 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMufu: Multilingual Fused Learning for Low-Resource Translation with LLM
Sep 20, 2024Multilingual large language models (LLMs) are great translators, but this is largely limited to high-resource languages. For many LLMs, translating in and out of low-resource languages remains a challenging task. To maximize data efficiency in this low-resource setting, we introduce Mufu, which includes a selection of automatically generated multilingual candidates and an instruction to correct inaccurate translations in the prompt. Mufu prompts turn a translation task into a postediting one, and seek to harness the LLM's reasoning capability with auxiliary translation candidates, from which the model is required to assess the input quality, align the semantics cross-lingually, copy from relevant inputs and override instances that are incorrect. Our experiments on En-XX translations over the Flores-200 dataset show LLMs finetuned against Mufu-style prompts are robust to poor quality auxiliary translation candidates, achieving performance superior to NLLB 1.3B distilled model in 64% of low- and very-low-resource language pairs. We then distill these models to reduce inference cost, while maintaining on average 3.1 chrF improvement over finetune-only baseline in low-resource translations.
IndicGenBench: A Multilingual Benchmark to Evaluate Generation Capabilities of LLMs on Indic Languages
Apr 25, 2024As large language models (LLMs) see increasing adoption across the globe, it is imperative for LLMs to be representative of the linguistic diversity of the world. India is a linguistically diverse country of 1.4 Billion people. To facilitate research on multilingual LLM evaluation, we release IndicGenBench - the largest benchmark for evaluating LLMs on user-facing generation tasks across a diverse set 29 of Indic languages covering 13 scripts and 4 language families. IndicGenBench is composed of diverse generation tasks like cross-lingual summarization, machine translation, and cross-lingual question answering. IndicGenBench extends existing benchmarks to many Indic languages through human curation providing multi-way parallel evaluation data for many under-represented Indic languages for the first time. We evaluate a wide range of proprietary and open-source LLMs including GPT-3.5, GPT-4, PaLM-2, mT5, Gemma, BLOOM and LLaMA on IndicGenBench in a variety of settings. The largest PaLM-2 models performs the best on most tasks, however, there is a significant performance gap in all languages compared to English showing that further research is needed for the development of more inclusive multilingual language models. IndicGenBench is released at www.github.com/google-research-datasets/indic-gen-bench
Potential-Based Reward Shaping For Intrinsic Motivation
Feb 12, 2024



Recently there has been a proliferation of intrinsic motivation (IM) reward-shaping methods to learn in complex and sparse-reward environments. These methods can often inadvertently change the set of optimal policies in an environment, leading to suboptimal behavior. Previous work on mitigating the risks of reward shaping, particularly through potential-based reward shaping (PBRS), has not been applicable to many IM methods, as they are often complex, trainable functions themselves, and therefore dependent on a wider set of variables than the traditional reward functions that PBRS was developed for. We present an extension to PBRS that we prove preserves the set of optimal policies under a more general set of functions than has been previously proven. We also present {\em Potential-Based Intrinsic Motivation} (PBIM), a method for converting IM rewards into a potential-based form that is useable without altering the set of optimal policies. Testing in the MiniGrid DoorKey and Cliff Walking environments, we demonstrate that PBIM successfully prevents the agent from converging to a suboptimal policy and can speed up training.
LLM Augmented LLMs: Expanding Capabilities through Composition
Jan 04, 2024



Foundational models with billions of parameters which have been trained on large corpora of data have demonstrated non-trivial skills in a variety of domains. However, due to their monolithic structure, it is challenging and expensive to augment them or impart new skills. On the other hand, due to their adaptation abilities, several new instances of these models are being trained towards new domains and tasks. In this work, we study the problem of efficient and practical composition of existing foundation models with more specific models to enable newer capabilities. To this end, we propose CALM -- Composition to Augment Language Models -- which introduces cross-attention between models to compose their representations and enable new capabilities. Salient features of CALM are: (i) Scales up LLMs on new tasks by 're-using' existing LLMs along with a few additional parameters and data, (ii) Existing model weights are kept intact, and hence preserves existing capabilities, and (iii) Applies to diverse domains and settings. We illustrate that augmenting PaLM2-S with a smaller model trained on low-resource languages results in an absolute improvement of up to 13\% on tasks like translation into English and arithmetic reasoning for low-resource languages. Similarly, when PaLM2-S is augmented with a code-specific model, we see a relative improvement of 40\% over the base model for code generation and explanation tasks -- on-par with fully fine-tuned counterparts.
