 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAFNet: An Efficient Anchor-Free Object Detector Guidance
Apr 28, 2021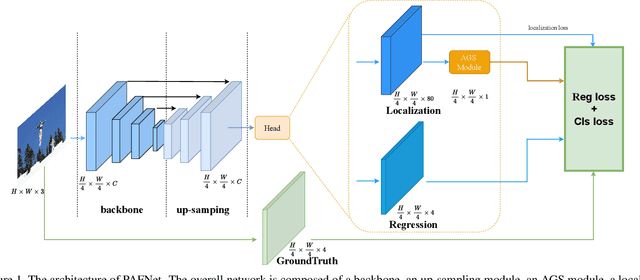
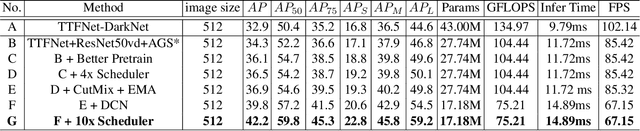

Object detection is a basic but challenging task in computer vision, which plays a key role in a variety of industrial applications. However, object detectors based on deep learning usually require greater storage requirements and longer inference time, which hinders its practicality seriously. Therefore, a trade-off between effectiveness and efficiency is necessary in practical scenarios. Considering that without constraint of pre-defined anchors, anchor-free detectors can achieve acceptable accuracy and inference speed simultaneously. In this paper, we start from an anchor-free detector called TTFNet, modify the structure of TTFNet and introduce multiple existing tricks to realize effective server and mobile solutions respectively. Since all experiments in this paper are conducted based on PaddlePaddle, we call the model as PAFNet(Paddle Anchor Free Network). For server side, PAFNet can achieve a better balance between effectiveness (42.2% mAP) and efficiency (67.15 FPS) on a single V100 GPU. For moblie side, PAFNet-lite can achieve a better accuracy of (23.9% mAP) and 26.00 ms on Kirin 990 ARM CPU, outperforming the existing state-of-the-art anchor-free detectors by significant margins. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
PP-YOLOv2: A Practical Object Detector
Apr 21, 2021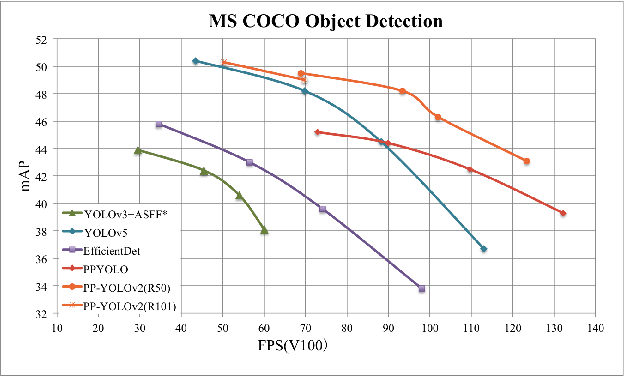

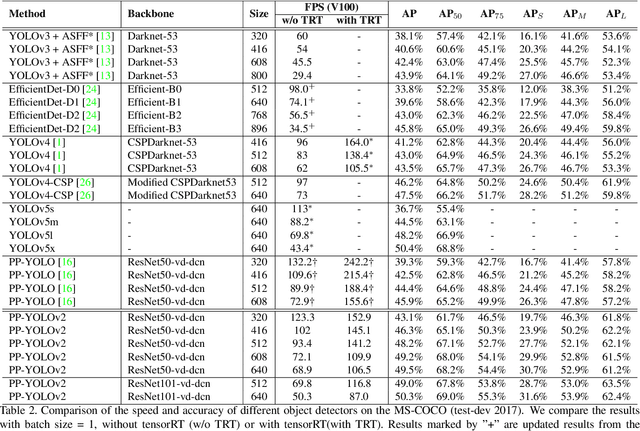
