 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data
Mar 16, 2022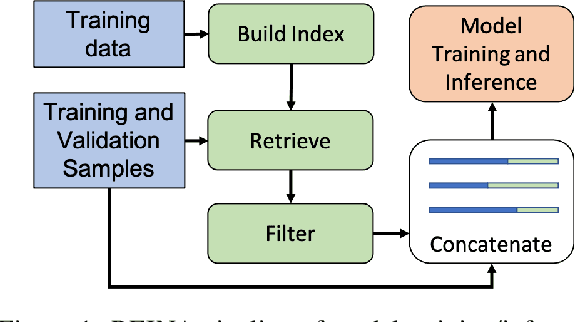
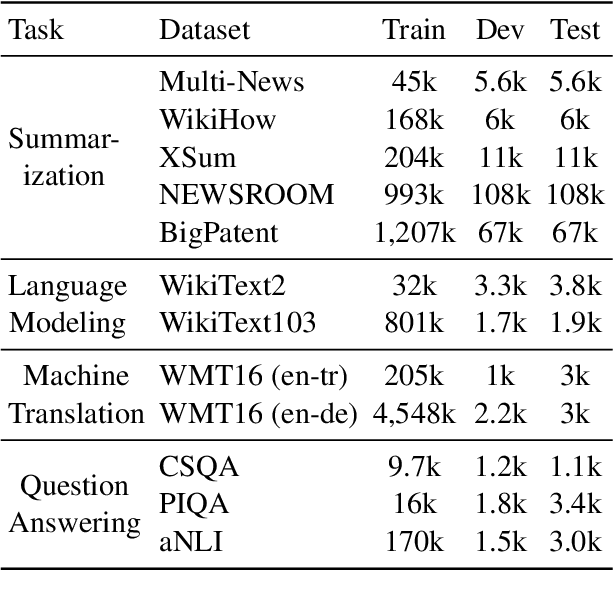
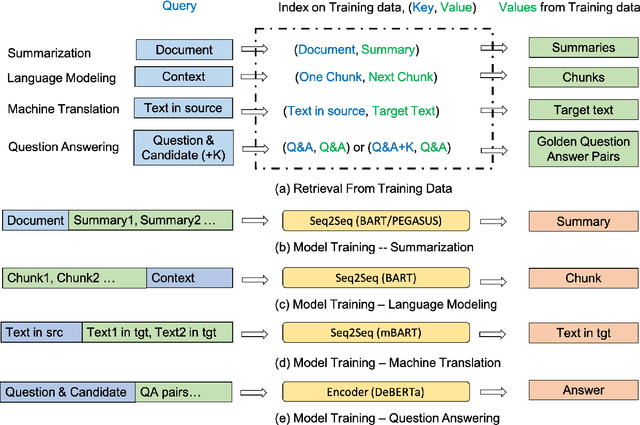
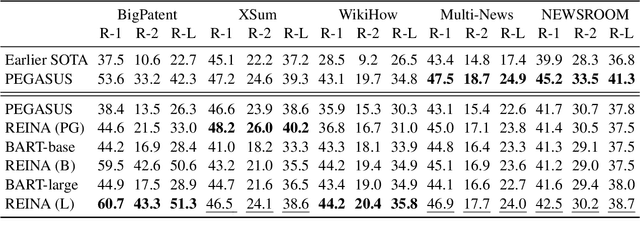
Retrieval-based methods have been shown to be effective in NLP tasks via introducing external knowledge. However, the indexing and retrieving of large-scale corpora bring considerable computational cost. Surprisingly, we found that REtrieving from the traINing datA (REINA) only can lead to significant gains on multiple NLG and NLU tasks. We retrieve the labeled training instances most similar to the input text and then concatenate them with the input to feed into the model to generate the output. Experimental results show that this simple method can achieve significantly better performance on a variety of NLU and NLG tasks, including summarization, machine translation, language modeling, and question answering tasks. For instance, our proposed method achieved state-of-the-art results on XSum, BigPatent, and CommonsenseQA. Our code is released, https://github.com/microsoft/REINA .