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models
Optimizing Real-Time Performances for Timed-Loop Racing under F1TENTH
Dec 08, 2022



Motion planning and control in autonomous car racing are one of the most challenging and safety-critical tasks due to high speed and dynamism. The lower-level control nodes are expected to be highly optimized due to resource constraints of onboard embedded processing units, although there are strict latency requirements. Some of these guarantees can be provided at the application level, such as using ROS2's Real-Time executors. However, the performance can be far from satisfactory as many modern control algorithms (such as Model Predictive Control) rely on solving complicated online optimization problems at each iteration. In this paper, we present a simple yet effective multi-threading technique to optimize the throughput of online-control algorithms for resource-constrained autonomous racing platforms. We achieve this by maintaining a systematic pool of worker threads solving the optimization problem in parallel which can improve the system performance by reducing latency between control input commands. We further demonstrate the effectiveness of our method using the Model Predictive Contouring Control (MPCC) algorithm running on Nvidia's Xavier AGX platform.
Bootstrapping Multilingual Semantic Parsers using Large Language Models
Oct 13, 2022
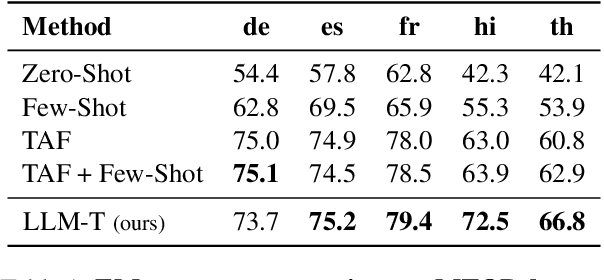

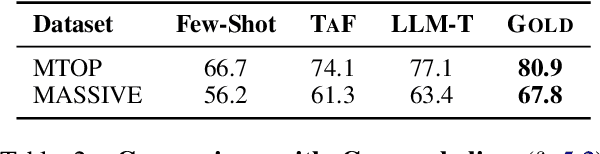
Despite cross-lingual generalization demonstrated by pre-trained multilingual models, the translate-train paradigm of transferring English datasets across multiple languages remains to be the key ingredient for training task-specific multilingual models. However, for many low-resource languages, the availability of a reliable translation service entails significant amounts of costly human-annotated translation pairs. Further, the translation services for low-resource languages may continue to be brittle due to domain mismatch between the task-specific input text and the general-purpose text used while training the translation models. We consider the task of multilingual semantic parsing and demonstrate the effectiveness and flexibility offered by large language models (LLMs) for translating English datasets into several languages via few-shot prompting. We provide (i) Extensive comparisons with prior translate-train methods across 50 languages demonstrating that LLMs can serve as highly effective data translators, outperforming prior translation based methods on 40 out of 50 languages; (ii) A comprehensive study of the key design choices that enable effective data translation via prompted LLMs.
