 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransMix: Attend to Mix for Vision Transformers
Nov 18, 2021
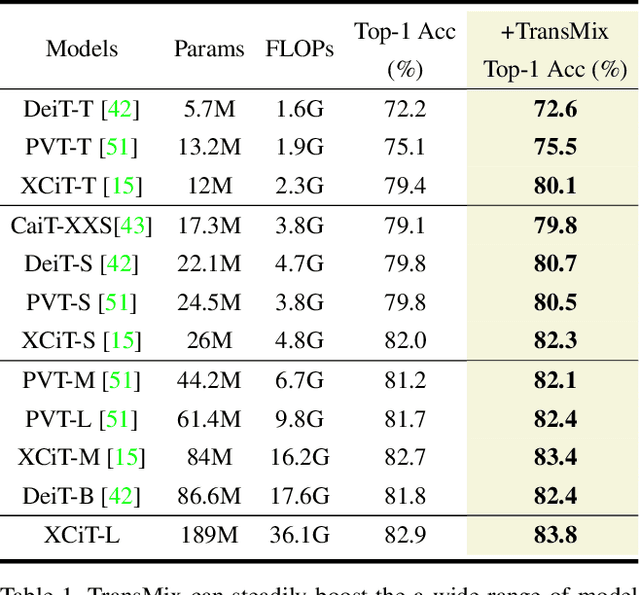
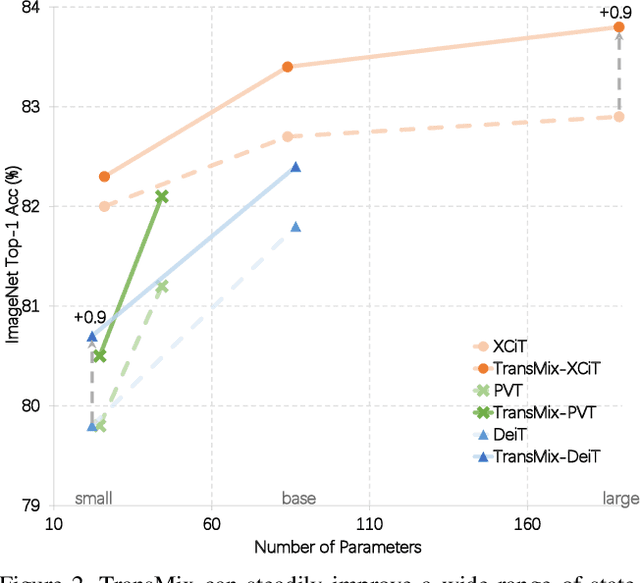

Mixup-based augmentation has been found to be effective for generalizing models during training, especially for Vision Transformers (ViTs) since they can easily overfit. However, previous mixup-based methods have an underlying prior knowledge that the linearly interpolated ratio of targets should be kept the same as the ratio proposed in input interpolation. This may lead to a strange phenomenon that sometimes there is no valid object in the mixed image due to the random process in augmentation but there is still response in the label space. To bridge such gap between the input and label spaces, we propose TransMix, which mixes labels based on the attention maps of Vision Transformers. The confidence of the label will be larger if the corresponding input image is weighted higher by the attention map. TransMix is embarrassingly simple and can be implemented in just a few lines of code without introducing any extra parameters and FLOPs to ViT-based models. Experimental results show that our method can consistently improve various ViT-based models at scales on ImageNet classification. After pre-trained with TransMix on ImageNet, the ViT-based models also demonstrate better transferability to semantic segmentation, object detection and instance segmentation. TransMix also exhibits to be more robust when evaluating on 4 different benchmarks. Code will be made publicly available at https://github.com/Beckschen/TransMix.
Advancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence
Nov 18, 2021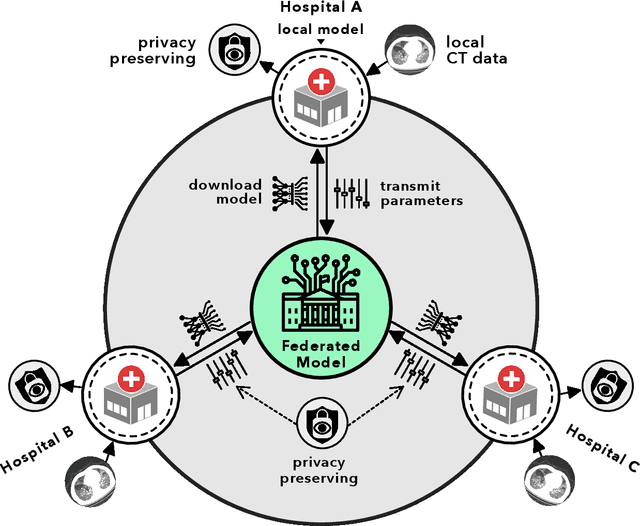
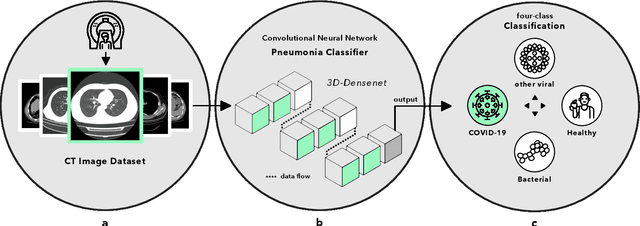
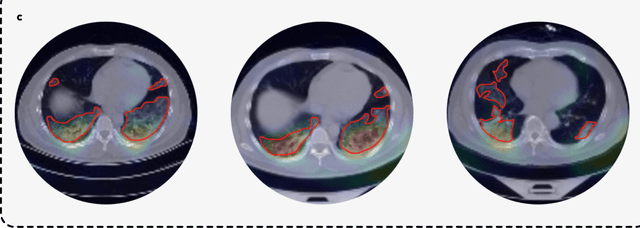
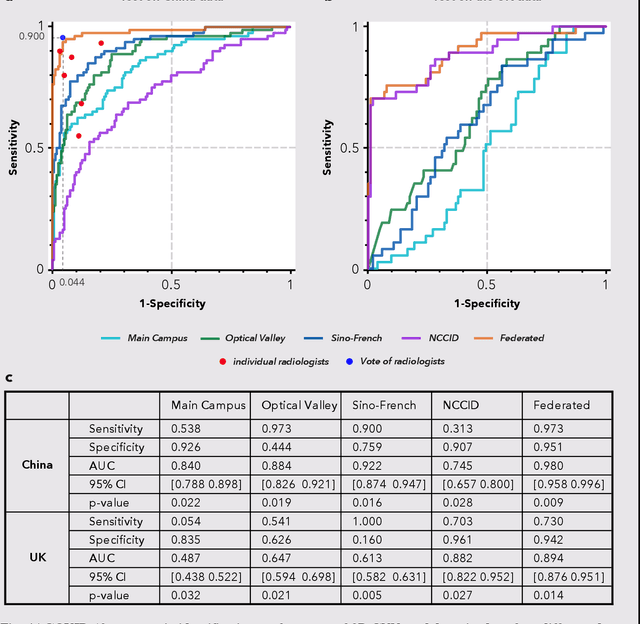
Artificial intelligence (AI) provides a promising substitution for streamlining COVID-19 diagnoses. However, concerns surrounding security and trustworthiness impede the collection of large-scale representative medical data, posing a considerable challenge for training a well-generalised model in clinical practices. To address this, we launch the Unified CT-COVID AI Diagnostic Initiative (UCADI), where the AI model can be distributedly trained and independently executed at each host institution under a federated learning framework (FL) without data sharing. Here we show that our FL model outperformed all the local models by a large yield (test sensitivity /specificity in China: 0.973/0.951, in the UK: 0.730/0.942), achieving comparable performance with a panel of professional radiologists. We further evaluated the model on the hold-out (collected from another two hospitals leaving out the FL) and heterogeneous (acquired with contrast materials) data, provided visual explanations for decisions made by the model, and analysed the trade-offs between the model performance and the communication costs in the federated training process. Our study is based on 9,573 chest computed tomography scans (CTs) from 3,336 patients collected from 23 hospitals located in China and the UK. Collectively, our work advanced the prospects of utilising federated learning for privacy-preserving AI in digital health.