Being effective and efficient is essential to an object detector for practical use. To meet these two concerns, we comprehensively evaluate a collection of existing refinements to improve the performance of PP-YOLO while almost keep the infer time unchanged. This paper will analyze a collection of refinements and empirically evaluate their impact on the final model performance through incremental ablation study. Things we tried that didn't work will also be discussed. By combining multiple effective refinements, we boost PP-YOLO's performance from 45.9% mAP to 49.5% mAP on COCO2017 test-dev. Since a significant margin of performance has been made, we present PP-YOLOv2. In terms of speed, PP-YOLOv2 runs in 68.9FPS at 640x640 input size. Paddle inference engine with TensorRT, FP16-precision, and batch size = 1 further improves PP-YOLOv2's infer speed, which achieves 106.5 FPS. Such a performance surpasses existing object detectors with roughly the same amount of parameters (i.e., YOLOv4-CSP, YOLOv5l). Besides, PP-YOLOv2 with ResNet101 achieves 50.3% mAP on COCO2017 test-dev. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Student-Teacher Feature Pyramid Matching for Unsupervised Anomaly Detection
Mar 15, 2021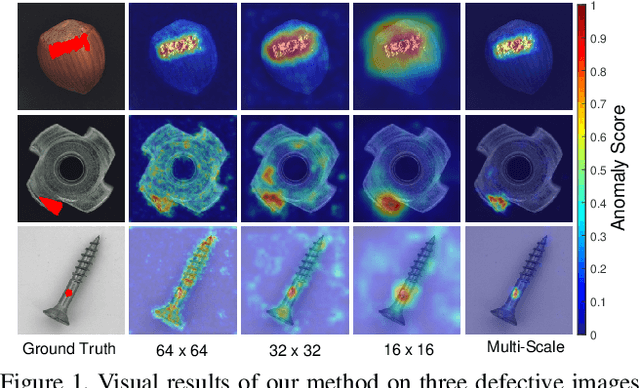
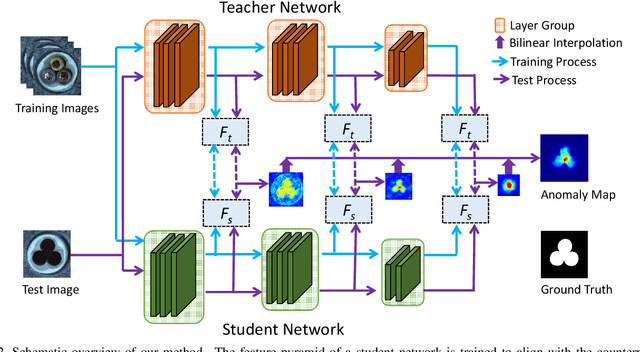
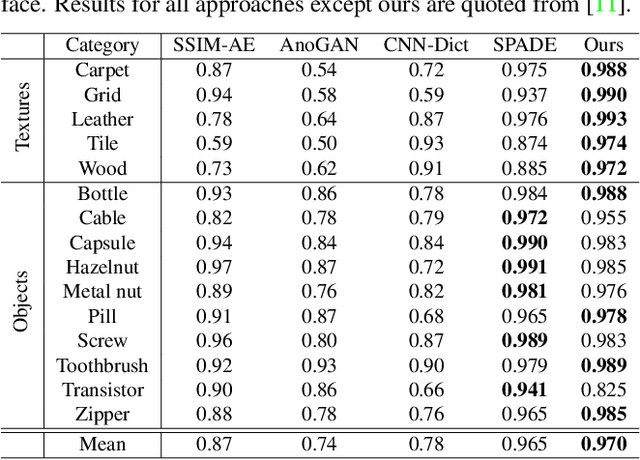
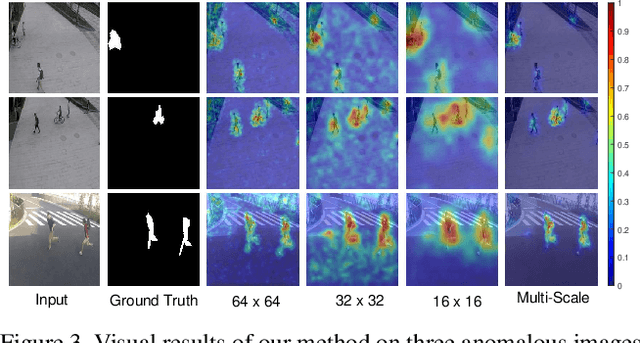
Anomaly detection is a challenging task and usually formulated as an unsupervised learning problem for the unexpectedness of anomalies. This paper proposes a simple yet powerful approach to this issue, which is implemented in the student-teacher framework for its advantages but substantially extends it in terms of both accuracy and efficiency. Given a strong model pre-trained on image classification as the teacher, we distill the knowledge into a single student network with the identical