QA Is the New KR: Question-Answer Pairs as Knowledge Bases
Jul 01, 2022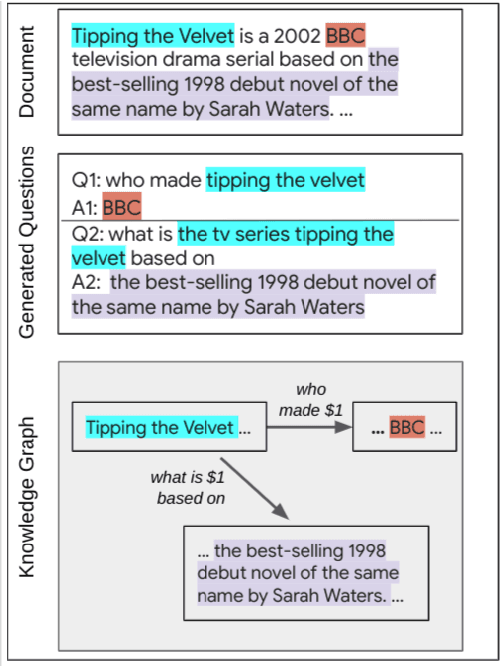
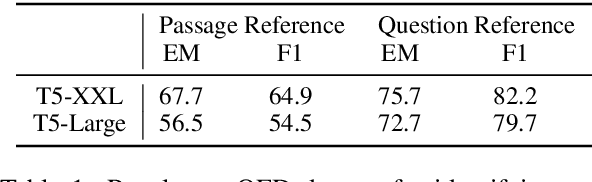
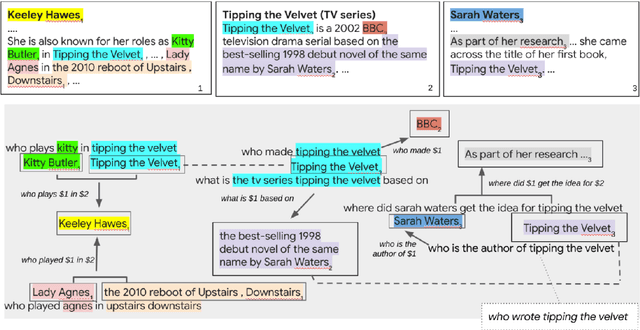
In this position paper, we propose a new approach to generating a type of knowledge base (KB) from text, based on question generation and entity linking. We argue that the proposed type of KB has many of the key advantages of a traditional symbolic KB: in particular, it consists of small modular components, which can be combined compositionally to answer complex queries, including relational queries and queries involving "multi-hop" inferences. However, unlike a traditional KB, this information store is well-aligned with common user information needs.
Event Linking: Grounding Event Mentions to Wikipedia
Dec 15, 2021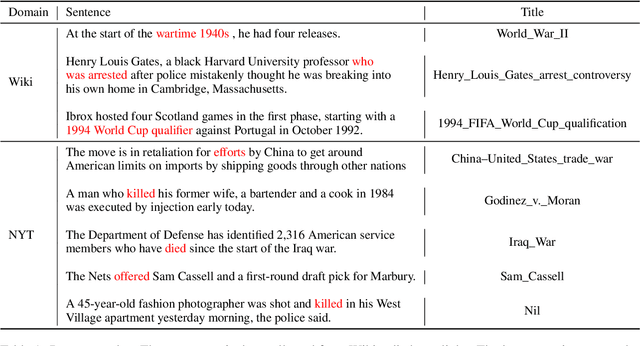
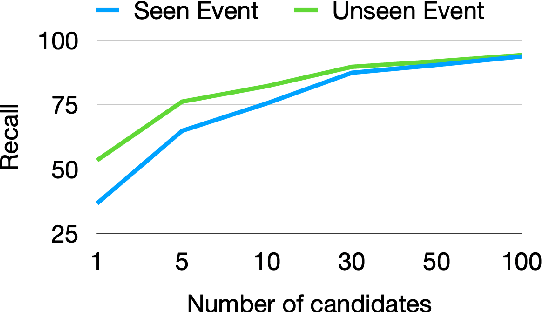
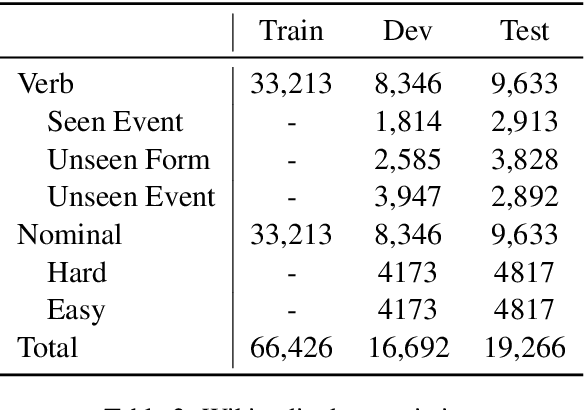
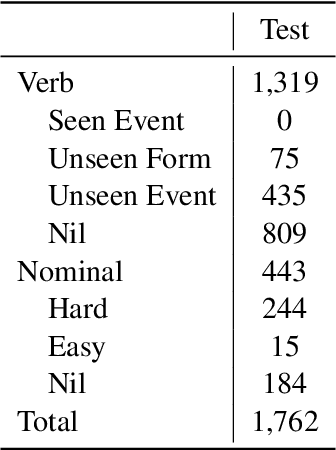
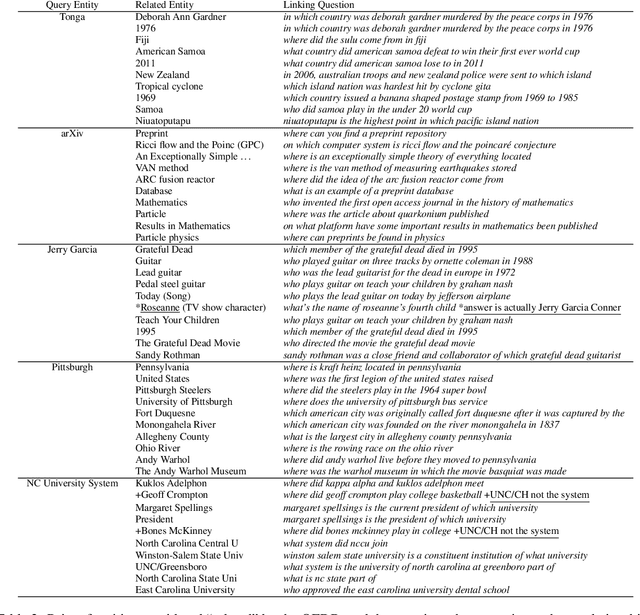
Comprehending an article requires understanding its constituent events. However, the context where an event is mentioned often lacks the details of this event. Then, where can we obtain more knowledge of this particular event in addition to its context? This work defines Event Linking, a new natural language understanding task at the event level. Event linking tries to link an event mention, appearing in a news article for example, to the most appropriate Wikipedia page. This page is expected to provide rich knowledge about what the event refers to. To standardize the research of this new problem, we contribute in three-fold. First, this is the first work in the community that formally