 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistRM: Improving Generative Reward Models via Consistency-Aware Self-Training
Apr 08, 2026Generative reward models (GRMs) have emerged as a promising approach for aligning Large Language Models (LLMs) with human preferences by offering greater representational capacity and flexibility than traditional scalar reward models. However, GRMs face two major challenges: reliance on costly human-annotated data restricts scalability, and self-training approaches often suffer from instability and vulnerability to reward hacking. To address these issues, we propose ConsistRM, a self-training framework that enables effective and stable GRM training without human annotations. ConsistRM incorporates the Consistency-Aware Answer Reward, which produces reliable pseudo-labels with temporal consistency, thereby providing more stable model optimization. Moreover, the Consistency-Aware Critique Reward is introduced to assess semantic consistency across multiple critiques and allocates fine-grained and differentiated rewards. Experiments on five benchmark datasets across four base models demonstrate that ConsistRM outperforms vanilla Reinforcement Fine-Tuning (RFT) by an average of 1.5%. Further analysis shows that ConsistRM enhances output consistency and mitigates position bias caused by input order, highlighting the effectiveness of consistency-aware rewards in improving GRMs.
ReflectRM: Boosting Generative Reward Models via Self-Reflection within a Unified Judgment Framework
Apr 08, 2026Reward Models (RMs) are critical components in the Reinforcement Learning from Human Feedback (RLHF) pipeline, directly determining the alignment quality of Large Language Models (LLMs). Recently, Generative Reward Models (GRMs) have emerged as a superior paradigm, offering higher interpretability and stronger generalization than traditional scalar RMs. However, existing methods for GRMs focus primarily on outcome-level supervision, neglecting analytical process quality, which constrains their potential. To address this, we propose ReflectRM, a novel GRM that leverages self-reflection to assess analytical quality and enhance preference modeling. ReflectRM is trained under a unified generative framework for joint modeling of response preference and analysis preference. During inference, we use its self-reflection capability to identify the most reliable analysis, from which the final preference prediction is derived. Experiments across four benchmarks show that ReflectRM consistently improves performance, achieving an average accuracy gain of +3.7 on Qwen3-4B. Further experiments confirm that response preference and analysis preference are mutually reinforcing. Notably, ReflectRM substantially mitigates positional bias, yielding +10.2 improvement compared with leading GRMs and establishing itself as a more stable evaluator.
SelectIT: Selective Instruction Tuning for Large Language Models via Uncertainty-Aware Self-Reflection
Feb 26, 2024



Instruction tuning (IT) is crucial to tailoring large language models (LLMs) towards human-centric interactions. Recent advancements have shown that the careful selection of a small, high-quality subset of IT data can significantly enhance the performance of LLMs. Despite this, common approaches often rely on additional models or data sets, which increases costs and limits widespread adoption. In this work, we propose a novel approach, termed SelectIT, that capitalizes on the foundational capabilities of the LLM itself. Specifically, we exploit the intrinsic uncertainty present in LLMs to more effectively select high-quality IT data, without the need for extra resources. Furthermore, we introduce a novel IT dataset, the Selective Alpaca, created by applying SelectIT to the Alpaca-GPT4 dataset. Empirical results demonstrate that IT using Selective Alpaca leads to substantial model ability enhancement. The robustness of SelectIT has also been corroborated in various foundation models and domain-specific tasks. Our findings suggest that longer and more computationally intensive IT data may serve as superior sources of IT, offering valuable insights for future research in this area. Data, code, and scripts are freely available at https://github.com/Blue-Raincoat/SelectIT.
Emage: Non-Autoregressive Text-to-Image Generation
Dec 22, 2023Autoregressive and diffusion models drive the recent breakthroughs on text-to-image generation. Despite their huge success of generating high-realistic images, a common shortcoming of these models is their high inference latency - autoregressive models run more than a thousand times successively to produce image tokens and diffusion models convert Gaussian noise into images with many hundreds of denoising steps. In this work, we explore non-autoregressive text-to-image models that efficiently generate hundreds of image tokens in parallel. We develop many model variations with different learning and inference strategies, initialized text encoders, etc. Compared with autoregressive baselines that needs to run one thousand times, our model only runs 16 times to generate images of competitive quality with an order of magnitude lower inference latency. Our non-autoregressive model with 346M parameters generates an image of 256$\times$256 with about one second on one V100 GPU.
