 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRISP: Clustering Multi-Vector Representations for Denoising and Pruning
May 16, 2025Multi-vector models, such as ColBERT, are a significant advancement in neural information retrieval (IR), delivering state-of-the-art performance by representing queries and documents by multiple contextualized token-level embeddings. However, this increased representation size introduces considerable storage and computational overheads which have hindered widespread adoption in practice. A common approach to mitigate this overhead is to cluster the model's frozen vectors, but this strategy's effectiveness is fundamentally limited by the intrinsic clusterability of these embeddings. In this work, we introduce CRISP (Clustered Representations with Intrinsic Structure Pruning), a novel multi-vector training method which learns inherently clusterable representations directly within the end-to-end training process. By integrating clustering into the training phase rather than imposing it post-hoc, CRISP significantly outperforms post-hoc clustering at all representation sizes, as well as other token pruning methods. On the BEIR retrieval benchmarks, CRISP achieves a significant rate of ~3x reduction in the number of vectors while outperforming the original unpruned model. This indicates that learned clustering effectively denoises the model by filtering irrelevant information, thereby generating more robust multi-vector representations. With more aggressive clustering, CRISP achieves an 11x reduction in the number of vectors with only a $3.6\%$ quality loss.
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
ATEB: Evaluating and Improving Advanced NLP Tasks for Text Embedding Models
Feb 24, 2025



Traditional text embedding benchmarks primarily evaluate embedding models' capabilities to capture semantic similarity. However, more advanced NLP tasks require a deeper understanding of text, such as safety and factuality. These tasks demand an ability to comprehend and process complex information, often involving the handling of sensitive content, or the verification of factual statements against reliable sources. We introduce a new benchmark designed to assess and highlight the limitations of embedding models trained on existing information retrieval data mixtures on advanced capabilities, which include factuality, safety, instruction following, reasoning and document-level understanding. This benchmark includes a diverse set of tasks that simulate real-world scenarios where these capabilities are critical and leads to identification of the gaps of the currently advanced embedding models. Furthermore, we propose a novel method that reformulates these various tasks as retrieval tasks. By framing tasks like safety or factuality classification as retrieval problems, we leverage the strengths of retrieval models in capturing semantic relationships while also pushing them to develop a deeper understanding of context and content. Using this approach with single-task fine-tuning, we achieved performance gains of 8\% on factuality classification and 13\% on safety classification. Our code and data will be publicly available.
Transforming LLMs into Cross-modal and Cross-lingual Retrieval Systems
Apr 04, 2024Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Mar 29, 2024



We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Leveraging LLMs for Synthesizing Training Data Across Many Languages in Multilingual Dense Retrieval
Nov 10, 2023



Dense retrieval models have predominantly been studied for English, where models have shown great success, due to the availability of human-labeled training pairs. However, there has been limited success for multilingual retrieval so far, as training data is uneven or scarcely available across multiple languages. Synthetic training data generation is promising (e.g., InPars or Promptagator), but has been investigated only for English. Therefore, to study model capabilities across both cross-lingual and monolingual retrieval tasks, we develop SWIM-IR, a synthetic retrieval training dataset containing 33 (high to very-low resource) languages for training multilingual dense retrieval models without requiring any human supervision. To construct SWIM-IR, we propose SAP (summarize-then-ask prompting), where the large language model (LLM) generates a textual summary prior to the query generation step. SAP assists the LLM in generating informative queries in the target language. Using SWIM-IR, we explore synthetic fine-tuning of multilingual dense retrieval models and evaluate them robustly on three retrieval benchmarks: XOR-Retrieve (cross-lingual), XTREME-UP (cross-lingual) and MIRACL (monolingual). Our models, called SWIM-X, are competitive with human-supervised dense retrieval models, e.g., mContriever, finding that SWIM-IR can cheaply substitute for expensive human-labeled retrieval training data.