architecture to learn the distribution of anomaly-free images and this one-step transfer preserves the crucial clues as much as possible. Moreover, we integrate the multi-scale feature matching strategy into the framework, and this hierarchical feature alignment enables the student network to receive a mixture of multi-level knowledge from the feature pyramid under better supervision, thus allowing to detect anomalies of various sizes. The difference between feature pyramids generated by the two networks serves as a scoring function indicating the probability of anomaly occurring. Due to such operations, our approach achieves accurate and fast pixel-level anomaly detection. Very competitive results are delivered on three major benchmarks, significantly superior to the state of the art ones. In addition, it makes inferences at a very high speed (with 100 FPS for images of the size at 256x256), at least dozens of times faster than the latest counterparts.
HS-ResNet: Hierarchical-Split Block on Convolutional Neural Network
Oct 15, 2020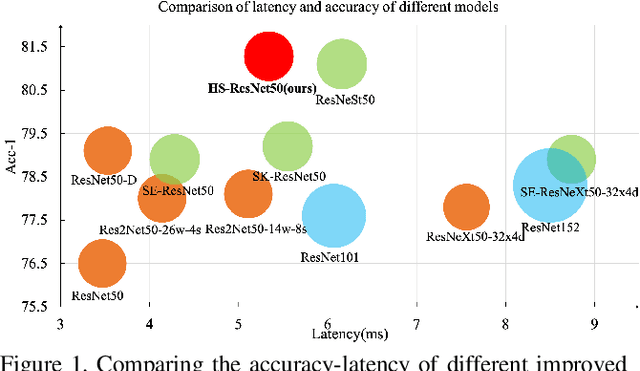
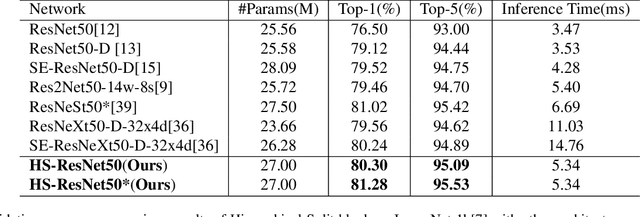
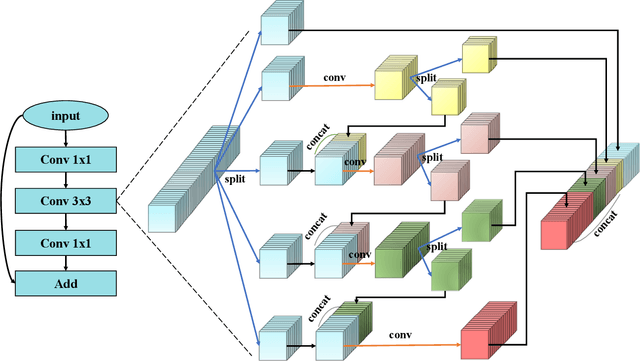

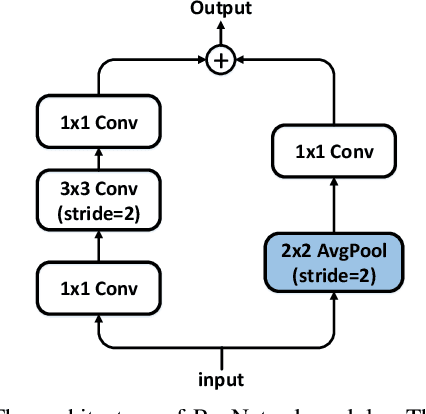
This paper addresses representational block named Hierarchical-Split Block, which can be taken as a plug-and-play block to upgrade existing convolutional neural networks, improves model performance significantly in a network. Hierarchical-Split Block contains many hierarchical split and concatenate connections within one single residual block. We find multi-scale features is of great importance for numerous vision tasks. Moreover, Hierarchical-Split block is very flexible and efficient, which provides a large space of potential network