AdaPrompt: Adaptive Model Training for Prompt-based NLP
Feb 10, 2022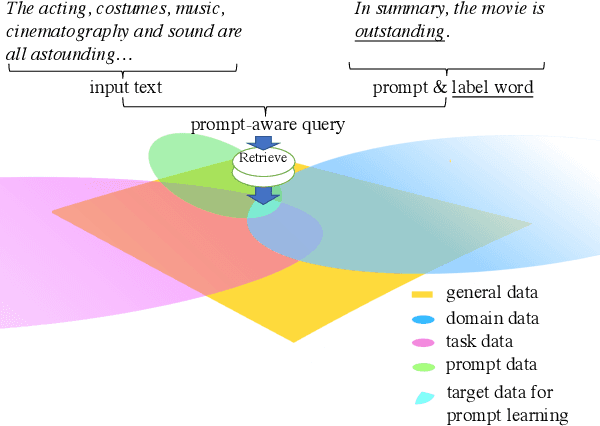

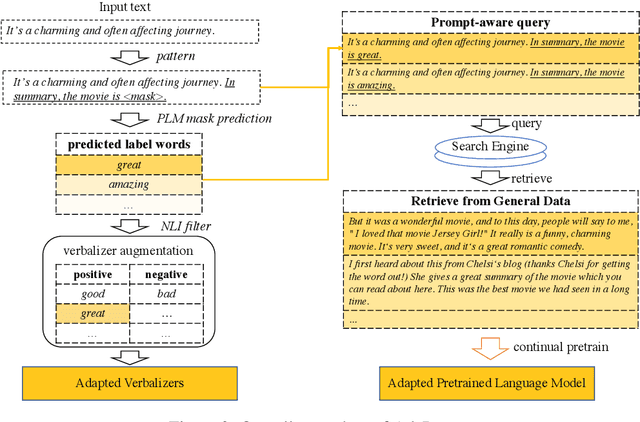
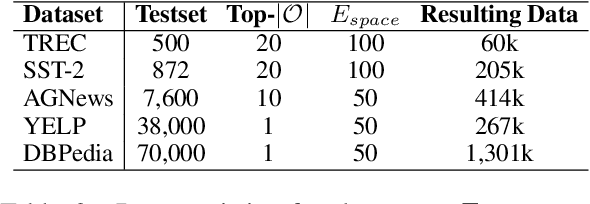
Prompt-based learning, with its capability to tackle zero-shot and few-shot NLP tasks, has gained much attention in community. The main idea is to bridge the gap between NLP downstream tasks and language modeling (LM), by mapping these tasks into natural language prompts, which are then filled by pre-trained language models (PLMs). However, for prompt learning, there are still two salient gaps between NLP tasks and pretraining. First, prompt information is not necessarily sufficiently present during LM pretraining. Second, task-specific data are not necessarily well represented during pretraining. We address these two issues by proposing AdaPrompt, adaptively retrieving external data for continual pretraining of PLMs by making use of both task and prompt characteristics. In addition, we make use of knowledge in Natural Language Inference models for deriving adaptive verbalizers. Experimental results on five NLP benchmarks show that AdaPrompt can improve over standard PLMs in few-shot settings. In addition, in zero-shot settings, our method outperforms standard prompt-based methods by up to 26.35\% relative error reduction.