Knowledge Prompts: Injecting World Knowledge into Language Models through Soft Prompts
Oct 10, 2022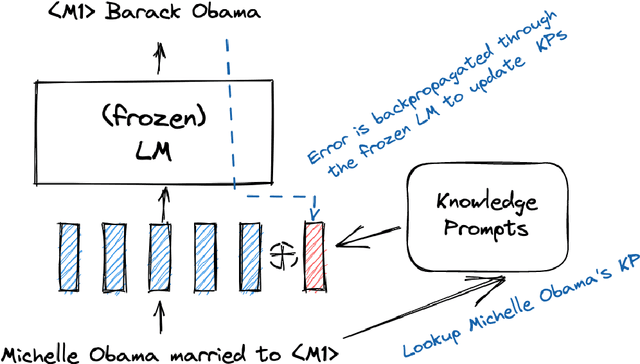
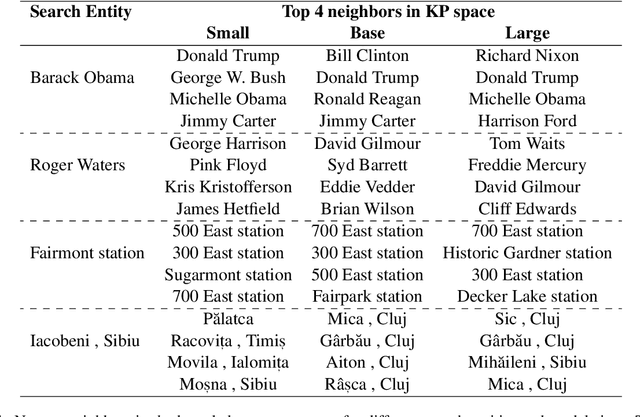
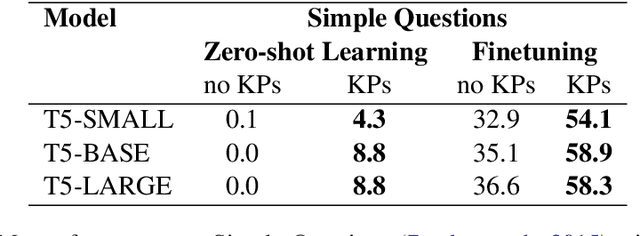
Soft prompts have been recently proposed as a tool for adapting large frozen language models (LMs) to new tasks. In this work, we repurpose soft prompts to the task of injecting world knowledge into LMs. We introduce a method to train soft prompts via self-supervised learning on data from knowledge bases. The resulting soft knowledge prompts (KPs) are task independent and work as an external memory of the LMs. We perform qualitative and quantitative experiments and demonstrate that: (1) KPs can effectively model the structure of the training data; (2) KPs can be used to improve the performance of LMs in different knowledge intensive tasks.
Overcoming Catastrophic Forgetting in Zero-Shot Cross-Lingual Generation
May 25, 2022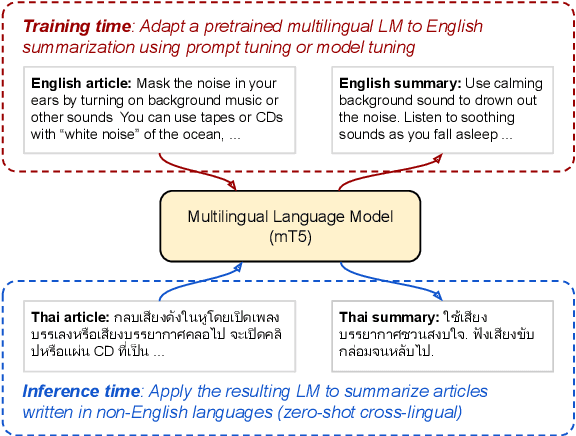
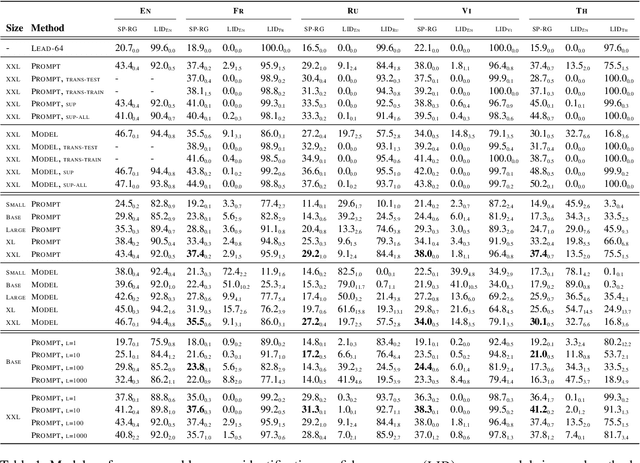
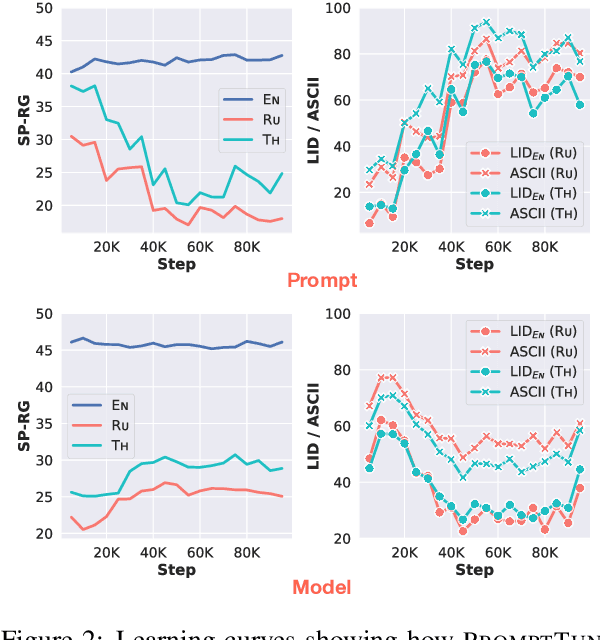
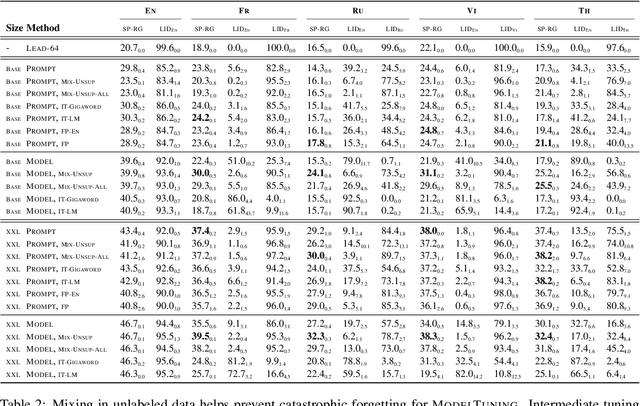
In this paper, we explore the challenging problem of performing a generative task (i.e., summarization) in a target language when labeled data is only available in English. We assume a strict setting with no