architectures for different applications. In this work, we present a common backbone based on Hierarchical-Split block for tasks: image classification, object detection, instance segmentation and semantic image segmentation/parsing. Our approach shows significant improvements over all these core tasks in comparison with the baseline. As shown in Figure1, for image classification, our 50-layers network(HS-ResNet50) achieves 81.28% top-1 accuracy with competitive latency on ImageNet-1k dataset. It also outperforms most state-of-the-art models. The source code and models will be available on: https://github.com/PaddlePaddle/PaddleClas
The 1st Tiny Object Detection Challenge:Methods and Results
Oct 06, 2020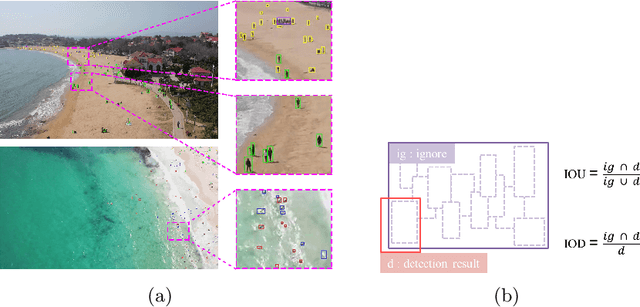
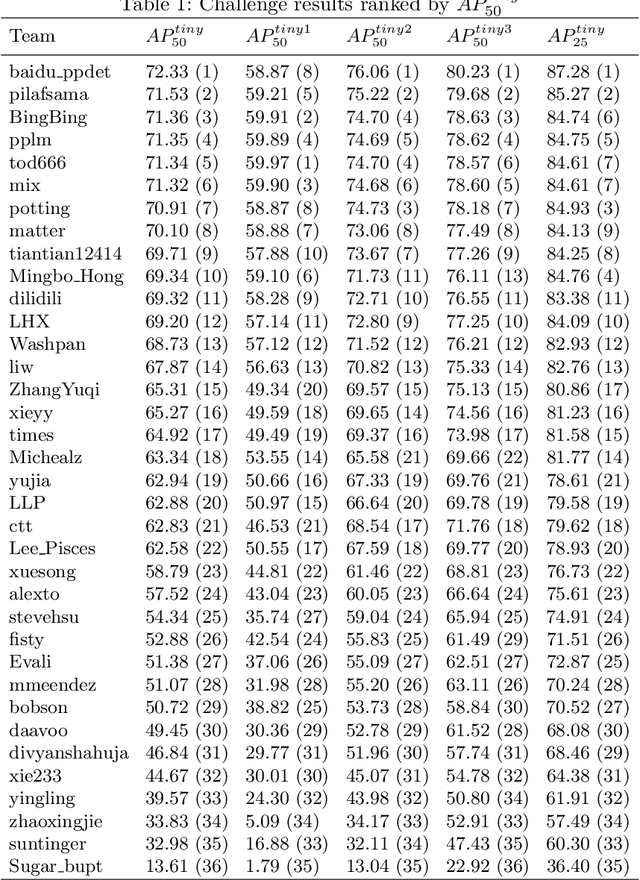
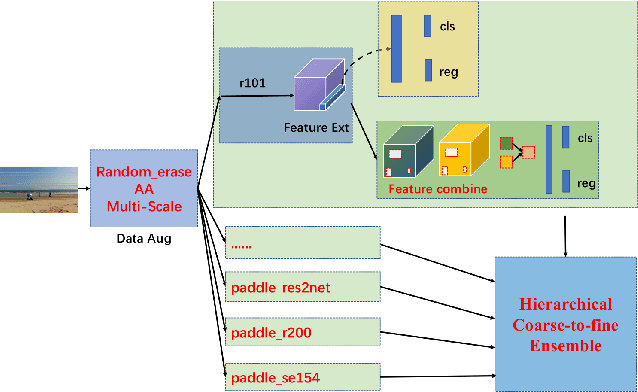

The 1st Tiny Object Detection (TOD) Challenge aims to encourage research in developing novel and accurate methods for tiny object detection in images which have wide views, with a current focus on tiny person detection. The TinyPerson dataset was used for the TOD Challenge and is publicly released. It has 1610 images and 72651 box-levelannotations. Around 36 participating teams from the globe competed inthe 1st TOD Challenge. In this paper, we provide a brief summary of the1st TOD Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that areinterested in the TOD challenge. The benchmark dataset and other information can be found at: https://github.com/ucas-vg/TinyBenchmark.
PP-YOLO: An Effective and Efficient Implementation of Object Detector
Aug 03, 2020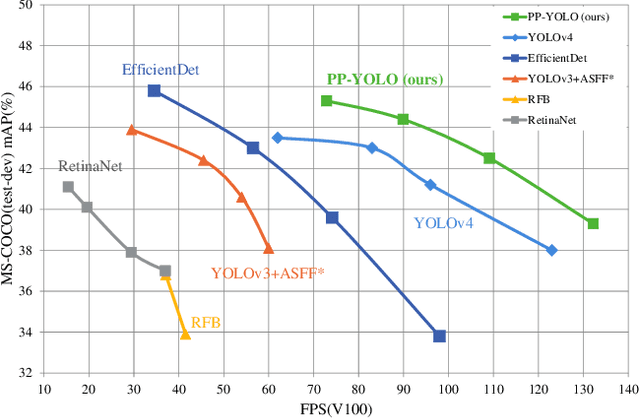
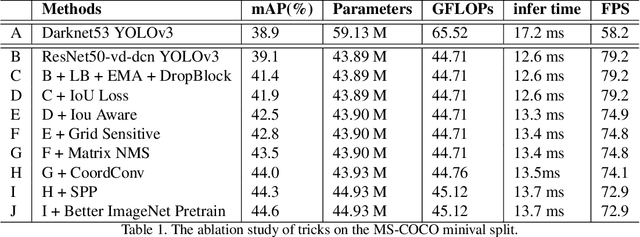
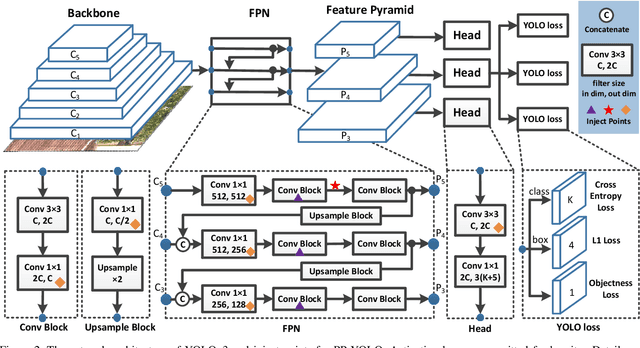