CLIP-Event: Connecting Text and Images with Event Structures
Jan 13, 2022
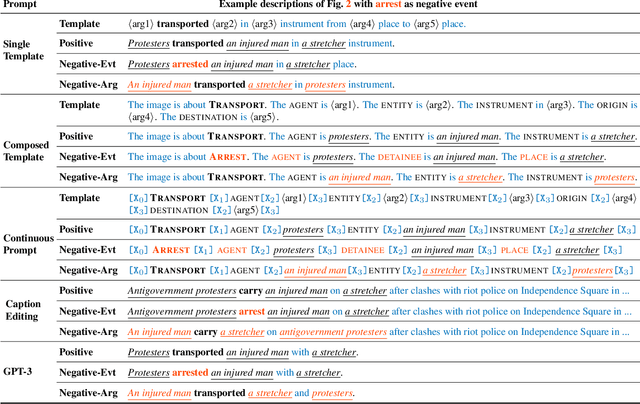
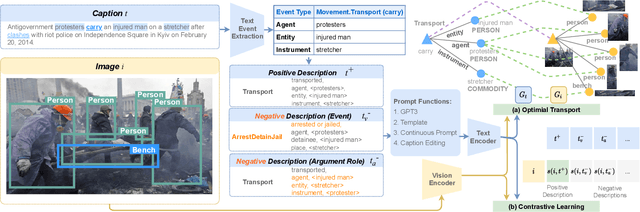

Vision-language (V+L) pretraining models have achieved great success in supporting multimedia applications by understanding the alignments between images and text. While existing vision-language pretraining models primarily focus on understanding objects in images or entities in text, they often ignore the alignment at the level of events and their argument structures. % In this work, we propose a contrastive learning framework to enforce vision-language pretraining models to comprehend events and associated argument (participant) roles. To achieve this, we take advantage of text information extraction technologies to obtain event structural knowledge, and utilize multiple prompt functions to contrast difficult negative descriptions by manipulating event structures. We also design an event graph alignment loss based on optimal transport to capture event argument structures. In addition, we collect a large event-rich dataset (106,875 images) for pretraining, which provides a more challenging image retrieval benchmark to assess the understanding of complicated lengthy sentences. Experiments show that our zero-shot CLIP-Event outperforms the state-of-the-art supervised model in argument extraction on Multimedia Event Extraction, achieving more than 5\% absolute F-score gain in event extraction, as well as significant improvements on a variety of downstream tasks under zero-shot settings.
Human Parity on CommonsenseQA: Augmenting Self-Attention with External Attention
Dec 14, 2021
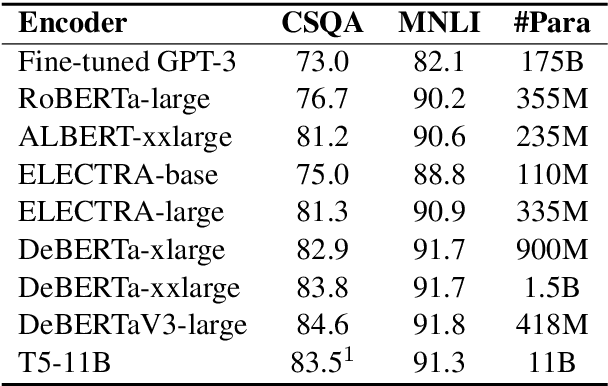
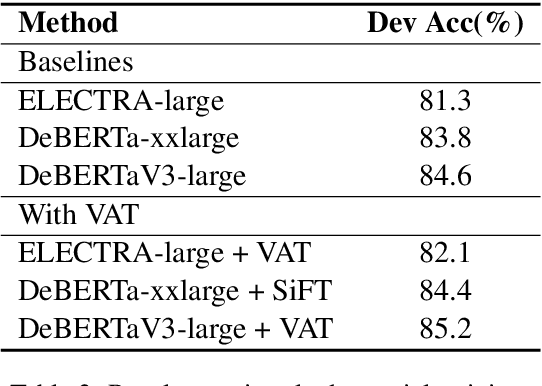

Most of today's AI systems focus on using self-attention mechanisms and transformer architectures on large amounts of diverse data to achieve impressive performance gains. In this paper, we propose to augment the transformer architecture with an external attention mechanism to bring external knowledge and context to bear. By integrating external information into the prediction process, we hope to reduce the need for ever-larger models and increase the democratization of AI systems. We find that the proposed external attention mechanism can significantly improve the performance of existing AI systems, allowing practitioners to easily customize foundation AI models to many diverse downstream applications. In particular, we focus on the task of Commonsense Reasoning, demonstrating that the proposed external attention mechanism can augment existing transformer models and significantly improve the model's reasoning capabilities. The proposed system, Knowledgeable External Attention for commonsense Reasoning (KEAR), reaches human parity on the open CommonsenseQA research benchmark with an accuracy of 89.4\% in comparison to the human accuracy of 88.9\%.
