 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming LLMs into Cross-modal and Cross-lingual Retrieval Systems
Apr 04, 2024Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
Layer-Wise Analysis of Self-Supervised Acoustic Word Embeddings: A Study on Speech Emotion Recognition
Feb 04, 2024



The efficacy of self-supervised speech models has been validated, yet the optimal utilization of their representations remains challenging across diverse tasks. In this study, we delve into Acoustic Word Embeddings (AWEs), a fixed-length feature derived from continuous representations, to explore their advantages in specific tasks. AWEs have previously shown utility in capturing acoustic discriminability. In light of this, we propose measuring layer-wise similarity between AWEs and word embeddings, aiming to further investigate the inherent context within AWEs. Moreover, we evaluate the contribution of AWEs, in comparison to other types of speech features, in the context of Speech Emotion Recognition (SER). Through a comparative experiment and a layer-wise accuracy analysis on two distinct corpora, IEMOCAP and ESD, we explore differences between AWEs and raw self-supervised representations, as well as the proper utilization of AWEs alone and in combination with word embeddings. Our findings underscore the acoustic context conveyed by AWEs and showcase the highly competitive SER accuracies by appropriately employing AWEs.
Acoustic Word Embeddings for Untranscribed Target Languages with Continued Pretraining and Learned Pooling
Jun 03, 2023



Acoustic word embeddings are typically created by training a pooling function using pairs of word-like units. For unsupervised systems, these are mined using k-nearest neighbor (KNN) search, which is slow. Recently, mean-pooled representations from a pre-trained self-supervised English model were suggested as a promising alternative, but their performance on target languages was not fully competitive. Here, we explore improvements to both approaches: we use continued pre-training to adapt the self-supervised model to the target language, and we use a multilingual phone recognizer (MPR) to mine phone n-gram pairs for training the pooling function. Evaluating on four languages, we show that both methods outperform a recent approach on word discrimination. Moreover, the MPR method is orders of magnitude faster than KNN, and is highly data efficient. We also show a small improvement from performing learned pooling on top of the continued pre-trained representations.
The Edinburgh International Accents of English Corpus: Towards the Democratization of English ASR
Mar 31, 2023English is the most widely spoken language in the world, used daily by millions of people as a first or second language in many different contexts. As a result, there are many varieties of English. Although the great many advances in English automatic speech recognition (ASR) over the past decades, results are usually reported based on test datasets which fail to represent the diversity of English as spoken today around the globe. We present the first release of The Edinburgh International Accents of English Corpus (EdAcc). This dataset attempts to better represent the wide diversity of English, encompassing almost 40 hours of dyadic video call conversations between friends. Unlike other datasets, EdAcc includes a wide range of first and second-language varieties of English and a linguistic background profile of each speaker. Results on latest public, and commercial models show that EdAcc highlights shortcomings of current English ASR models. The best performing model, trained on 680 thousand hours of transcribed data, obtains an average of 19.7% word error rate (WER) -- in contrast to the 2.7% WER obtained when evaluated on US English clean read speech. Across all models, we observe a drop in performance on Indian, Jamaican, and Nigerian English speakers. Recordings, linguistic backgrounds, data statement, and evaluation scripts are released on our website (https://groups.inf.ed.ac.uk/edacc/) under CC-BY-SA license.
Analyzing Acoustic Word Embeddings from Pre-trained Self-supervised Speech Models
Oct 28, 2022



Given the strong results of self-supervised models on various tasks, there have been surprisingly few studies exploring self-supervised representations for acoustic word embeddings (AWE), fixed-dimensional vectors representing variable-length spoken word segments. In this work, we study several pre-trained models and pooling methods for constructing AWEs with self-supervised representations. Owing to the contextualized nature of self-supervised representations, we hypothesize that simple pooling methods, such as averaging, might already be useful for constructing AWEs. When evaluating on a standard word discrimination task, we find that HuBERT representations with mean-pooling rival the state of the art on English AWEs. More surprisingly, despite being trained only on English, HuBERT representations evaluated on Xitsonga, Mandarin, and French consistently outperform the multilingual model XLSR-53 (as well as Wav2Vec 2.0 trained on English).