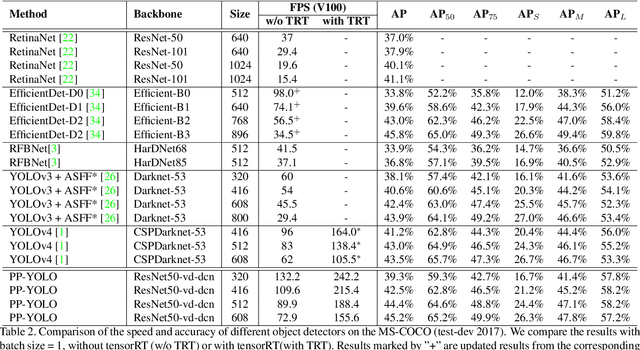
Object detection is one of the most important areas in computer vision, which plays a key role in various practical scenarios. Due to limitation of hardware, it is often necessary to sacrifice accuracy to ensure the infer speed of the detector in practice. Therefore, the balance between effectiveness and efficiency of object detector must be considered. The goal of this paper is to implement an object detector with relatively balanced effectiveness and efficiency that can be directly applied in actual application scenarios, rather than propose a novel detection model. Considering that YOLOv3 has been widely used in practice, we develop a new object detector based on YOLOv3. We mainly try to combine various existing tricks that almost not increase the number of model parameters and FLOPs, to achieve the goal of improving the accuracy of detector as much as possible while ensuring that the speed is almost unchanged. Since all experiments in this paper are conducted based on PaddlePaddle, we call it PP-YOLO. By combining multiple tricks, PP-YOLO can achieve a better balance between effectiveness (45.2% mAP) and efficiency (72.9 FPS), surpassing the existing state-of-the-art detectors such as EfficientDet and YOLOv4.Source code is at https://github.com/PaddlePaddle/PaddleDetection.
2nd Place Solution in Google AI Open Images Object Detection Track 2019
Nov 17, 2019
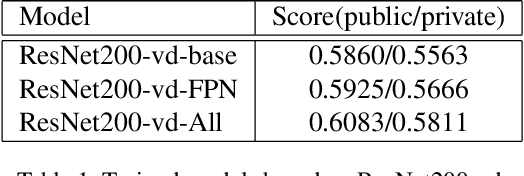


We present an object detection framework based on PaddlePaddle. We put all the strategies together (multi-scale training, FPN, Cascade, Dcnv2, Non-local, libra loss) based on ResNet200-vd backbone. Our model score on public leaderboard comes to 0.6269 with single scale test. We proposed a new voting method called top-k voting-nms, based on the SoftNMS detection results. The voting method helps us merge all the models' results more easily and achieve 2nd place in the Google AI Open Images Object Detection Track 2019.