MLP Architectures for Vision-and-Language Modeling: An Empirical Study
Dec 08, 2021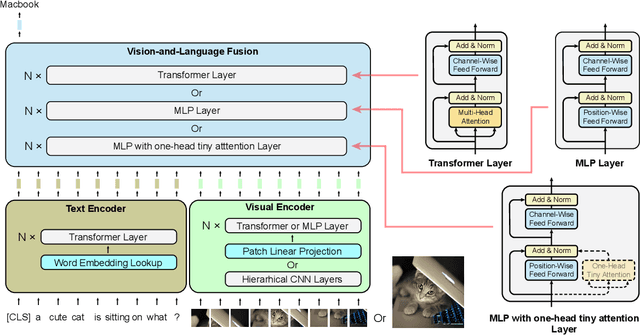
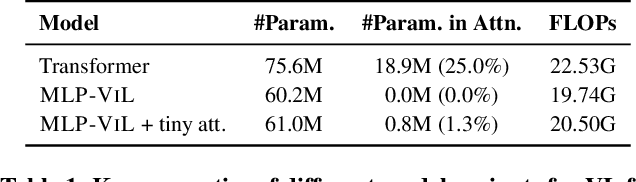
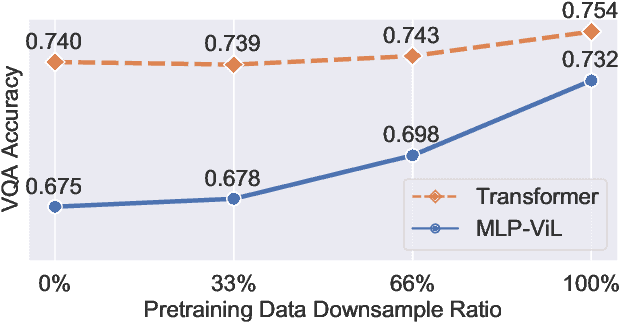
We initiate the first empirical study on the use of MLP architectures for vision-and-language (VL) fusion. Through extensive experiments on 5 VL tasks and 5 robust VQA benchmarks, we find that: (i) Without pre-training, using MLPs for multimodal fusion has a noticeable performance gap compared to transformers; (ii) However, VL pre-training can help close the performance gap; (iii) Instead of heavy multi-head attention, adding tiny one-head attention to MLPs is sufficient to achieve comparable performance to transformers. Moreover, we also find that the performance gap between MLPs and transformers is not widened when being evaluated on the harder robust VQA benchmarks, suggesting using MLPs for VL fusion can generalize roughly to a similar degree as using transformers. These results hint that MLPs can effectively learn to align vision and text features extracted from lower-level encoders without heavy reliance on self-attention. Based on this, we ask an even bolder question: can we have an all-MLP architecture for VL modeling, where both VL fusion and the vision encoder are replaced with MLPs? Our result shows that an all-MLP VL model is sub-optimal compared to state-of-the-art full-featured VL models when both of them get pre-trained. However, pre-training an all-MLP can surprisingly achieve a better average score than full-featured transformer models without pre-training. This indicates the potential of large-scale pre-training of MLP-like architectures for VL modeling and inspires the future research direction on simplifying well-established VL modeling with less inductive design bias. Our code is publicly available at: https://github.com/easonnie/mlp-vil
An Empirical Study of Training End-to-End Vision-and-Language Transformers
Nov 25, 2021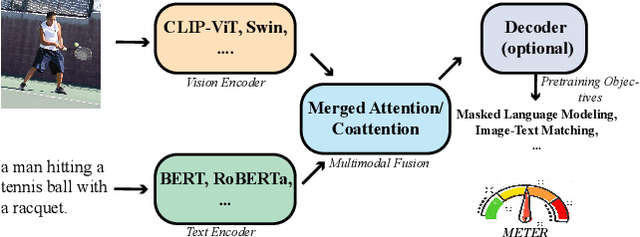

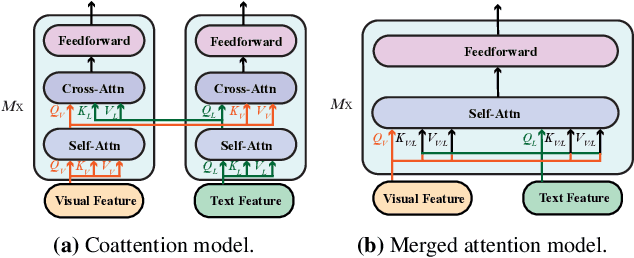

Vision-and-language (VL) pre-training has proven to be highly effective on various VL downstream tasks. While recent work has shown that fully transformer-based VL models can be more efficient than previous region-feature-based methods, their performance on downstream tasks often degrades significantly. In this paper, we present METER, a Multimodal End-to-end TransformER framework, through which we investigate how to design and pre-train a fully transformer-based VL model in an end-to-end manner. Specifically, we