One Model, Multiple Modalities: A Sparsely Activated Approach for Text, Sound, Image, Video and Code
May 12, 2022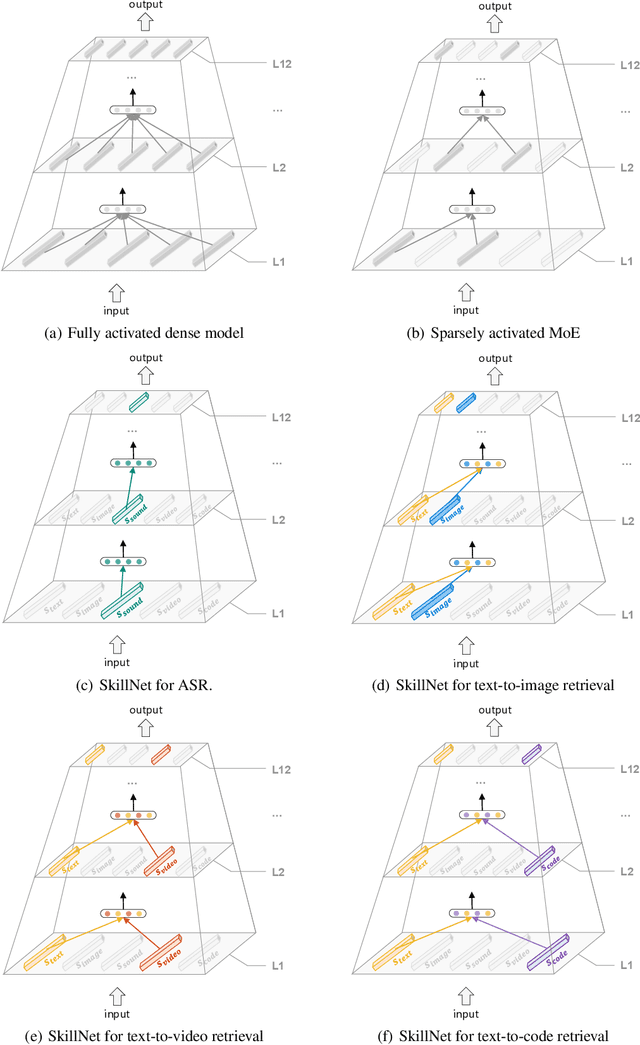

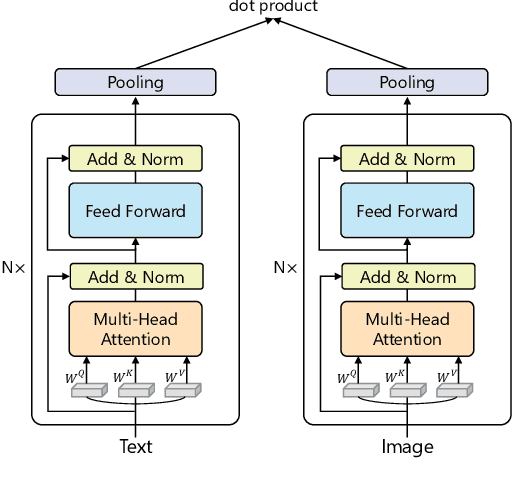
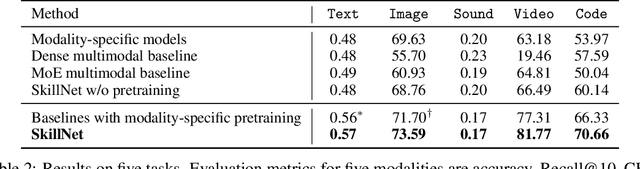
People perceive the world with multiple senses (e.g., through hearing sounds, reading words and seeing objects). However, most existing AI systems only process an individual modality. This paper presents an approach that excels at handling multiple modalities of information with a single model. In our "{SkillNet}" model, different parts of the parameters are specialized for processing different modalities. Unlike traditional dense models that always activate all the model parameters, our model sparsely activates parts of the parameters whose skills are relevant to the task. Such model design enables SkillNet to learn skills in a more interpretable way. We develop our model for five modalities including text, image, sound, video and code. Results show that, SkillNet performs comparably to five modality-specific fine-tuned models. Moreover, our model supports self-supervised pretraining with the same sparsely activated way, resulting in better initialized parameters for different modalities. We find that pretraining significantly improves the performance of SkillNet on five modalities, on par with or even better than baselines with modality-specific pretraining. On the task of Chinese text-to-image retrieval, our final system achieves higher accuracy than existing leading systems including Wukong{ViT-B} and Wenlan 2.0 while using less number of activated parameters.