around developing diverse prompting strategies to guide and structure the reasoning processes of LLMs. However, these approaches based on decoder-only causal language models often operate the input question in a single forward pass, potentially missing the rich, back-and-forth interactions inherent in human reasoning. Scant attention has been paid to a critical dimension, i.e., the input question itself embedded within the prompts. In response, we introduce a deceptively simple yet highly effective prompting strategy, termed question "re-reading". Drawing inspiration from human learning and problem-solving, re-reading entails revisiting the question information embedded within input prompts. This approach aligns seamlessly with the cognitive principle of reinforcement, enabling LLMs to extract deeper insights, identify intricate patterns, establish more nuanced connections, and ultimately enhance their reasoning capabilities across various tasks. Experiments conducted on a series of reasoning benchmarks serve to underscore the effectiveness and generality of our method. Moreover, our findings demonstrate that our approach seamlessly integrates with various language models, though-eliciting prompting methods, and ensemble techniques, further underscoring its versatility and compatibility in the realm of LLMs.