dissect the model designs along multiple dimensions: vision encoders (e.g., CLIPViT, Swin transformer), text encoders (e.g., RoBERTa, DeBERTa), multimodal fusion module (e.g., merged attention vs. co-attention), architectural design (e.g., encoder-only vs. encoder-decoder), and pre-training objectives (e.g., masked image modeling). We conduct comprehensive experiments and provide insights on how to train a performant VL transformer while maintaining fast inference speed. Notably, our best model achieves an accuracy of 77.64% on the VQAv2 test-std set using only 4M images for pre-training, surpassing the state-of-the-art region-feature-based model by 1.04%, and outperforming the previous best fully transformer-based model by 1.6%. Code and models are released at https://github.com/zdou0830/METER.
Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models
Nov 04, 2021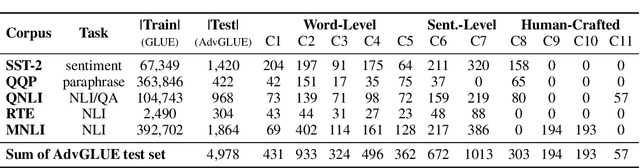
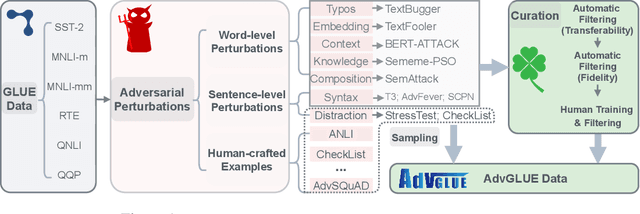


Large-scale pre-trained language models have achieved tremendous success across a wide range of natural language understanding (NLU) tasks, even surpassing human performance. However, recent studies reveal that the robustness of these models can be challenged by carefully crafted textual adversarial examples. While several individual datasets have been proposed to evaluate model robustness, a principled and comprehensive benchmark is still missing. In this paper, we present Adversarial GLUE (AdvGLUE), a new multi-task benchmark to quantitatively and thoroughly explore and evaluate the vulnerabilities of modern large-scale language models under various types of adversarial attacks. In particular, we systematically apply 14 textual adversarial attack methods to GLUE tasks to construct AdvGLUE, which is further validated by humans for reliable annotations. Our findings are summarized as follows. (i) Most existing adversarial attack algorithms are prone to generating invalid or ambiguous adversarial examples, with around 90% of them either changing the original semantic meanings or misleading human annotators as well. Therefore, we perform a careful filtering process to curate a high-quality benchmark. (ii) All the language models and robust training methods we tested perform poorly on AdvGLUE, with scores lagging far behind the benign accuracy. We hope our work will motivate the development of new adversarial attacks that are more stealthy and semantic-preserving, as well as new robust language models against sophisticated adversarial attacks. AdvGLUE is available at https://adversarialglue.github.io.
