 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Human-Like Translation Strategy with Large Language Models
May 06, 2023Large language models (LLMs) have demonstrated impressive capabilities in general scenarios, exhibiting a level of aptitude that approaches, in some aspects even surpasses, human-level intelligence. Among their numerous skills, the translation abilities of LLMs have received considerable attention. In contrast to traditional machine translation that focuses solely on source-target mapping, LLM-based translation can potentially mimic the human translation process that takes many preparatory steps to ensure high-quality translation. This work aims to explore this possibility by proposing the MAPS framework, which stands for Multi-Aspect Prompting and Selection. Specifically, we enable LLMs to first analyze the given source text and extract three aspects of translation-related knowledge: keywords, topics and relevant demonstrations to guide the translation process. To filter out the noisy and unhelpful knowledge, we employ a selection mechanism based on quality estimation. Experiments suggest that MAPS brings significant and consistent improvements over text-davinci-003 and Alpaca on eight translation directions from the latest WMT22 test sets. Our further analysis shows that the extracted knowledge is critical in resolving up to 59% of hallucination mistakes in translation. Code is available at https://github.com/zwhe99/MAPS-mt.
ParroT: Translating During Chat Using Large Language Models
Apr 20, 2023



Large language models (LLMs) like ChatGPT and GPT-4 have exhibited remarkable abilities on a wide range of natural language processing (NLP) tasks, including various machine translation abilities accomplished during chat. However, these models are only accessible through restricted APIs, which creates barriers to new research and advancements in the field. Therefore, we propose the $\mathbf{ParroT}$ framework to enhance and regulate the translation abilities during chat based on open-sourced LLMs (i.e., LLaMA-7b, BLOOMZ-7b-mt) and human written translation and evaluation data. Specifically, ParroT reformulates translation data into the instruction-following style, and introduces a "$\mathbf{Hint}$" field for incorporating extra requirements to regulate the translation process. Accordingly, we propose three instruction types for finetuning ParroT models, including translation instruction, contrastive instruction, and error-guided instruction. We can finetune either the full models or partial parameters via low rank adaptation (LoRA). Experiments on Flores subsets and WMT22 test sets suggest that translation instruction improves the translation performance of vanilla LLMs significantly while error-guided instruction can lead to a further improvement, which demonstrates the importance of learning from low-quality translations annotated by human. Meanwhile, the ParroT models can also preserve the ability on general tasks with the Alpaca multi-task dataset involved in finetuning. Please refer to our Github project for more implementation details: https://github.com/wxjiao/ParroT
Exploring the Use of Large Language Models for Reference-Free Text Quality Evaluation: A Preliminary Empirical Study
Apr 10, 2023Evaluating the quality of generated text is a challenging task in natural language processing. This difficulty arises from the inherent complexity and diversity of text. Recently, OpenAI's ChatGPT, a powerful large language model (LLM), has garnered significant attention due to its impressive performance in various tasks. Therefore, we present this report to investigate the effectiveness of LLMs, especially ChatGPT, and explore ways to optimize their use in assessing text quality. We compared three kinds of reference-free evaluation methods based on ChatGPT or similar LLMs. The experimental results prove that ChatGPT is capable to evaluate text quality effectively from various perspectives without reference and demonstrates superior performance than most existing automatic metrics. In particular, the Explicit Score, which utilizes ChatGPT to generate a numeric score measuring text quality, is the most effective and reliable method among the three exploited approaches. However, directly comparing the quality of two texts using ChatGPT may lead to suboptimal results. We hope this report will provide valuable insights into selecting appropriate methods for evaluating text quality with LLMs such as ChatGPT.
