 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechUT: Bridging Speech and Text with Hidden-Unit for Encoder-Decoder Based Speech-Text Pre-training
Oct 07, 2022
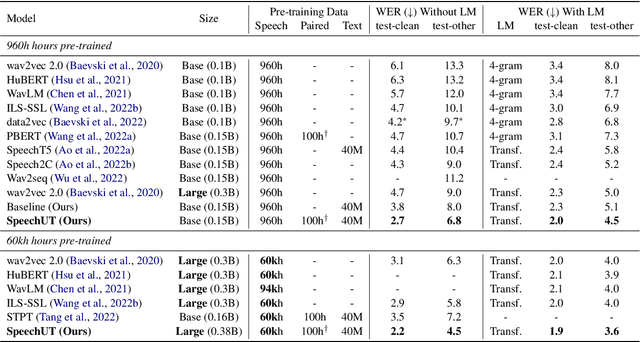
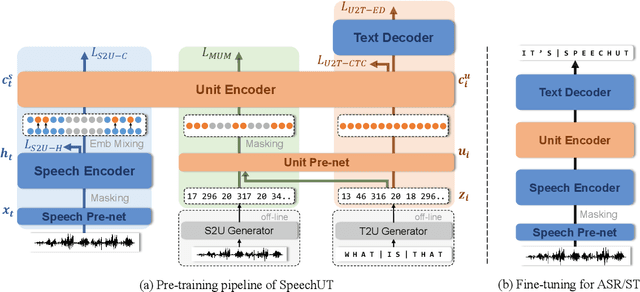
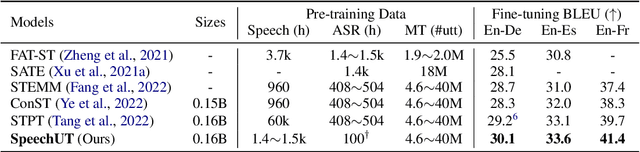
The rapid development of single-modal pre-training has prompted researchers to pay more attention to cross-modal pre-training methods. In this paper, we propose a unified-modal speech-unit-text pre-training model, SpeechUT, to connect the representations of a speech encoder and a text decoder with a shared unit encoder. Leveraging hidden-unit as an interface to align speech and text, we can decompose the speech-to-text model into a speech-to-unit model and a unit-to-text model, which can be jointly pre-trained with unpaired speech and text data respectively. Our proposed SpeechUT is fine-tuned and evaluated on automatic speech recognition (ASR) and speech translation (ST) tasks. Experimental results show that SpeechUT gets substantial improvements over strong baselines, and achieves state-of-the-art performance on both the LibriSpeech ASR and MuST-C ST tasks. To better understand the proposed SpeechUT, detailed analyses are conducted. The code and pre-trained models are available at https://aka.ms/SpeechUT.
SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
Sep 30, 2022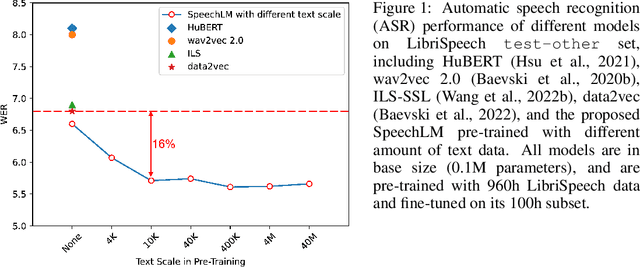
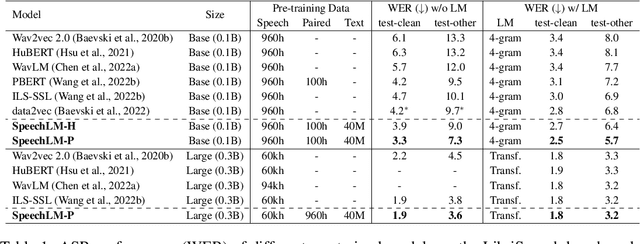
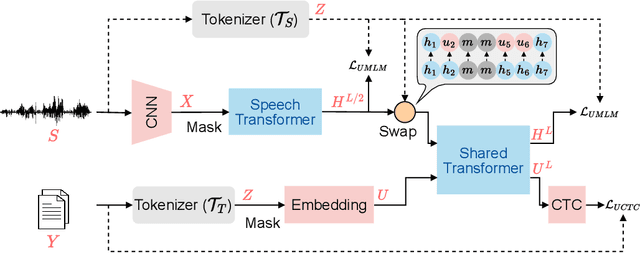
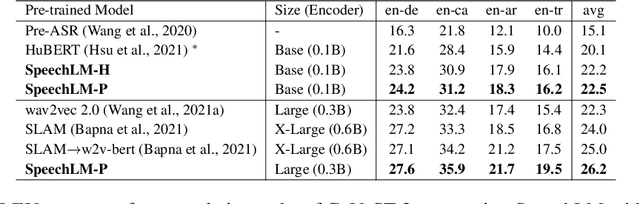
How to boost speech pre-training with textual data is an unsolved problem due to the fact that speech and text are very different modalities with distinct characteristics. In this paper, we propose a cross-modal Speech and Language Model (SpeechLM) to explicitly align speech and text pre-training with a pre-defined unified discrete representation. Specifically, we introduce two alternative discrete tokenizers to bridge the speech and text modalities, including phoneme-unit