Measuring the Impact of Individual Domain Factors in Self-Supervised Pre-Training
Mar 02, 2022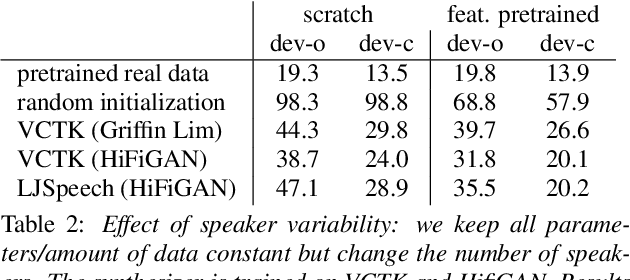
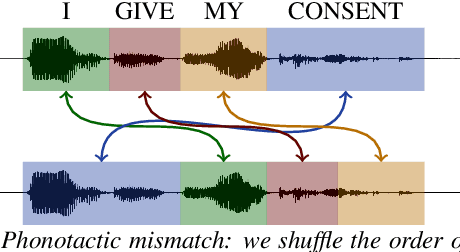

Human speech data comprises a rich set of domain factors such as accent, syntactic and semantic variety, or acoustic environment. Previous work explores the effect of domain mismatch in automatic speech recognition between pre-training and fine-tuning as a whole but does not dissect the contribution of individual factors. In this paper, we present a controlled study to better understand the effect of such factors on the performance of pre-trained representations. To do so, we pre-train models either on modified natural speech or synthesized audio, with a single domain factor modified, and then measure performance on automatic speech recognition after fine tuning. Results show that phonetic domain factors play an important role during pre-training while grammatical and syntactic factors are far less important. To our knowledge, this is the first study to better understand the domain characteristics in self-supervised pre-training for speech.
On the Difficulty of Segmenting Words with Attention
Sep 21, 2021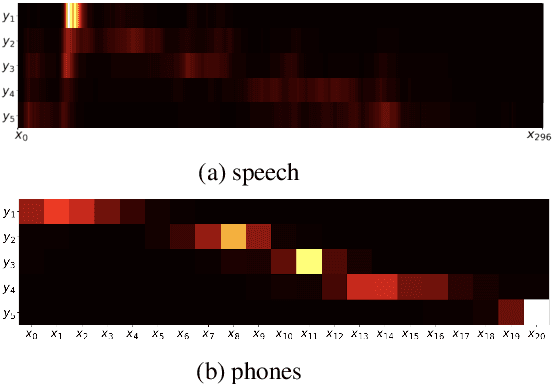

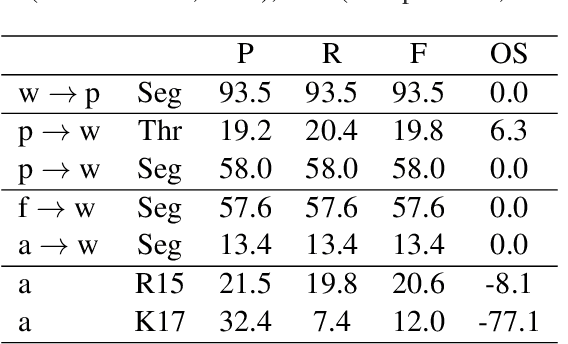
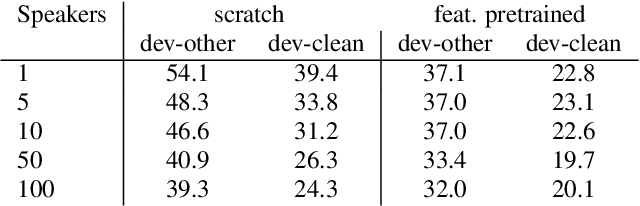
Word segmentation, the problem of finding word boundaries in speech, is of interest for a range of tasks. Previous papers have suggested that for sequence-to-sequence models trained on tasks such as speech translation or speech recognition, attention can be used to locate and segment the words. We show, however, that even on monolingual data this approach is brittle. In our experiments with different input types, data sizes, and segmentation algorithms, only models trained to predict phones from words succeed in the task. Models trained to predict words from either phones or speech (i.e., the opposite direction needed to generalize to new data), yield much worse results, suggesting that attention-based segmentation is only useful in limited scenarios.
