 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Tailor: Mitigating Catastrophic Forgetting in Multi-modal Large Language Models
Feb 19, 2024



Catastrophic forgetting emerges as a critical challenge when fine-tuning multi-modal large language models (MLLMs), where improving performance on unseen tasks often leads to a significant performance drop on the original tasks. This paper presents a comprehensive analysis of catastrophic forgetting in MLLMs and introduces a post-training adjustment method called Model Tailor. Our method primarily preserves the pre-trained parameters while replacing a small number ($\leq$ 10\%) of fine-tuned parameters, maintaining $\sim$ 99\% effectiveness on original tasks versus pre-training, and achieving $\sim$ 97\% on new tasks compared to standard fine-tuning. Specifically, we derive a sparse mask to identify the "model patch", based on a fusion strategy that integrates salience and sensitivity analysis. Subsequently, a compensation mechanism is introduced to "decorate the patch", enhancing the model's performance on both target and original tasks. Additionally, our method is adaptable to multi-task scenarios. Through extensive experiments on InstructBLIP and LLaVA-1.5 in both image captioning and visual question answering tasks, our approach demonstrates significant task adaptability while preserving inherent pre-trained capabilities.
Combining Past, Present and Future: A Self-Supervised Approach for Class Incremental Learning
Nov 15, 2023Class Incremental Learning (CIL) aims to handle the scenario where data of novel classes occur continuously and sequentially. The model should recognize the sequential novel classes while alleviating the catastrophic forgetting. In the self-supervised manner, it becomes more challenging to avoid the conflict between the feature embedding spaces of novel classes and old ones without any class labels. To address the problem, we propose a self-supervised CIL framework CPPF, meaning Combining Past, Present and Future. In detail, CPPF consists of a prototype clustering module (PC), an embedding space reserving module (ESR) and a multi-teacher distillation module (MTD). 1) The PC and the ESR modules reserve embedding space for subsequent phases at the prototype level and the feature level respectively to prepare for knowledge learned in the future. 2) The MTD module maintains the representations of the current phase without the interference of past knowledge. One of the teacher networks retains the representations of the past phases, and the other teacher network distills relation information of the current phase to the student network. Extensive experiments on CIFAR100 and ImageNet100 datasets demonstrate that our proposed method boosts the performance of self-supervised class incremental learning. We will release code in the near future.
Learning Distinctive Margin toward Active Domain Adaptation
Apr 03, 2022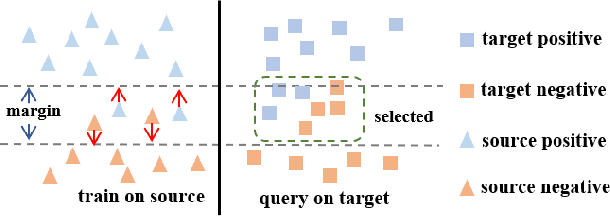
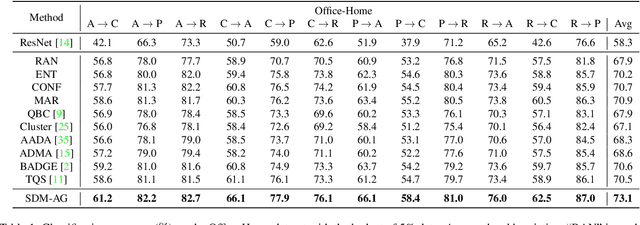
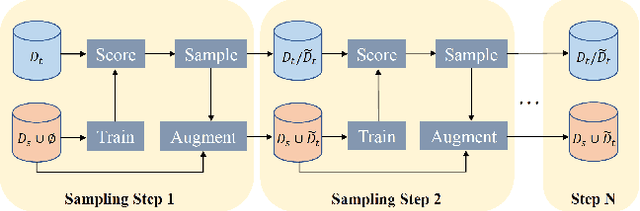
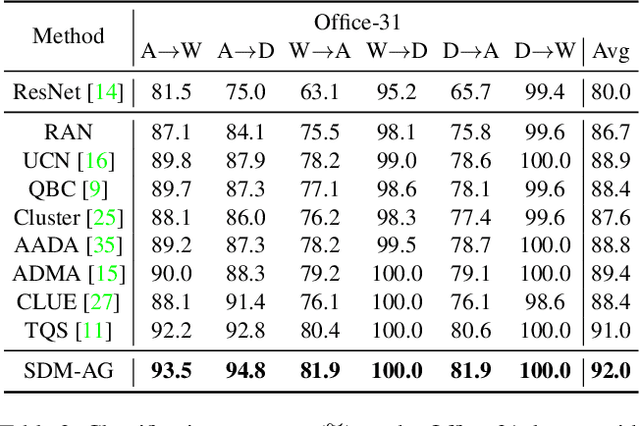
Despite plenty of efforts focusing on improving the domain adaptation ability (DA) under unsupervised or few-shot semi-supervised settings, recently the solution of active learning started to attract more attention due to its suitability in transferring model in a more practical way with limited annotation resource on target data. Nevertheless, most active learning methods are not inherently designed to handle domain gap between data distribution, on the other hand, some active domain adaptation methods (ADA) usually requires complicated query functions, which is vulnerable to overfitting. In this work, we propose a concise but effective ADA method called Select-by-Distinctive-Margin (SDM), which consists of a maximum margin loss and a margin sampling algorithm for data selection. We provide theoretical analysis to show that SDM works like a Support Vector Machine, storing hard examples around decision boundaries and exploiting them to find informative and transferable data. In addition, we propose two variants of our method, one is designed to adaptively adjust the gradient from margin loss, the other boosts the selectivity of margin sampling by taking the gradient direction into account. We benchmark SDM with standard active learning setting, demonstrating our algorithm achieves competitive results with good data scalability. Code is available at https://github.com/TencentYoutuResearch/ActiveLearning-SDM