Document-Level Machine Translation with Large Language Models
Apr 05, 2023



Large language models (LLMs) such as Chat-GPT can produce coherent, cohesive, relevant, and fluent answers for various natural language processing (NLP) tasks. Taking document-level machine translation (MT) as a testbed, this paper provides an in-depth evaluation of LLMs' ability on discourse modeling. The study fo-cuses on three aspects: 1) Effects of Discourse-Aware Prompts, where we investigate the impact of different prompts on document-level translation quality and discourse phenomena; 2) Comparison of Translation Models, where we compare the translation performance of Chat-GPT with commercial MT systems and advanced document-level MT methods; 3) Analysis of Discourse Modelling Abilities, where we further probe discourse knowledge encoded in LLMs and examine the impact of training techniques on discourse modeling. By evaluating a number of benchmarks, we surprisingly find that 1) leveraging their powerful long-text mod-eling capabilities, ChatGPT outperforms commercial MT systems in terms of human evaluation. 2) GPT-4 demonstrates a strong ability to explain discourse knowledge, even through it may select incorrect translation candidates in contrastive testing. 3) ChatGPT and GPT-4 have demonstrated superior performance and show potential to become a new and promising paradigm for document-level translation. This work highlights the challenges and opportunities of discourse modeling for LLMs, which we hope can inspire the future design and evaluation of LLMs.
Is ChatGPT A Good Keyphrase Generator? A Preliminary Study
Mar 23, 2023



The emergence of ChatGPT has recently garnered significant attention from the computational linguistics community. To demonstrate its capabilities as a keyphrase generator, we conduct a preliminary evaluation of ChatGPT for the keyphrase generation task. We evaluate its performance in various aspects, including keyphrase generation prompts, keyphrase generation diversity, multi-domain keyphrase generation, and long document understanding. Our evaluation is based on six benchmark datasets, and we adopt the prompt suggested by OpenAI while extending it to six candidate prompts. We find that ChatGPT performs exceptionally well on all six candidate prompts, with minor performance differences observed across the datasets. Based on our findings, we conclude that ChatGPT has great potential for keyphrase generation. Moreover, we discover that ChatGPT still faces challenges when it comes to generating absent keyphrases. Meanwhile, in the final section, we also present some limitations and future expansions of this report.
Zero-Shot Rumor Detection with Propagation Structure via Prompt Learning
Dec 02, 2022



The spread of rumors along with breaking events seriously hinders the truth in the era of social media. Previous studies reveal that due to the lack of annotated resources, rumors presented in minority languages are hard to be detected. Furthermore, the unforeseen breaking events not involved in yesterday's news exacerbate the scarcity of data resources. In this work, we propose a novel zero-shot framework based on prompt learning to detect rumors falling in different domains or presented in different languages. More specifically, we firstly represent rumor circulated on social media as diverse propagation threads, then design a hierarchical prompt encoding mechanism to learn language-agnostic contextual representations for both prompts and rumor data. To further enhance domain adaptation, we model the domain-invariant structural features from the propagation threads, to incorporate structural position representations of influential community response. In addition, a new virtual response augmentation method is used to improve model training. Extensive experiments conducted on three real-world datasets demonstrate that our proposed model achieves much better performance than state-of-the-art methods and exhibits a superior capacity for detecting rumors at early stages.
Tencent's Multilingual Machine Translation System for WMT22 Large-Scale African Languages
Oct 18, 2022
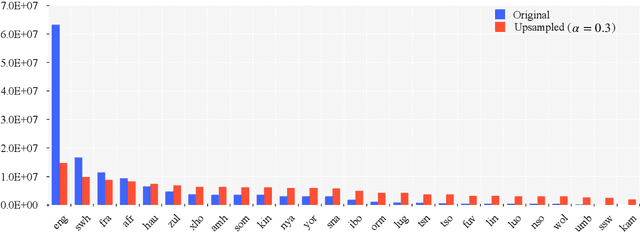


This paper describes Tencent's multilingual machine translation systems for the WMT22 shared task on Large-Scale Machine Translation Evaluation for African Languages. We participated in the $\mathbf{constrained}$ translation track in which only the data and pretrained models provided by the organizer are allowed. The task is challenging due to three problems, including the absence of training data for some to-be-evaluated language pairs, the uneven optimization of language pairs caused by data imbalance, and the curse of multilinguality. To address these problems, we adopt data augmentation, distributionally robust optimization, and language family grouping, respectively, to develop our multilingual neural machine translation (MNMT) models. Our submissions won the $\mathbf{1st\ place}$ on the blind test sets in terms of the automatic evaluation metrics. Codes, models, and detailed competition results are available at https://github.com/wxjiao/WMT2022-Large-Scale-African.