Talk, Don't Write: A Study of Direct Speech-Based Image Retrieval
Apr 08, 2021
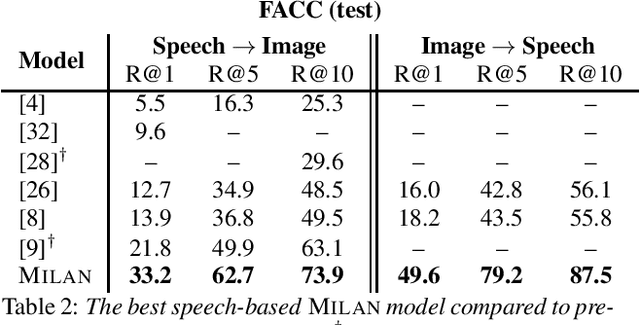
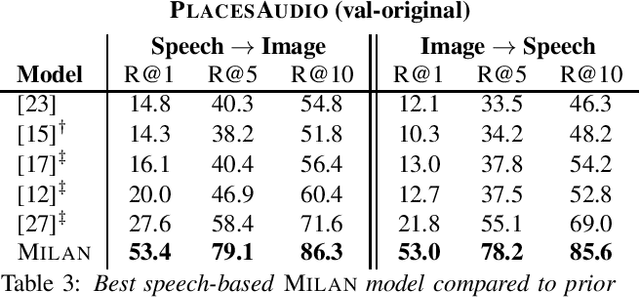
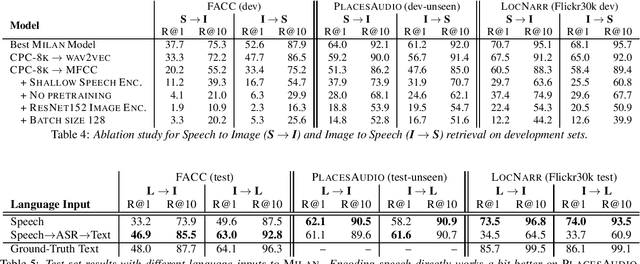
Speech-based image retrieval has been studied as a proxy for joint representation learning, usually without emphasis on retrieval itself. As such, it is unclear how well speech-based retrieval can work in practice -- both in an absolute sense and versus alternative strategies that combine automatic speech recognition (ASR) with strong text encoders. In this work, we extensively study and expand choices of encoder architectures, training methodology (including unimodal and multimodal pretraining), and other factors. Our experiments cover different types of speech in three datasets: Flickr Audio, Places Audio, and Localized Narratives. Our best model configuration achieves large gains over state of the art, e.g., pushing recall-at-one from 21.8% to 33.2% for Flickr Audio and 27.6% to 53.4% for Places Audio. We also show our best speech-based models can match or exceed cascaded ASR-to-text encoding when speech is spontaneous, accented, or otherwise hard to automatically transcribe.
Multimodal Speech Recognition with Unstructured Audio Masking
Oct 16, 2020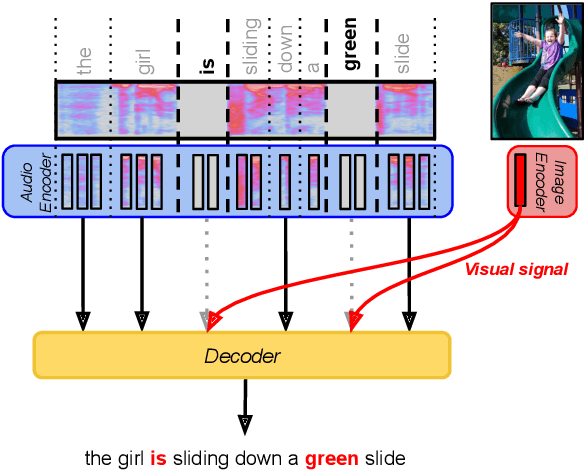
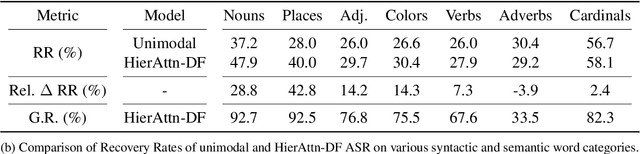
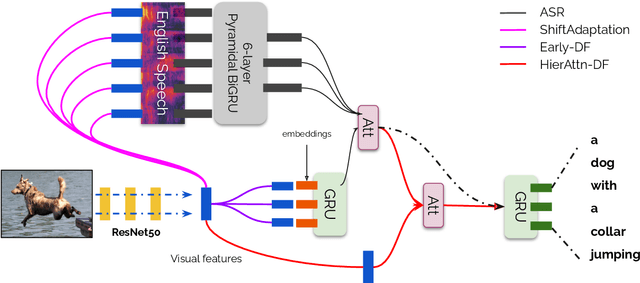
Visual context has been shown to be useful for automatic speech recognition (ASR) systems when the speech signal is noisy or corrupted. Previous work, however, has only demonstrated the utility of visual context in an unrealistic setting, where a fixed set of words are systematically masked in the audio. In this paper, we simulate a more realistic masking scenario during model training, called RandWordMask, where the masking can occur for any word segment. Our experiments on the Flickr 8K Audio Captions Corpus show that multimodal ASR can generalize to recover different types of masked words in this unstructured masking setting. Moreover, our analysis shows that our models are capable of attending to the visual signal when the audio signal is corrupted. These results show that multimodal ASR systems can leverage the visual signal in more generalized noisy scenarios.