Occluded Video Instance Segmentation: Dataset and ICCV 2021 Challenge
Nov 15, 2021


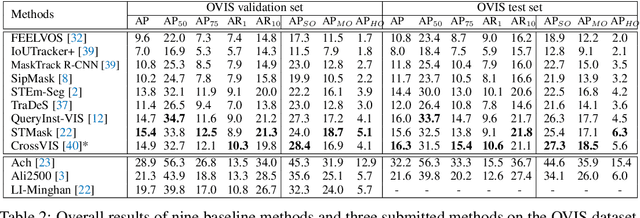
Although deep learning methods have achieved advanced video object recognition performance in recent years, perceiving heavily occluded objects in a video is still a very challenging task. To promote the development of occlusion understanding, we collect a large-scale dataset called OVIS for video instance segmentation in the occluded scenario. OVIS consists of 296k high-quality instance masks and 901 occluded scenes. While our human vision systems can perceive those occluded objects by contextual reasoning and association, our experiments suggest that current video understanding systems cannot. On the OVIS dataset, all baseline methods encounter a significant performance degradation of about 80% in the heavily occluded object group, which demonstrates that there is still a long way to go in understanding obscured objects and videos in a complex real-world scenario. To facilitate the research on new paradigms for video understanding systems, we launched a challenge based on the OVIS dataset. The submitted top-performing algorithms have achieved much higher performance than our baselines. In this paper, we will introduce the OVIS dataset and further dissect it by analyzing the results of baselines and submitted methods. The OVIS dataset and challenge information can be found at http://songbai.site/ovis .
Object Propagation via Inter-Frame Attentions for Temporally Stable Video Instance Segmentation
Nov 15, 2021
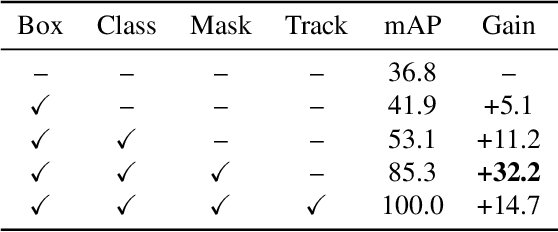
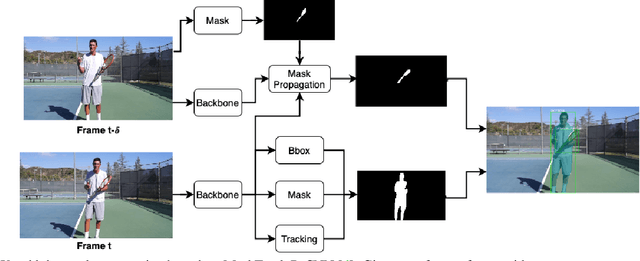
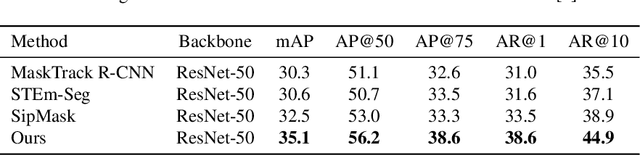
Video instance segmentation aims to detect, segment, and track objects in a video. Current approaches extend image-level segmentation algorithms to the temporal domain. However, this results in temporally inconsistent masks. In this work, we identify the mask quality due to temporal stability as a performance bottleneck. Motivated by this, we propose a video instance segmentation method that alleviates the problem due to missing detections. Since this cannot be solved simply using spatial information, we leverage temporal context using inter-frame attentions. This allows our network to refocus on missing objects using box predictions from the neighbouring frame, thereby overcoming missing detections. Our method significantly outperforms previous state-of-the-art algorithms using the Mask R-CNN backbone, by achieving 35.1% mAP on the YouTube-VIS benchmark. Additionally, our method is completely online and requires no future frames. Our code is publicly available at https://github.com/anirudh-chakravarthy/ObjProp.
