 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
Mining Generalizable Activation Functions
Feb 05, 2026The choice of activation function is an active area of research, with different proposals aimed at improving optimization, while maintaining expressivity. Additionally, the activation function can significantly alter the implicit inductive bias of the architecture, controlling its non-linear behavior. In this paper, in line with previous work, we argue that evolutionary search provides a useful framework for finding new activation functions, while we also make two novel observations. The first is that modern pipelines, such as AlphaEvolve, which relies on frontier LLMs as a mutator operator, allows for a much wider and flexible search space; e.g., over all possible python functions within a certain FLOP budget, eliminating the need for manually constructed search spaces. In addition, these pipelines will be biased towards meaningful activation functions, given their ability to represent common knowledge, leading to a potentially more efficient search of the space. The second observation is that, through this framework, one can target not only performance improvements but also activation functions that encode particular inductive biases. This can be done by using performance on out-of-distribution data as a fitness function, reflecting the degree to which the architecture respects the inherent structure in the data in a manner independent of distribution shifts. We carry an empirical exploration of this proposal and show that relatively small scale synthetic datasets can be sufficient for AlphaEvolve to discover meaningful activations.
On the Theoretical Limitations of Embedding-Based Retrieval
Aug 28, 2025



Vector embeddings have been tasked with an ever-increasing set of retrieval tasks over the years, with a nascent rise in using them for reasoning, instruction-following, coding, and more. These new benchmarks push embeddings to work for any query and any notion of relevance that could be given. While prior works have pointed out theoretical limitations of vector embeddings, there is a common assumption that these difficulties are exclusively due to unrealistic queries, and those that are not can be overcome with better training data and larger models. In this work, we demonstrate that we may encounter these theoretical limitations in realistic settings with extremely simple queries. We connect known results in learning theory, showing that the number of top-k subsets of documents capable of being returned as the result of some query is limited by the dimension of the embedding. We empirically show that this holds true even if we restrict to k=2, and directly optimize on the test set with free parameterized embeddings. We then create a realistic dataset called LIMIT that stress tests models based on these theoretical results, and observe that even state-of-the-art models fail on this dataset despite the simple nature of the task. Our work shows the limits of embedding models under the existing single vector paradigm and calls for future research to develop methods that can resolve this fundamental limitation.
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
A Fresh Take on Stale Embeddings: Improving Dense Retriever Training with Corrector Networks
Sep 03, 2024



In dense retrieval, deep encoders provide embeddings for both inputs and targets, and the softmax function is used to parameterize a distribution over a large number of candidate targets (e.g., textual passages for information retrieval). Significant challenges arise in training such encoders in the increasingly prevalent scenario of (1) a large number of targets, (2) a computationally expensive target encoder model, (3) cached target embeddings that are out-of-date due to ongoing training of target encoder parameters. This paper presents a simple and highly scalable response to these challenges by training a small parametric corrector network that adjusts stale cached target embeddings, enabling an accurate softmax approximation and thereby sampling of up-to-date high scoring "hard negatives." We theoretically investigate the generalization properties of our proposed target corrector, relating the complexity of the network, staleness of cached representations, and the amount of training data. We present experimental results on large benchmark dense retrieval datasets as well as on QA with retrieval augmented language models. Our approach matches state-of-the-art results even when no target embedding updates are made during training beyond an initial cache from the unsupervised pre-trained model, providing a 4-80x reduction in re-embedding computational cost.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024



Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
Every Answer Matters: Evaluating Commonsense with Probabilistic Measures
Jun 06, 2024



Large language models have demonstrated impressive performance on commonsense tasks; however, these tasks are often posed as multiple-choice questions, allowing models to exploit systematic biases. Commonsense is also inherently probabilistic with multiple correct answers. The purpose of "boiling water" could be making tea and cooking, but it also could be killing germs. Existing tasks do not capture the probabilistic nature of common sense. To this end, we present commonsense frame completion (CFC), a new generative task that evaluates common sense via multiple open-ended generations. We also propose a method of probabilistic evaluation that strongly correlates with human judgments. Humans drastically outperform strong language model baselines on our dataset, indicating this approach is both a challenging and useful evaluation of machine common sense.
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Mar 29, 2024