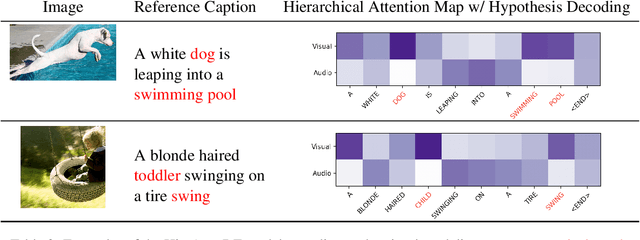
Fine-Grained Grounding for Multimodal Speech Recognition
Oct 05, 2020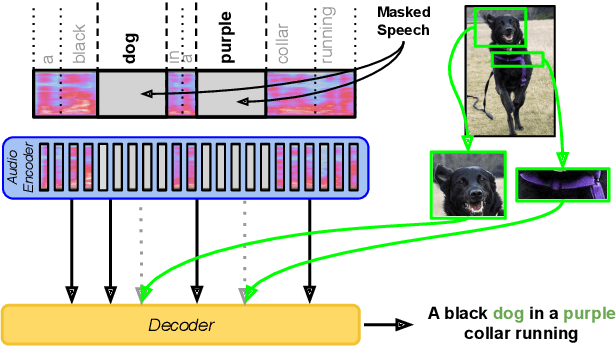
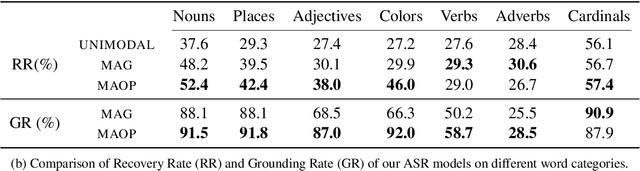
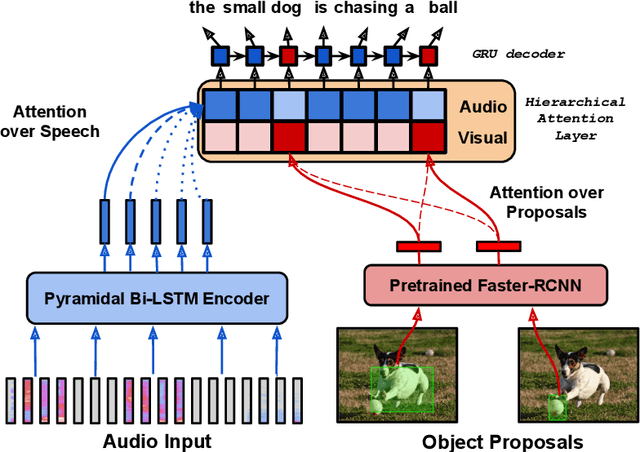
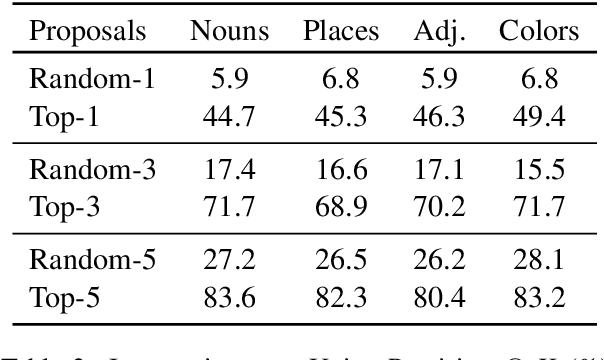
Multimodal automatic speech recognition systems integrate information from images to improve speech recognition quality, by grounding the speech in the visual context. While visual signals have been shown to be useful for recovering entities that have been masked in the audio, these models should be capable of recovering a broader range of word types. Existing systems rely on global visual features that represent the entire image, but localizing the relevant regions of the image will make it possible to recover a larger set of words, such as adjectives and verbs. In this paper, we propose a model that uses finer-grained visual information from different parts of the image, using automatic object proposals. In experiments on the Flickr8K Audio Captions Corpus, we find that our model improves over approaches that use global visual features, that the proposals enable the model to recover entities and other related words, such as adjectives, and that improvements are due to the model's ability to localize the correct proposals.