CAP-Net: Correspondence-Aware Point-view Fusion Network for 3D Shape Analysis
Sep 03, 2021
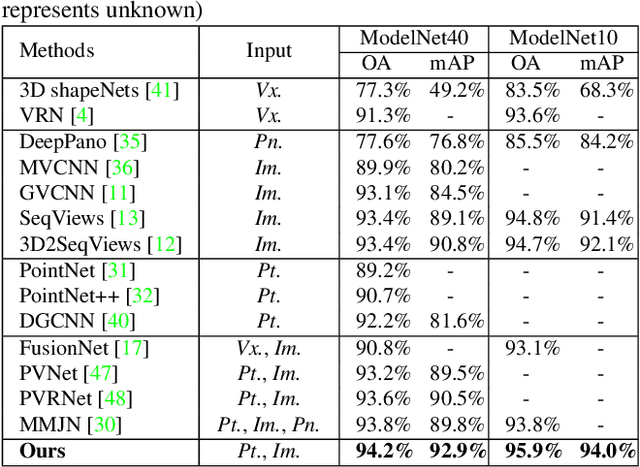
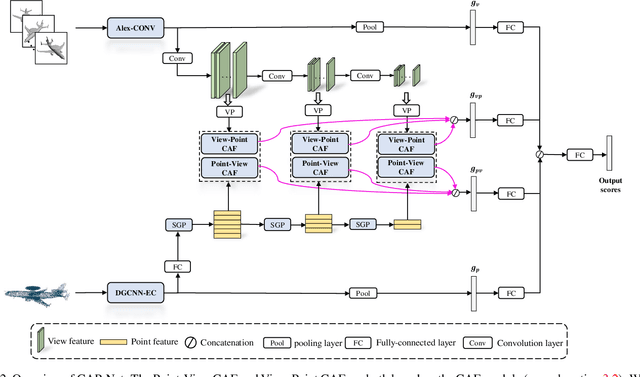
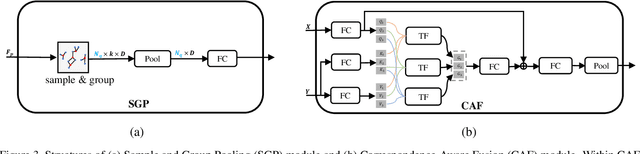
Learning 3D representations by fusing point cloud and multi-view data has been proven to be fairly effective. While prior works typically focus on exploiting global features of the two modalities, in this paper we argue that more discriminative features can be derived by modeling "where to fuse". To investigate this, we propose a novel Correspondence-Aware Point-view Fusion Net (CAPNet). The core element of CAP-Net is a module named Correspondence-Aware Fusion (CAF) which integrates the local features of the two modalities based on their correspondence scores. We further propose to filter out correspondence scores with low values to obtain salient local correspondences, which reduces redundancy for the fusion process. In our CAP-Net, we utilize the CAF modules to fuse the multi-scale features of the two modalities both bidirectionally and hierarchically in order to obtain more informative features. Comprehensive evaluations on popular 3D shape benchmarks covering 3D object classification and retrieval show the superiority of the proposed framework.
PlaneTR: Structure-Guided Transformers for 3D Plane Recovery
Jul 27, 2021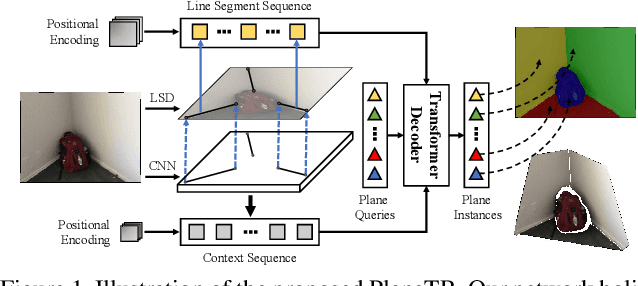
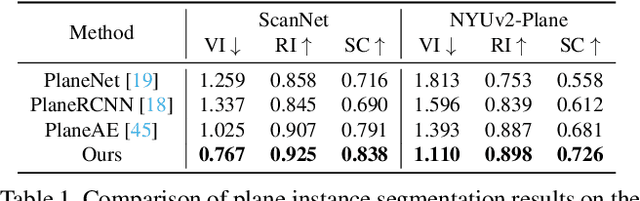
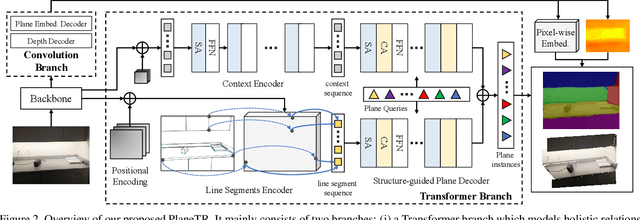
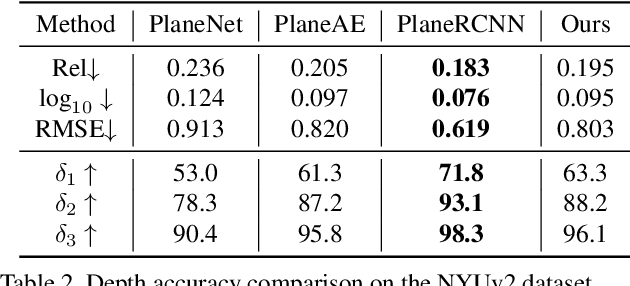
This paper presents a neural network built upon Transformers, namely PlaneTR, to simultaneously detect and reconstruct planes from a single image. Different from previous methods, PlaneTR jointly leverages the context information and the geometric structures in a sequence-to-sequence way to holistically detect plane instances in one forward pass. Specifically, we represent the geometric structures as line segments and conduct the network with three main components: (i) context and line segments encoders, (ii) a structure-guided plane decoder, (iii) a pixel-wise plane embedding decoder. Given an image and its detected line segments, PlaneTR generates the context and line segment sequences via two specially designed encoders and then feeds them into a Transformers-based decoder to directly predict a sequence of plane instances by simultaneously considering the context and global structure cues. Finally, the pixel-wise embeddings are computed to assign each pixel to one predicted plane instance which is nearest to it in embedding space. Comprehensive experiments demonstrate that PlaneTR achieves a state-of-the-art performance on the ScanNet and NYUv2 datasets.
