 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Visual Knowledge Forgetting in MLLM Instruction-tuning via Modality-decoupled Gradient Descent
Feb 17, 2025



Recent MLLMs have shown emerging visual understanding and reasoning abilities after being pre-trained on large-scale multimodal datasets. Unlike pre-training, where MLLMs receive rich visual-text alignment, instruction-tuning is often text-driven with weaker visual supervision, leading to the degradation of pre-trained visual understanding and causing visual forgetting. Existing approaches, such as direct fine-tuning and continual learning methods, fail to explicitly address this issue, often compressing visual representations and prioritizing task alignment over visual retention, which further worsens visual forgetting. To overcome this limitation, we introduce a novel perspective leveraging effective rank to quantify the degradation of visual representation richness, interpreting this degradation through the information bottleneck principle as excessive compression that leads to the degradation of crucial pre-trained visual knowledge. Building on this view, we propose a modality-decoupled gradient descent (MDGD) method that regulates gradient updates to maintain the effective rank of visual representations while mitigating the over-compression effects described by the information bottleneck. By explicitly disentangling the optimization of visual understanding from task-specific alignment, MDGD preserves pre-trained visual knowledge while enabling efficient task adaptation. To enable lightweight instruction-tuning, we further develop a memory-efficient fine-tuning approach using gradient masking, which selectively updates a subset of model parameters to enable parameter-efficient fine-tuning (PEFT), reducing computational overhead while preserving rich visual representations. Extensive experiments across various downstream tasks and backbone MLLMs demonstrate that MDGD effectively mitigates visual forgetting from pre-trained tasks while enabling strong adaptation to new tasks.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
Interactive Visualization Recommendation with Hier-SUCB
Feb 06, 2025Visualization recommendation aims to enable rapid visual analysis of massive datasets. In real-world scenarios, it is essential to quickly gather and comprehend user preferences to cover users from diverse backgrounds, including varying skill levels and analytical tasks. Previous approaches to personalized visualization recommendations are non-interactive and rely on initial user data for new users. As a result, these models cannot effectively explore options or adapt to real-time feedback. To address this limitation, we propose an interactive personalized visualization recommendation (PVisRec) system that learns on user feedback from previous interactions. For more interactive and accurate recommendations, we propose Hier-SUCB, a contextual combinatorial semi-bandit in the PVisRec setting. Theoretically, we show an improved overall regret bound with the same rank of time but an improved rank of action space. We further demonstrate the effectiveness of Hier-SUCB through extensive experiments where it is comparable to offline methods and outperforms other bandit algorithms in the setting of visualization recommendation.
Do Large Multimodal Models Solve Caption Generation for Scientific Figures? Lessons Learned from SCICAP Challenge 2023
Jan 31, 2025



Since the SCICAP datasets launch in 2021, the research community has made significant progress in generating captions for scientific figures in scholarly articles. In 2023, the first SCICAP Challenge took place, inviting global teams to use an expanded SCICAP dataset to develop models for captioning diverse figure types across various academic fields. At the same time, text generation models advanced quickly, with many powerful pre-trained large multimodal models (LMMs) emerging that showed impressive capabilities in various vision-and-language tasks. This paper presents an overview of the first SCICAP Challenge and details the performance of various models on its data, capturing a snapshot of the fields state. We found that professional editors overwhelmingly preferred figure captions generated by GPT-4V over those from all other models and even the original captions written by authors. Following this key finding, we conducted detailed analyses to answer this question: Have advanced LMMs solved the task of generating captions for scientific figures?
Understanding How Paper Writers Use AI-Generated Captions in Figure Caption Writing
Jan 10, 2025Figures and their captions play a key role in scientific publications. However, despite their importance, many captions in published papers are poorly crafted, largely due to a lack of attention by paper authors. While prior AI research has explored caption generation, it has mainly focused on reader-centered use cases, where users evaluate generated captions rather than actively integrating them into their writing. This paper addresses this gap by investigating how paper authors incorporate AI-generated captions into their writing process through a user study involving 18 participants. Each participant rewrote captions for two figures from their own recently published work, using captions generated by state-of-the-art AI models as a resource. By analyzing video recordings of the writing process through interaction analysis, we observed that participants often began by copying and refining AI-generated captions. Paper writers favored longer, detail-rich captions that integrated textual and visual elements but found current AI models less effective for complex figures. These findings highlight the nuanced and diverse nature of figure caption composition, revealing design opportunities for AI systems to better support the challenges of academic writing.
Multi-LLM Collaborative Caption Generation in Scientific Documents
Jan 05, 2025