defines event linking task. Second, we collect a dataset for this new task. In specific, we first gather training set automatically from Wikipedia, then create two evaluation sets: one from the Wikipedia domain as well, reporting the in-domain performance; the other from the real-world news domain, testing the out-of-domain performance. Third, we propose EveLINK, the first-ever Event Linking approach. Overall, event linking is a considerably challenging task requiring more effort from the community. Data and code are available here: https://github.com/CogComp/event-linking.
Enforcing Consistency in Weakly Supervised Semantic Parsing
Jul 13, 2021
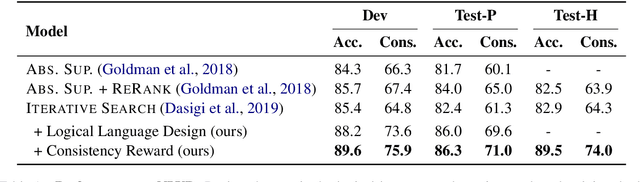

The predominant challenge in weakly supervised semantic parsing is that of spurious programs that evaluate to correct answers for the wrong reasons. Prior work uses elaborate search strategies to mitigate the prevalence of spurious programs; however, they typically consider only one input at a time. In this work we explore the use of consistency between the output programs for related inputs to reduce the impact of spurious programs. We bias the program search (and thus the model's training signal) towards programs that map the same phrase in related inputs to the same sub-parts in their respective programs. Additionally, we study the importance of designing logical formalisms that facilitate this kind of consAistency-based training. We find that a more consistent formalism leads to improved model performance even without consistency-based training. When combined together, these two insights lead to a 10% absolute improvement over the best prior result on the Natural Language Visual Reasoning dataset.