Leveraging Knowledge in Multilingual Commonsense Reasoning
Oct 16, 2021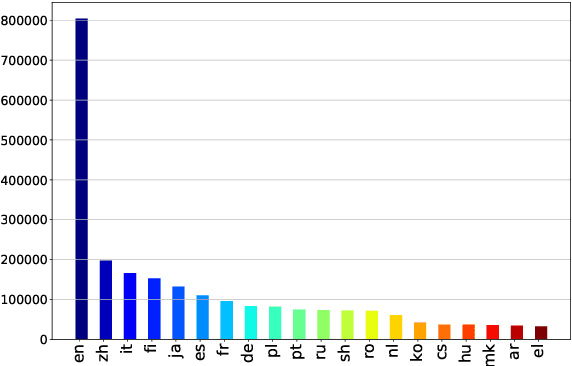

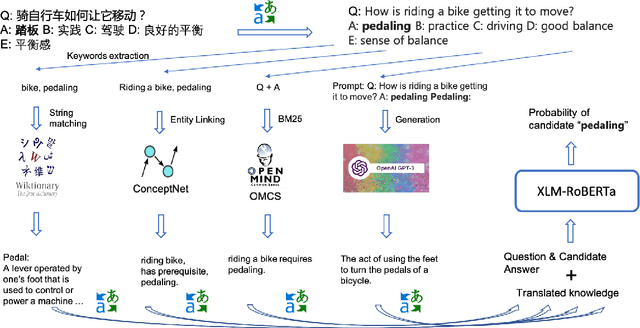
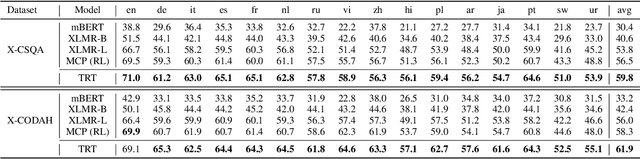
Commonsense reasoning (CSR) requires the model to be equipped with general world knowledge. While CSR is a language-agnostic process, most comprehensive knowledge sources are in few popular languages, especially English. Thus, it remains unclear how to effectively conduct multilingual commonsense reasoning (XCSR) for various languages. In this work, we propose to utilize English knowledge sources via a translate-retrieve-translate (TRT) strategy. For multilingual commonsense questions and choices, we collect related knowledge via translation and retrieval from the knowledge sources. The retrieved knowledge is then translated into the target language and integrated into a pre-trained multilingual language model via visible knowledge attention. Then we utilize a diverse of 4 English knowledge sources to provide more comprehensive coverage of knowledge in different formats. Extensive results on the XCSR benchmark demonstrate that TRT with external knowledge can significantly improve multilingual commonsense reasoning in both zero-shot and translate-train settings, outperforming 3.3 and 3.6 points over the previous state-of-the-art on XCSR benchmark datasets (X-CSQA and X-CODAH).