End-to-end Temporal Action Detection with Transformer
Jul 14, 2021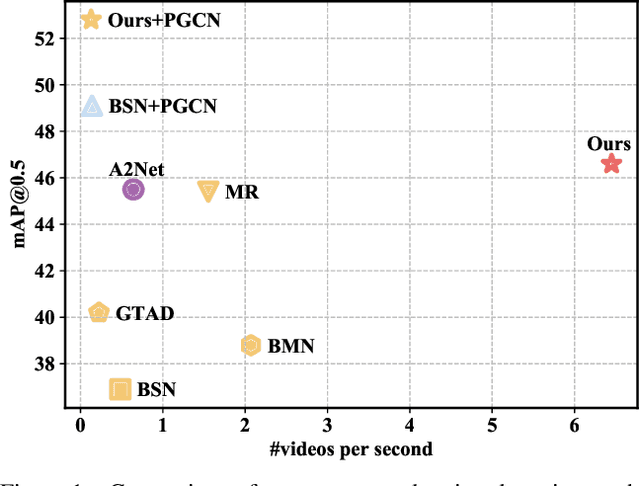
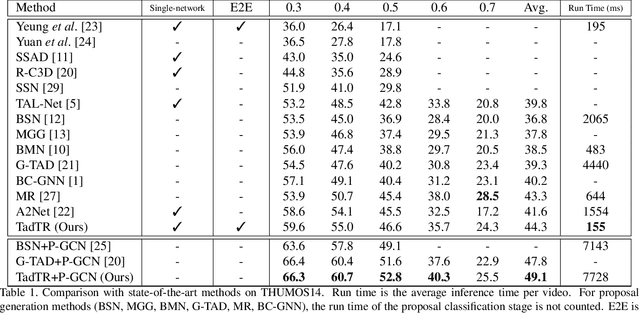
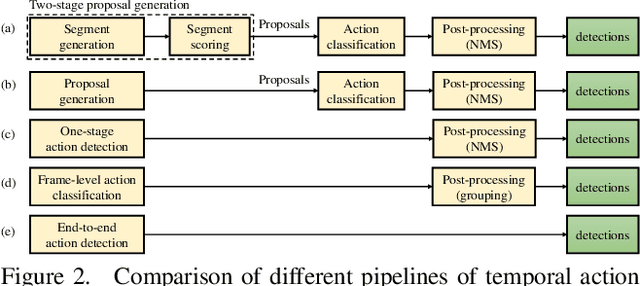
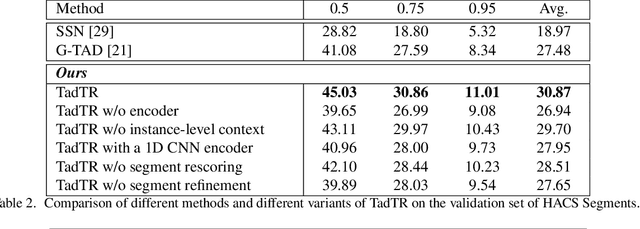
Temporal action detection (TAD) aims to determine the semantic label and the boundaries of every action instance in an untrimmed video. It is a fundamental and challenging task in video understanding and significant progress has been made. Previous methods involve multiple stages or networks and hand-designed rules or operations, which fall short in efficiency and flexibility. In this paper, we propose an end-to-end framework for TAD upon Transformer, termed \textit{TadTR}, which maps a set of learnable embeddings to action instances in parallel. TadTR is able to adaptively extract temporal context information required for making action predictions, by selectively attending to a sparse set of snippets in a video. As a result, it simplifies the pipeline of TAD and requires lower computation cost than previous detectors, while preserving remarkable detection performance. TadTR achieves state-of-the-art performance on HACS Segments (+3.35% average mAP). As a single-network detector, TadTR runs 10$\times$ faster than its comparable competitor. It outperforms existing single-network detectors by a large margin on THUMOS14 (+5.0% average mAP) and ActivityNet (+7.53% average mAP). When combined with other detectors, it reports 54.1% mAP at IoU=0.5 on THUMOS14, and 34.55% average mAP on ActivityNet-1.3. Our code will be released at \url{https://github.com/xlliu7/TadTR}.