Learning from Large-scale Noisy Web Data with Ubiquitous Reweighting for Image Classification
Nov 02, 2018
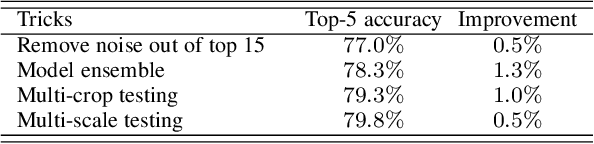


Many advances of deep learning techniques originate from the efforts of addressing the image classification task on large-scale datasets. However, the construction of such clean datasets is costly and time-consuming since the Internet is overwhelmed by noisy images with inadequate and inaccurate tags. In this paper, we propose a Ubiquitous Reweighting Network (URNet) that learns an image classification model from large-scale noisy data. By observing the web data, we find that there are five key challenges, \ie, imbalanced class sizes, high intra-classes diversity and inter-class similarity, imprecise instances, insufficient representative instances, and ambiguous class labels. To alleviate these challenges, we assume that every training instance has the potential to contribute positively by alleviating the data bias and noise via reweighting the influence of each instance according to different class sizes, large instance clusters, its confidence, small instance bags and the labels. In this manner, the influence of bias and noise in the web data can be gradually alleviated, leading to the steadily improving performance of URNet. Experimental results in the WebVision 2018 challenge with 16 million noisy training images from 5000 classes show that our approach outperforms state-of-the-art models and ranks the first place in the image classification task.