We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
Box Embeddings: An open-source library for representation learning using geometric structures
Sep 10, 2021
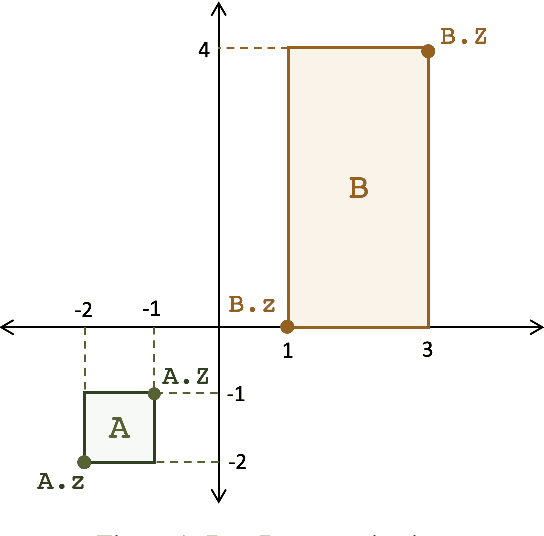
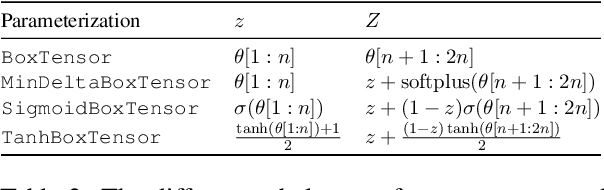
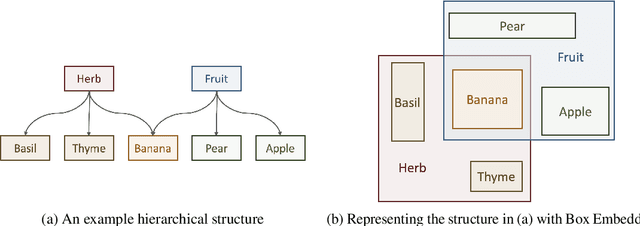
A major factor contributing to the success of modern representation learning is the ease of performing various vector operations. Recently, objects with geometric structures (eg. distributions, complex or hyperbolic vectors, or regions such as cones, disks, or boxes) have been explored for their alternative inductive biases and additional representational capacities. In this work, we introduce Box Embeddings, a Python library that enables researchers to easily apply and extend probabilistic box embeddings.
Word2Box: Learning Word Representation Using Box Embeddings
Jun 28, 2021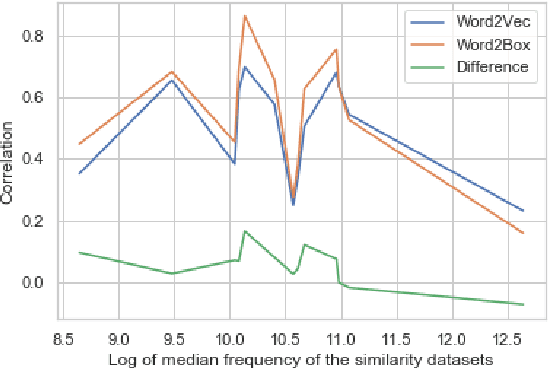



Learning vector representations for words is one of the most fundamental topics in NLP, capable of capturing syntactic and semantic relationships useful in a variety of downstream NLP tasks. Vector representations can be limiting, however, in that typical scoring such as dot product similarity intertwines position and magnitude of the vector in space. Exciting innovations in the space of representation learning have proposed alternative fundamental representations, such as distributions, hyperbolic vectors, or regions. Our model, Word2Box, takes a region-based approach to the problem of word representation, representing words as $n$-dimensional rectangles. These representations encode position and breadth independently and provide additional geometric operations such as intersection and containment which allow them to model co-occurrence patterns vectors struggle with. We demonstrate improved performance on various word similarity tasks, particularly on less common words, and perform a qualitative analysis exploring the additional unique expressivity provided by Word2Box.