Tencent AI Lab - Shanghai Jiao Tong University Low-Resource Translation System for the WMT22 Translation Task
Oct 17, 2022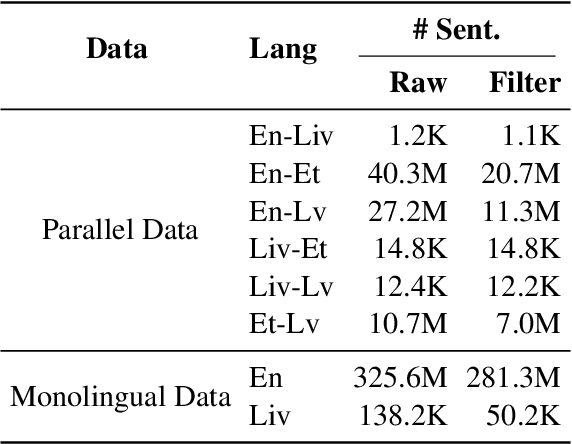
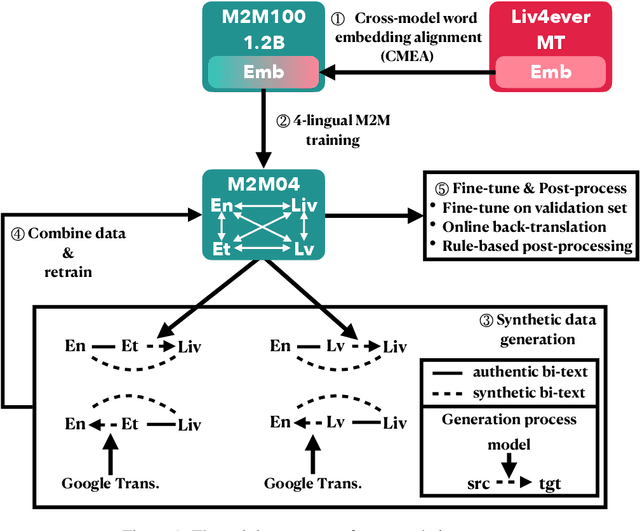
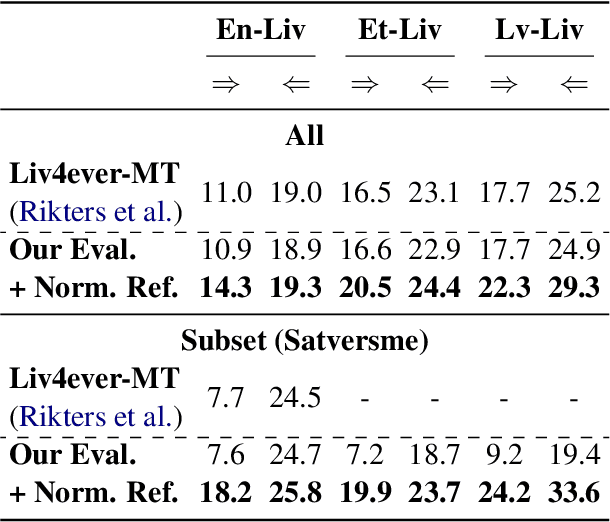
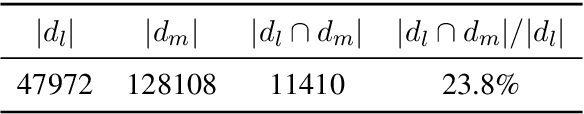
This paper describes Tencent AI Lab - Shanghai Jiao Tong University (TAL-SJTU) Low-Resource Translation systems for the WMT22 shared task. We participate in the general translation task on English$\Leftrightarrow$Livonian. Our system is based on M2M100 with novel techniques that adapt it to the target language pair. (1) Cross-model word embedding alignment: inspired by cross-lingual word embedding alignment, we successfully transfer a pre-trained word embedding to M2M100, enabling it to support Livonian. (2) Gradual adaptation strategy: we exploit Estonian and Latvian as auxiliary languages for many-to-many translation training and then adapt to English-Livonian. (3) Data augmentation: to enlarge the parallel data for English-Livonian, we construct pseudo-parallel data with Estonian and Latvian as pivot languages. (4) Fine-tuning: to make the most of all available data, we fine-tune the model with the validation set and online back-translation, further boosting the performance. In model evaluation: (1) We find that previous work underestimated the translation performance of Livonian due to inconsistent Unicode normalization, which may cause a discrepancy of up to 14.9 BLEU score. (2) In addition to the standard validation set, we also employ round-trip BLEU to evaluate the models, which we find more appropriate for this task. Finally, our unconstrained system achieves BLEU scores of 17.0 and 30.4 for English to/from Livonian.