access to parallel data or machine translation. Prior work has shown, and we confirm, that standard transfer learning techniques struggle in this setting, as a generative multilingual model fine-tuned purely on English catastrophically forgets how to generate non-English. Given the recent rise of parameter-efficient adaptation techniques (e.g., prompt tuning), we conduct the first investigation into how well these methods can overcome catastrophic forgetting to enable zero-shot cross-lingual generation. We find that parameter-efficient adaptation provides gains over standard fine-tuning when transferring between less-related languages, e.g., from English to Thai. However, a significant gap still remains between these methods and fully-supervised baselines. To improve cross-lingual transfer further, we explore three approaches: (1) mixing in unlabeled multilingual data, (2) pre-training prompts on target language data, and (3) explicitly factoring prompts into recombinable language and task components. Our methods can provide further quality gains, suggesting that robust zero-shot cross-lingual generation is within reach.
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
Oct 15, 2021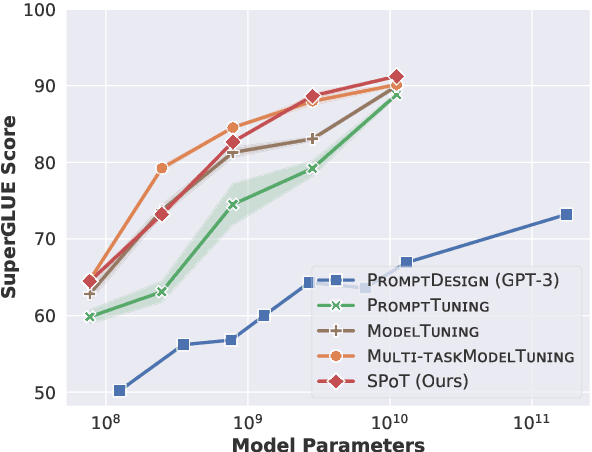
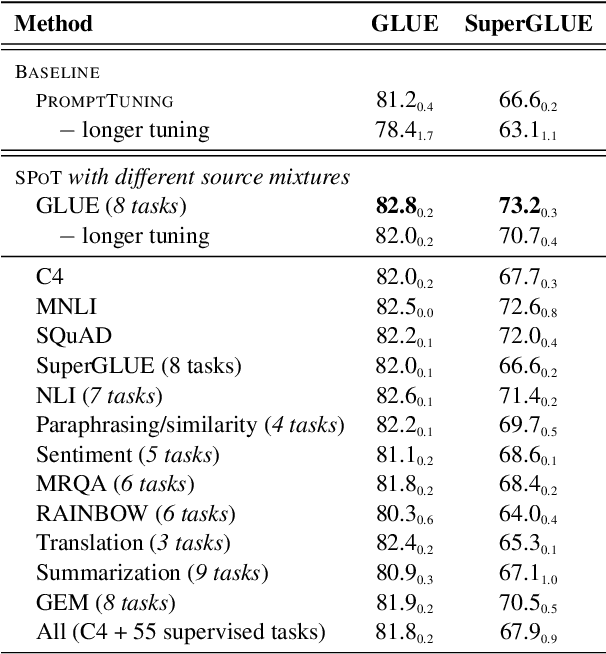
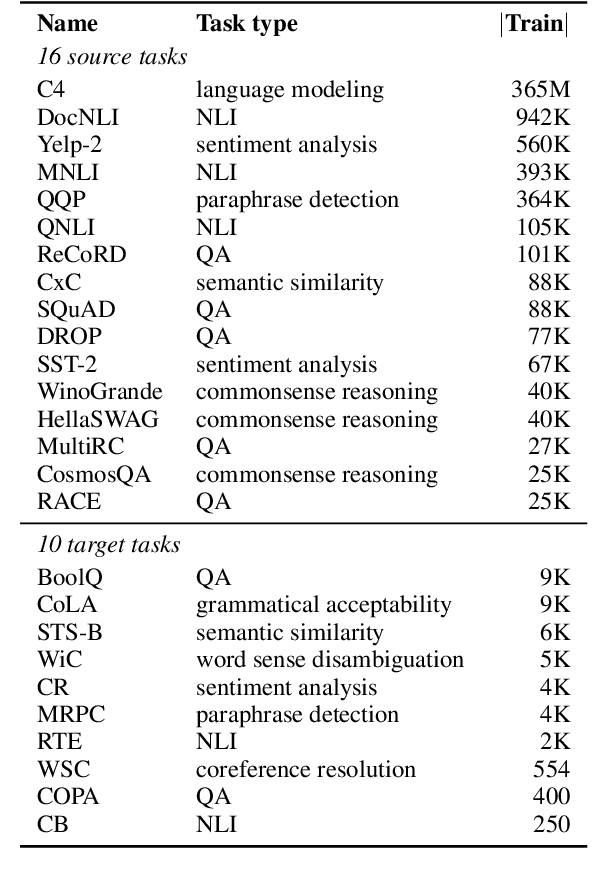