NOAHQA: Numerical Reasoning with Interpretable Graph Question Answering Dataset
Oct 14, 2021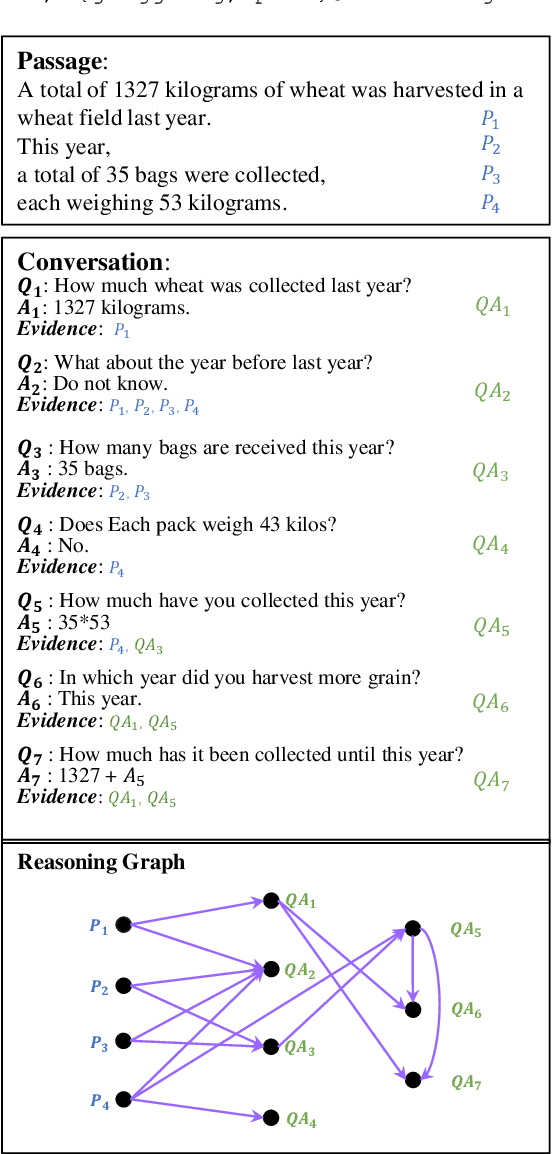

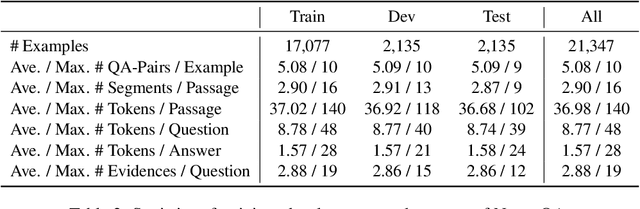
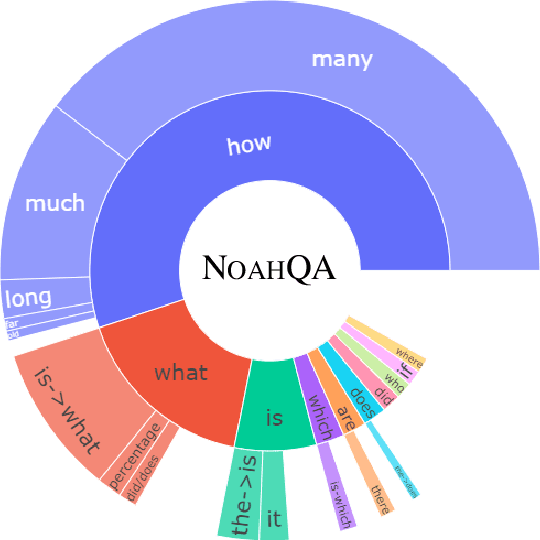
While diverse question answering (QA) datasets have been proposed and contributed significantly to the development of deep learning models for QA tasks, the existing datasets fall short in two aspects. First, we lack QA datasets covering complex questions that involve answers as well as the reasoning processes to get the answers. As a result, the state-of-the-art QA research on numerical reasoning still focuses on simple calculations and does not provide the mathematical expressions or evidences justifying the answers. Second, the QA community has contributed much effort to improving the interpretability of QA models. However, these models fail to explicitly show the reasoning process, such as the evidence order for reasoning and the interactions between different pieces of evidence. To address the above shortcomings, we introduce NOAHQA, a conversational and bilingual QA dataset with questions requiring numerical reasoning with compound mathematical expressions. With NOAHQA, we develop an interpretable reasoning graph as well as the appropriate evaluation metric to measure the answer quality. We evaluate the state-of-the-art QA models trained using existing QA datasets on NOAHQA and show that the best among them can only achieve 55.5 exact match scores, while the human performance is 89.7. We also present a new QA model for generating a reasoning graph where the reasoning graph metric still has a large gap compared with that of humans, e.g., 28 scores.