Effidit: Your AI Writing Assistant
Aug 04, 2022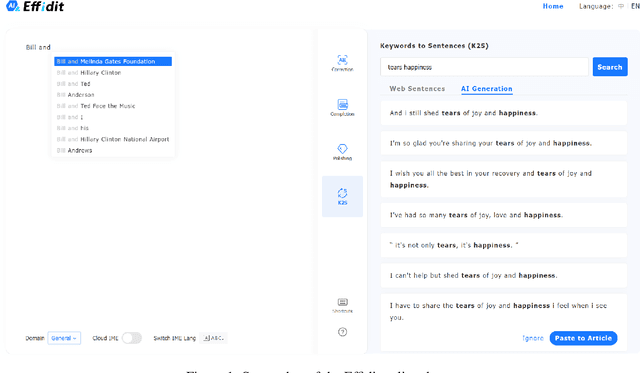

In this technical report, we introduce Effidit (Efficient and Intelligent Editing), a digital writing assistant that facilitates users to write higher-quality text more efficiently by using artificial intelligence (AI) technologies. Previous writing assistants typically provide the function of error checking (to detect and correct spelling and grammatical errors) and limited text-rewriting functionality. With the emergence of large-scale neural language models, some systems support automatically completing a sentence or a paragraph. In Effidit, we significantly expand the capacities of a writing assistant by providing functions in five categories: text completion, error checking, text polishing, keywords to sentences (K2S), and cloud input methods (cloud IME). In the text completion category, Effidit supports generation-based sentence completion, retrieval-based sentence completion, and phrase completion. In contrast, many other writing assistants so far only provide one or two of the three functions. For text polishing, we have three functions: (context-aware) phrase polishing, sentence paraphrasing, and sentence expansion, whereas many other writing assistants often support one or two functions in this category. The main contents of this report include major modules of Effidit, methods for implementing these modules, and evaluation results of some key methods.