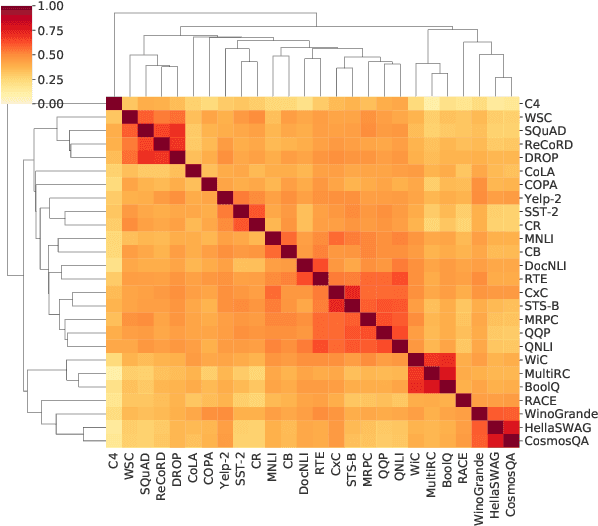
As pre-trained language models have gotten larger, there has been growing interest in parameter-efficient methods to apply these models to downstream tasks. Building on the PromptTuning approach of Lester et al. (2021), which learns task-specific soft prompts to condition a frozen language model to perform downstream tasks, we propose a novel prompt-based transfer learning approach called SPoT: Soft Prompt Transfer. SPoT first learns a prompt on one or more source tasks and then uses it to initialize the prompt for a target task. We show that SPoT significantly boosts the performance of PromptTuning across many tasks. More importantly, SPoT either matches or outperforms ModelTuning, which fine-tunes the entire model on each individual task, across all model sizes while being more parameter-efficient (up to 27,000x fewer task-specific parameters). We further conduct a large-scale study on task transferability with 26 NLP tasks and 160 combinations of source-target tasks, and demonstrate that tasks can often benefit each other via prompt transfer. Finally, we propose a simple yet efficient retrieval approach that interprets task prompts as task embeddings to identify the similarity between tasks and predict the most transferable source tasks for a given novel target task.