and hidden-unit tokenizers, which can be trained using a small amount of paired speech-text data. Based on the trained tokenizers, we convert the unlabeled speech and text data into tokens of phoneme units or hidden units. The pre-training objective is designed to unify the speech and the text into the same discrete semantic space with a unified Transformer network. Leveraging only 10K text sentences, our SpeechLM gets a 16\% relative WER reduction over the best base model performance (from 6.8 to 5.7) on the public LibriSpeech ASR benchmark. Moreover, SpeechLM with fewer parameters even outperforms previous SOTA models on CoVoST-2 speech translation tasks. We also evaluate our SpeechLM on various spoken language processing tasks under the universal representation evaluation framework SUPERB, demonstrating significant improvements on content-related tasks. Our code and models are available at https://aka.ms/SpeechLM.
Supervision-Guided Codebooks for Masked Prediction in Speech Pre-training
Jun 21, 2022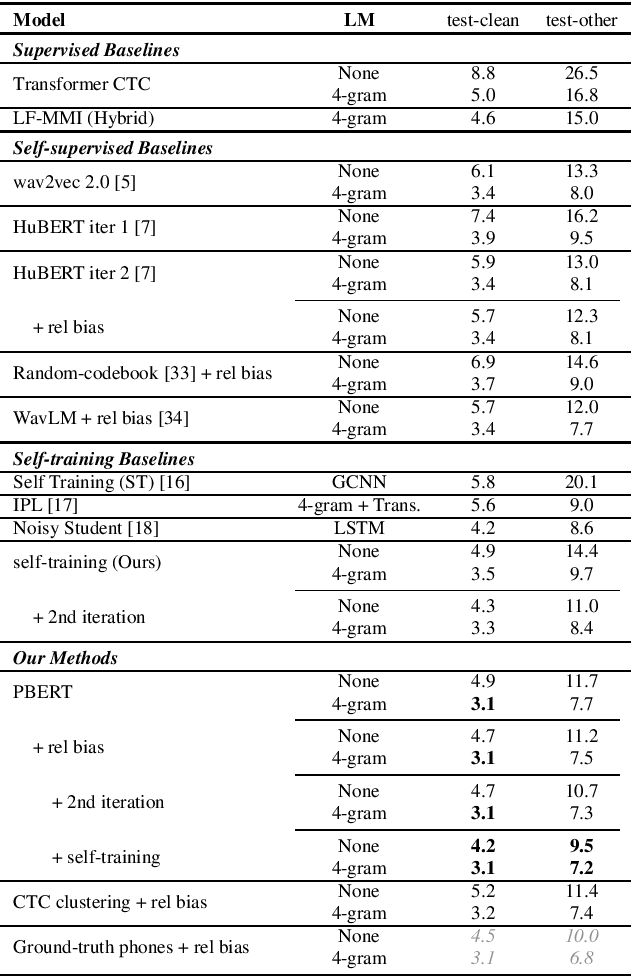
Recently, masked prediction pre-training has seen remarkable progress in self-supervised learning (SSL) for speech recognition. It usually requires a codebook obtained in an unsupervised way, making it less accurate and difficult to interpret. We propose two supervision-guided codebook generation approaches to improve automatic speech recognition (ASR) performance and also the pre-training efficiency, either through decoding with a hybrid ASR system to generate phoneme-level alignments (named PBERT), or performing clustering on the supervised speech features extracted from an end-to-end CTC model (named CTC clustering). Both the hybrid and CTC models are trained on the same small amount of labeled speech as used in fine-tuning. Experiments demonstrate significant superiority of our methods to various SSL and self-training baselines, with up to 17.0% relative WER reduction. Our pre-trained models also show good transferability in a non-ASR speech task.