Dict-BERT: Enhancing Language Model Pre-training with Dictionary
Oct 13, 2021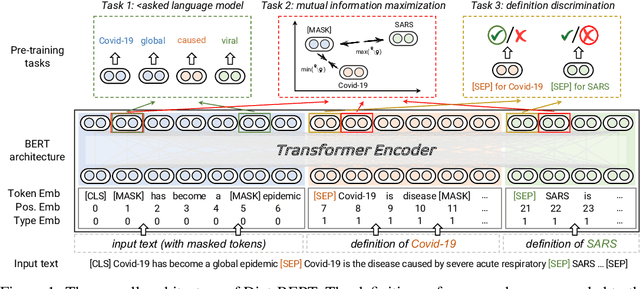
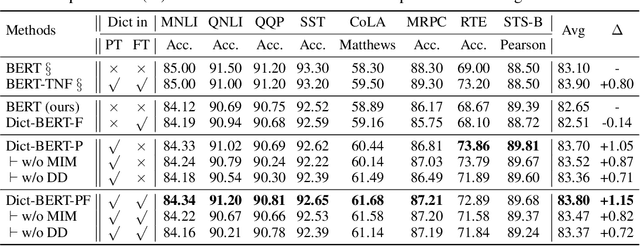
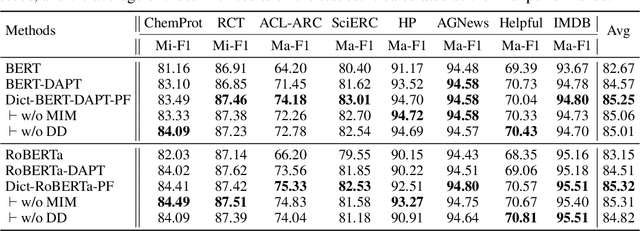
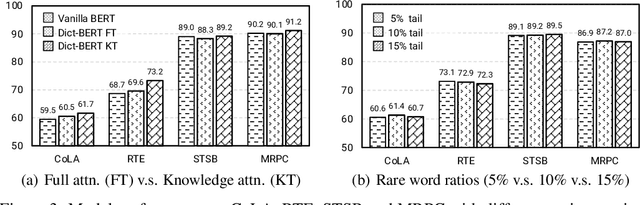
Pre-trained language models (PLMs) aim to learn universal language representations by conducting self-supervised training tasks on large-scale corpora. Since PLMs capture word semantics in different contexts, the quality of word representations highly depends on word frequency, which usually follows a heavy-tailed distributions in the pre-training corpus. Therefore, the embeddings of rare words on the tail are usually poorly optimized. In this work, we focus on enhancing language model pre-training by leveraging definitions of the rare words in dictionaries (e.g., Wiktionary). To incorporate a rare word definition as a part of input, we fetch its definition from the dictionary and append it to the end of the input text sequence. In addition to training with the masked language modeling objective, we propose two novel self-supervised pre-training tasks on word and sentence-level alignment between input text sequence and rare word definitions to enhance language modeling representation with dictionary. We evaluate the proposed Dict-BERT model on the language understanding benchmark GLUE and eight specialized domain benchmark datasets. Extensive experiments demonstrate that Dict-BERT can significantly improve the understanding of rare words and boost model performance on various NLP downstream tasks.