 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
Paper and Code
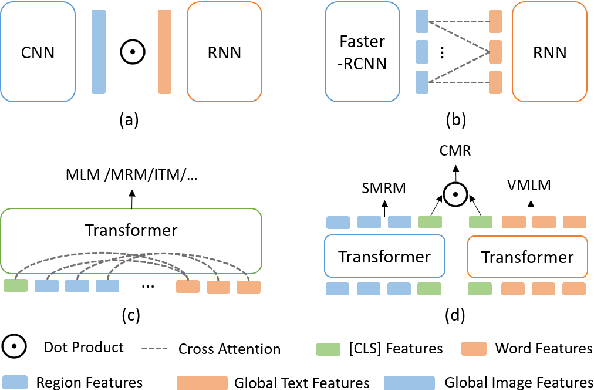
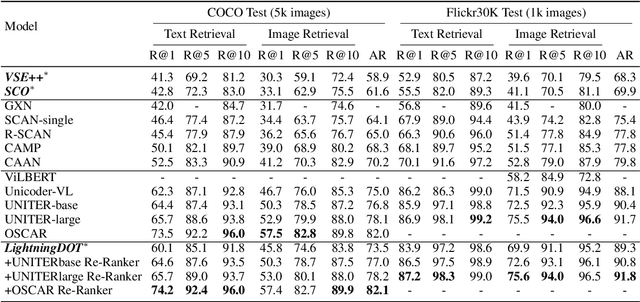
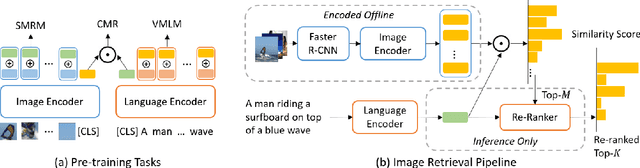

Multimodal pre-training has propelled great advancement in vision-and-language research. These large-scale pre-trained models, although successful, fatefully suffer from slow inference speed due to enormous computation cost mainly from cross-modal attention in Transformer architecture. When applied to real-life applications, such latency and computation demand severely deter the practical use of pre-trained models. In this paper, we study Image-text retrieval (ITR), the most mature scenario of V+L application, which has been widely studied even prior to the emergence of recent pre-trained models. We propose a simple yet highly effective approach, LightningDOT that accelerates the inference time of ITR by thousands of times, without sacrificing accuracy. LightningDOT removes the time-consuming cross-modal attention by pre-training on three novel learning objectives, extracting feature indexes offline, and employing instant dot-product matching with further re-ranking, which significantly speeds up retrieval process. In fact, LightningDOT achieves new state of the art across multiple ITR benchmarks such as Flickr30k, COCO and Multi30K, outperforming existing pre-trained models that consume 1000x magnitude of computational hours. Code and pre-training checkpoints are available at https://github.com/intersun/LightningDOT.