The YiTrans End-to-End Speech Translation System for IWSLT 2022 Offline Shared Task
Jun 14, 2022
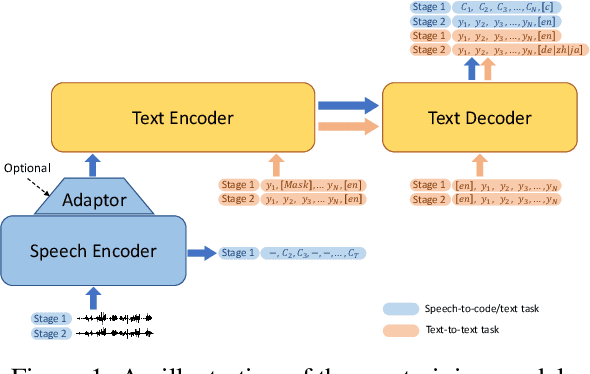
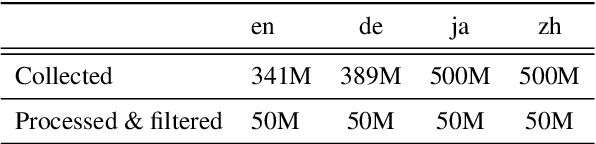
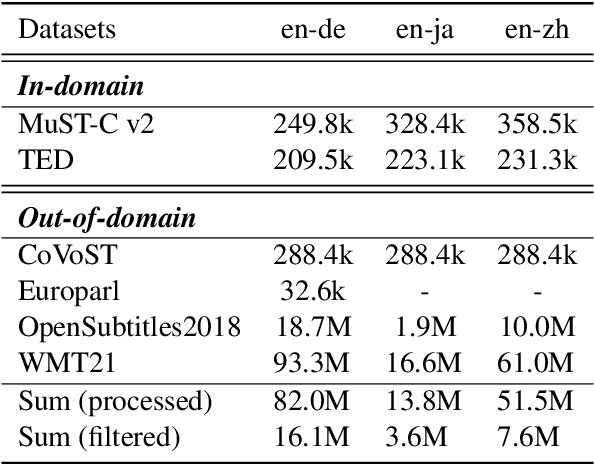
This paper describes the submission of our end-to-end YiTrans speech translation system for the IWSLT 2022 offline task, which translates from English audio to German, Chinese, and Japanese. The YiTrans system is built on large-scale pre-trained encoder-decoder models. More specifically, we first design a multi-stage pre-training strategy to build a multi-modality model with a large amount of labeled and unlabeled data. We then fine-tune the corresponding components of the model for the downstream speech translation tasks. Moreover, we make various efforts to improve performance, such as data filtering, data augmentation, speech segmentation, model ensemble, and so on. Experimental results show that our YiTrans system obtains a significant improvement than the strong baseline on three translation directions, and it achieves +5.2 BLEU improvements over last year's optimal end-to-end system on tst2021 English-German. Our final submissions rank first on English-German and English-Chinese end-to-end systems in terms of the automatic evaluation metric. We make our code and models publicly available.
Ultra Fast Speech Separation Model with Teacher Student Learning
Apr 27, 2022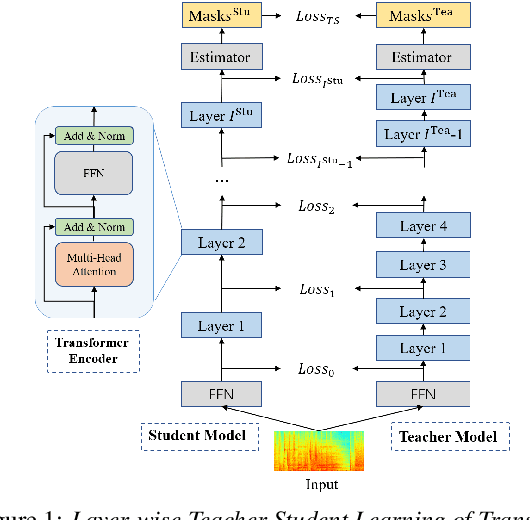
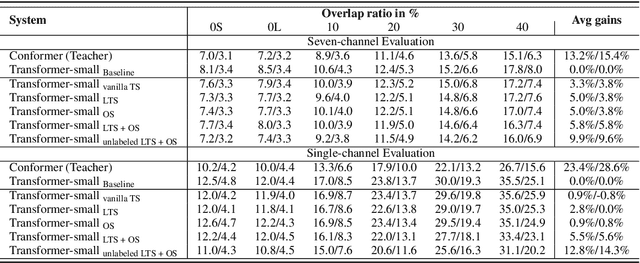
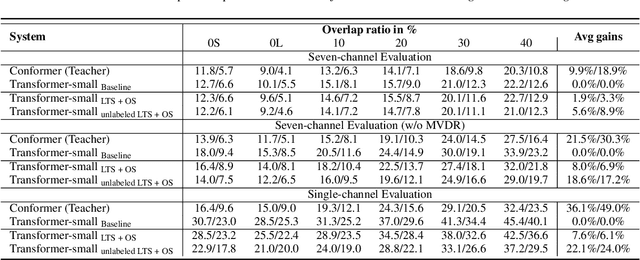
Transformer has been successfully applied to speech separation recently with its strong long-dependency modeling capacity using a self-attention mechanism. However, Transformer tends to have heavy run-time costs due to the deep encoder layers, which hinders its deployment on edge devices. A small Transformer model with fewer encoder layers is preferred for computational efficiency, but it is prone to performance degradation. In this paper, an ultra fast speech separation Transformer model is proposed to achieve both better performance and efficiency with teacher student learning (T-S learning). We introduce layer-wise T-S learning and objective shifting mechanisms to guide the small student model to learn intermediate representations from the large teacher model. Compared with the small Transformer model trained from scratch, the proposed T-S learning method reduces the word error rate (WER) by more than 5% for both multi-channel and single-channel speech separation on LibriCSS dataset. Utilizing more unlabeled speech data, our ultra fast speech separation models achieve more than 10% relative WER reduction.