One Model, Multiple Modalities: A Sparsely Activated Approach for Text, Sound, Image, Video and Code
May 12, 2022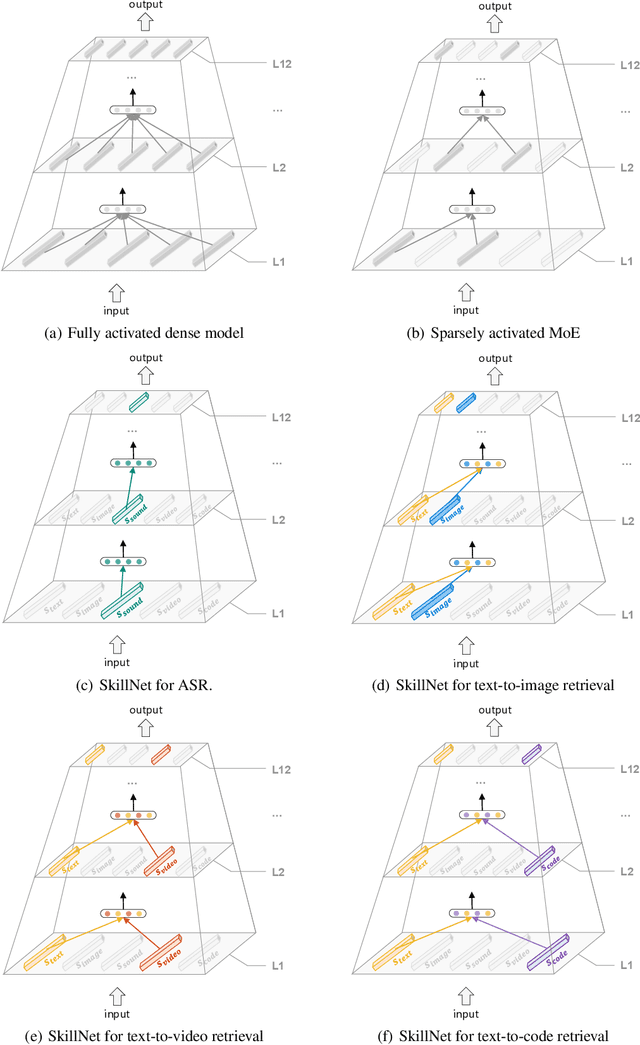

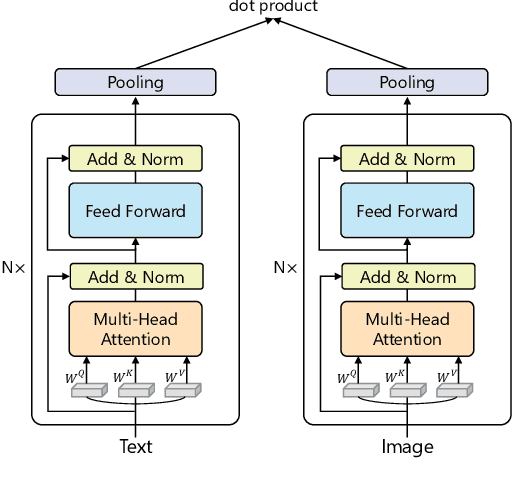
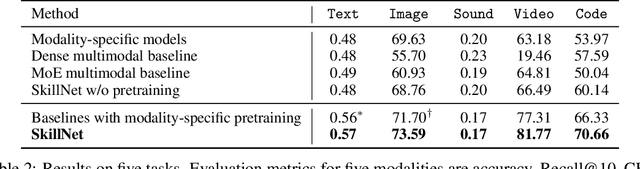
People perceive the world with multiple senses (e.g., through hearing sounds, reading words and seeing objects). However, most existing AI systems only process an individual modality. This paper presents an approach that excels at handling multiple modalities of information with a single model. In our "{SkillNet}" model, different parts of the parameters are specialized for processing different modalities. Unlike traditional dense models that always activate all the model parameters, our model sparsely activates parts of the parameters whose skills are relevant to the task. Such model design enables SkillNet to learn skills in a more interpretable way. We develop our model for five modalities including text, image, sound, video and code. Results show that, SkillNet performs comparably to five modality-specific fine-tuned models. Moreover, our model supports self-supervised pretraining with the same sparsely activated way, resulting in better initialized parameters for different modalities. We find that pretraining significantly improves the performance of SkillNet on five modalities, on par with or even better than baselines with modality-specific pretraining. On the task of Chinese text-to-image retrieval, our final system achieves higher accuracy than existing leading systems including Wukong{ViT-B} and Wenlan 2.0 while using less number of activated parameters.