Visual Parser: Representing Part-whole Hierarchies with Transformers
Jul 13, 2021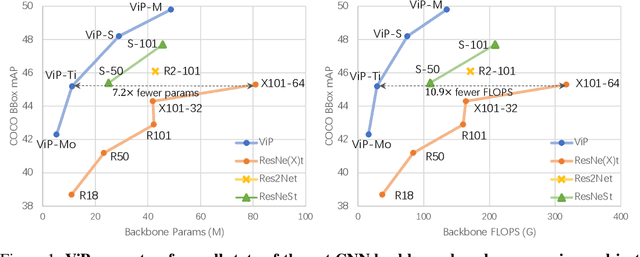
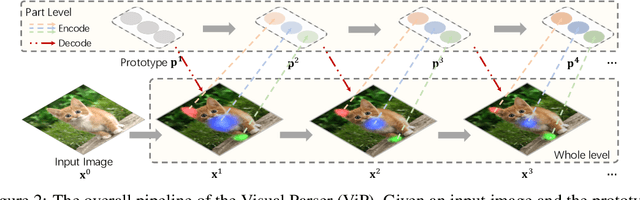
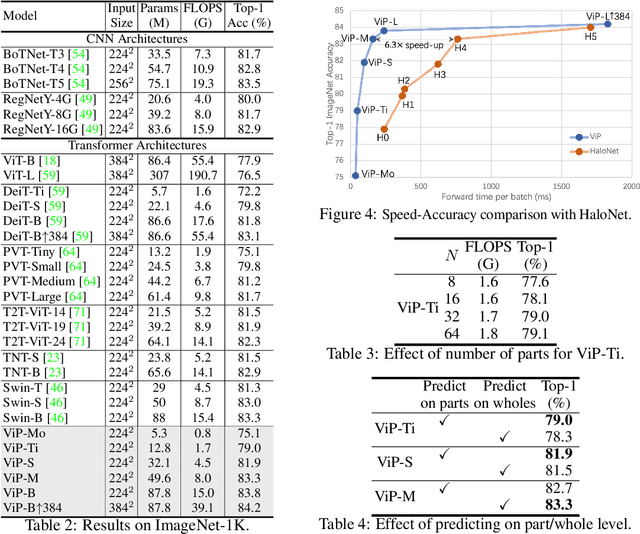
Human vision is able to capture the part-whole hierarchical information from the entire scene. This paper presents the Visual Parser (ViP) that explicitly constructs such a hierarchy with transformers. ViP divides visual representations into two levels, the part level and the whole level. Information of each part represents a combination of several independent vectors within the whole. To model the representations of the two levels, we first encode the information from the whole into part vectors through an attention mechanism, then decode the global information within the part vectors back into the whole representation. By iteratively parsing the two levels with the proposed encoder-decoder interaction, the model can gradually refine the features on both levels. Experimental results demonstrate that ViP can achieve very competitive performance on three major tasks e.g. classification, detection and instance segmentation. In particular, it can surpass the previous state-of-the-art CNN backbones by a large margin on object detection. The tiny model of the ViP family with $7.2\times$ fewer parameters and $10.9\times$ fewer FLOPS can perform comparably with the largest model ResNeXt-101-64$\times$4d of ResNe(X)t family. Visualization results also demonstrate that the learnt parts are highly informative of the predicting class, making ViP more explainable than previous fundamental architectures. Code is available at https://github.com/kevin-ssy/ViP.