Scientific figure captioning is a complex task that requires generating contextually appropriate descriptions of visual content. However, existing methods often fall short by utilizing incomplete information, treating the task solely as either an image-to-text or text summarization problem. This limitation hinders the generation of high-quality captions that fully capture the necessary details. Moreover, existing data sourced from arXiv papers contain low-quality captions, posing significant challenges for training large language models (LLMs). In this paper, we introduce a framework called Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address these challenges by leveraging specialized LLMs for distinct sub-tasks. Our approach unfolds in three key modules: (Quality Assessment) We utilize multimodal LLMs to assess the quality of training data, enabling the filtration of low-quality captions. (Diverse Caption Generation) We then employ a strategy of fine-tuning/prompting multiple LLMs on the captioning task to generate candidate captions. (Judgment) Lastly, we prompt a prominent LLM to select the highest quality caption from the candidates, followed by refining any remaining inaccuracies. Human evaluations demonstrate that informative captions produced by our approach rank better than human-written captions, highlighting its effectiveness. Our code is available at https://github.com/teamreboott/MLBCAP
GUI Agents: A Survey
Dec 18, 2024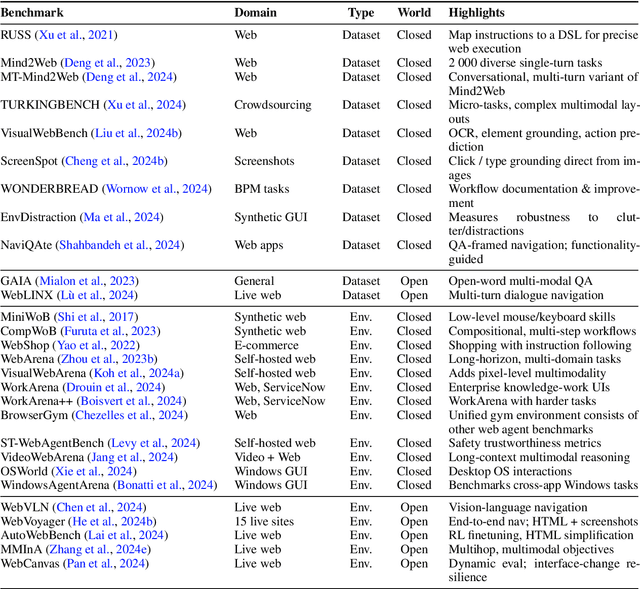
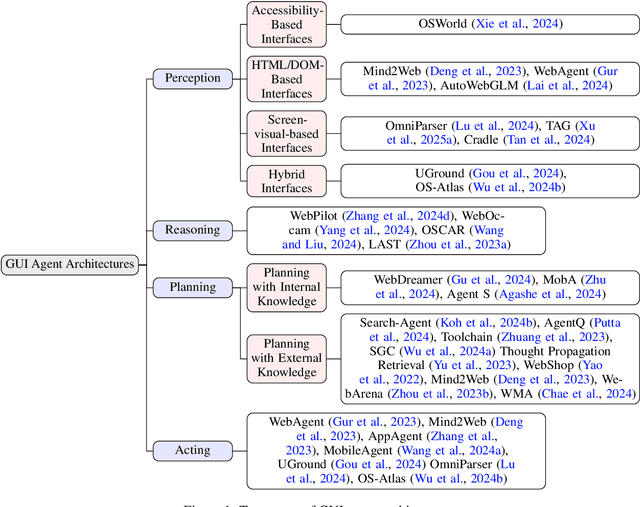

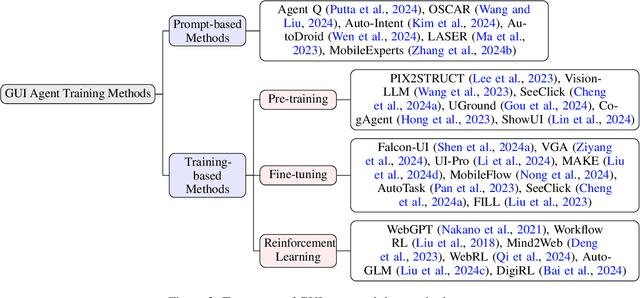
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
Personalized Multimodal Large Language Models: A Survey
Dec 03, 2024Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy. This paper presents a comprehensive survey on personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users, and discuss the techniques accordingly. Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used. Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.
Optimizing Data Delivery: Insights from User Preferences on Visuals, Tables, and Text
Nov 12, 2024In this work, we research user preferences to see a chart, table, or text given a question asked by the user. This enables us to understand when it is best to show a chart, table, or text to the user for the specific question. For this, we conduct a user study where users are shown a question and asked what they would prefer to see and used the data to establish that a user's personal traits does influence the data outputs that they prefer. Understanding how user characteristics impact a user's preferences is critical to creating data tools with a better user experience. Additionally, we investigate to what degree an LLM can be used to replicate a user's preference with and without user preference data. Overall, these findings have significant implications pertaining to the development of data tools and the replication of human preferences using LLMs. Furthermore, this work demonstrates the potential use of LLMs to replicate user preference data which has major implications for future user modeling and personalization research.
Personalization of Large Language Models: A Survey
Oct 29, 2024Personalization of Large Language Models (LLMs) has recently become increasingly important with a wide range of applications. Despite the importance and recent progress, most existing works on personalized LLMs have focused either entirely on (a) personalized text generation or (b) leveraging LLMs for personalization-related downstream applications, such as recommendation systems. In this work, we bridge the gap between these two separate main directions for the first time by introducing a taxonomy for personalized LLM usage and summarizing the key differences and challenges. We provide a formalization of the foundations of personalized LLMs that consolidates and expands notions of personalization of LLMs, defining and discussing novel facets of personalization, usage, and desiderata of personalized LLMs. We then unify the literature across these diverse fields and usage scenarios by proposing systematic taxonomies for the granularity of personalization, personalization techniques, datasets, evaluation methods, and applications of personalized LLMs. Finally, we highlight challenges and important open problems that remain to be addressed. By unifying and surveying recent research using the proposed taxonomies, we aim to provide a clear guide to the existing literature and different facets of personalization in LLMs, empowering both researchers and practitioners.