I2C2W: Image-to-Character-to-Word Transformers for Accurate Scene Text Recognition
May 18, 2021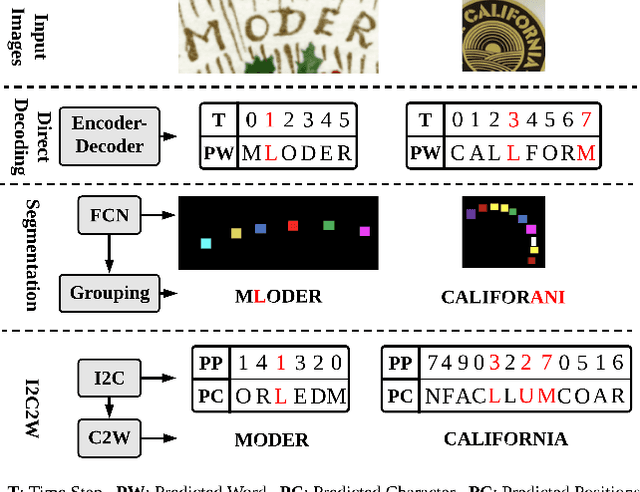
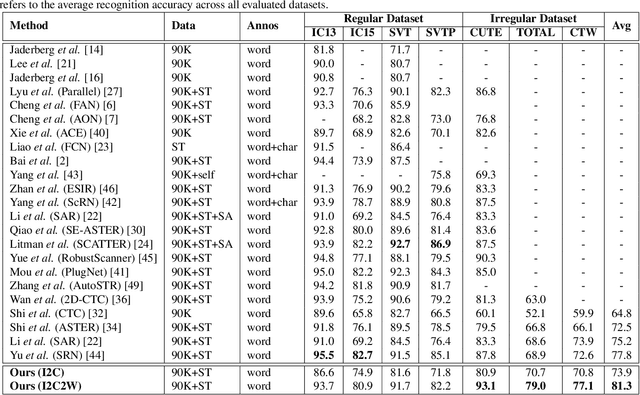
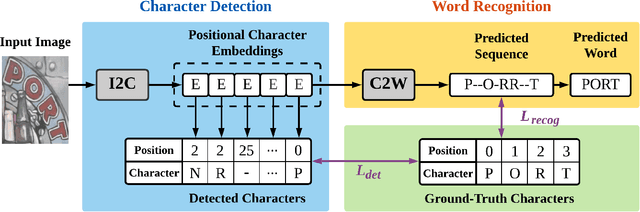
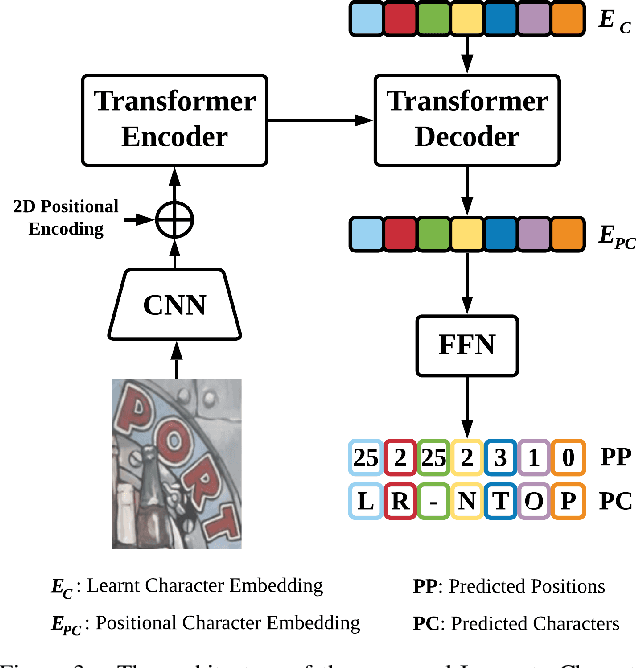
Leveraging the advances of natural language processing, most recent scene text recognizers adopt an encoder-decoder architecture where text images are first converted to representative features and then a sequence of characters via `direct decoding'. However, scene text images suffer from rich noises of different sources such as complex background and geometric distortions which often confuse the decoder and lead to incorrect alignment of visual features at noisy decoding time steps. This paper presents I2C2W, a novel scene text recognizer that is accurate and tolerant to various noises in scenes. I2C2W consists of an image-to-character module (I2C) and a character-to-word module (C2W) which are complementary and can be trained end-to-end. I2C detects characters and predicts their relative positions in a word. It strives to detect all possible characters including incorrect and redundant ones based on different alignments of visual features without the restriction of time steps. Taking the detected characters as input, C2W learns from character semantics and their positions to filter out incorrect and redundant detection and produce the final word recognition. Extensive experiments over seven public datasets show that I2C2W achieves superior recognition performances and outperforms the state-of-the-art by large margins on challenging irregular scene text datasets.
Location-Sensitive Visual Recognition with Cross-IOU Loss
Apr 11, 2021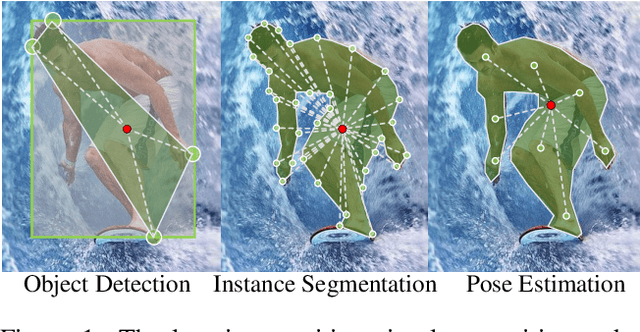
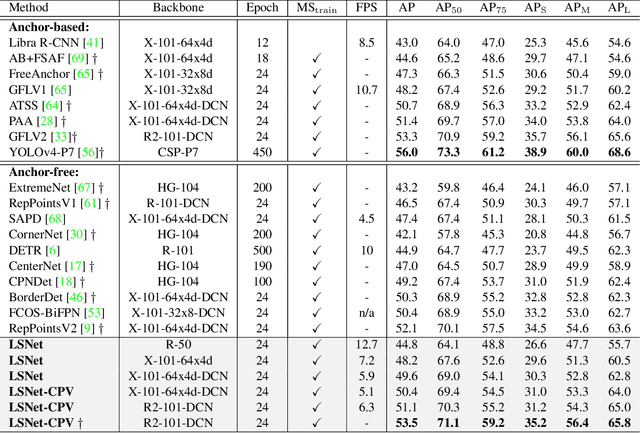
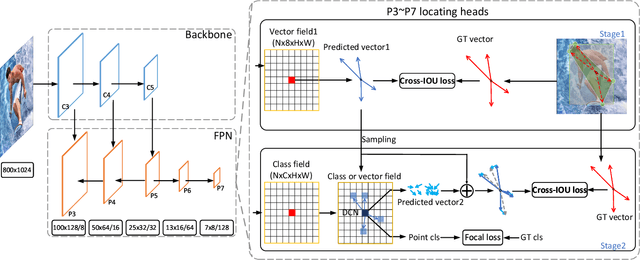
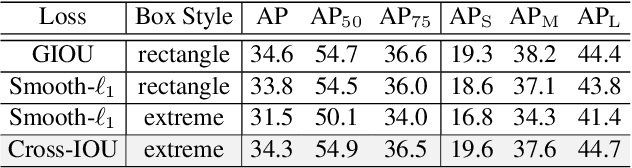
Object detection, instance segmentation, and pose estimation are popular visual recognition tasks which require localizing the object by internal or boundary landmarks. This paper summarizes these tasks as location-sensitive visual recognition and proposes a unified solution named location-sensitive network (LSNet). Based on a deep neural network as the backbone, LSNet predicts an anchor point and a set of landmarks which together define the shape of the target object. The key to optimizing the LSNet lies in the ability of fitting various scales, for which we design a novel loss function named cross-IOU loss that computes the cross-IOU of each anchor point-landmark pair to approximate the global IOU between the prediction and ground-truth. The flexibly located and accurately predicted landmarks also enable LSNet to incorporate richer contextual information for visual recognition. Evaluated on the MS-COCO dataset, LSNet set the new state-of-the-art accuracy for anchor-free object detection (a 53.5% box AP) and instance segmentation (a 40.2% mask AP), and shows promising performance in detecting multi-scale human poses. Code is available at https://github.com/Duankaiwen/LSNet