Why does Self-Supervised Learning for Speech Recognition Benefit Speaker Recognition?
Apr 27, 2022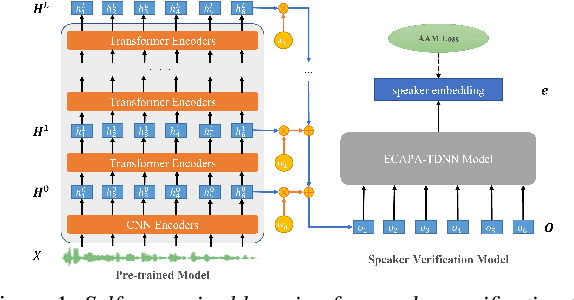
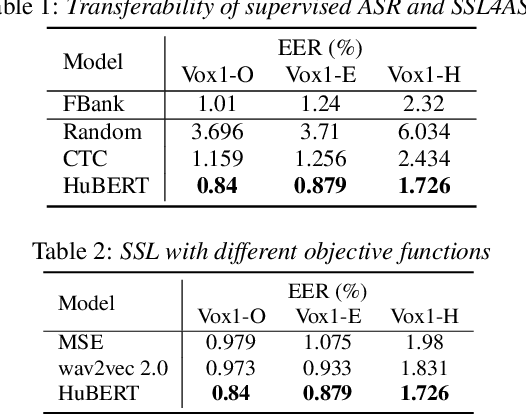
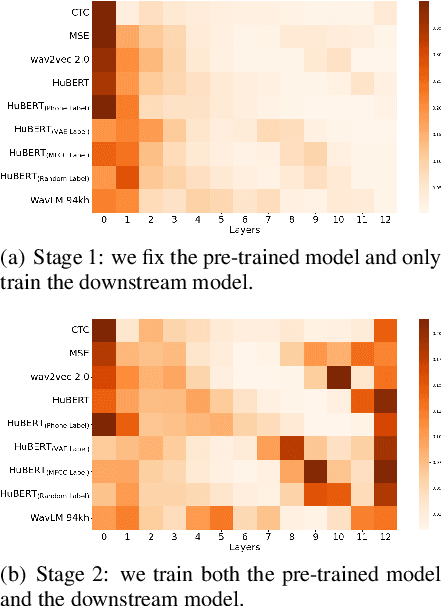
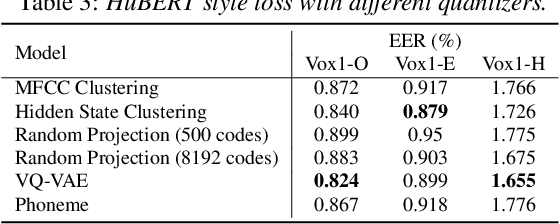
Recently, self-supervised learning (SSL) has demonstrated strong performance in speaker recognition, even if the pre-training objective is designed for speech recognition. In this paper, we study which factor leads to the success of self-supervised learning on speaker-related tasks, e.g. speaker verification (SV), through a series of carefully designed experiments. Our empirical results on the Voxceleb-1 dataset suggest that the benefit of SSL to SV task is from a combination of mask speech prediction loss, data scale, and model size, while the SSL quantizer has a minor impact. We further employ the integrated gradients attribution method and loss landscape visualization to understand the effectiveness of self-supervised learning for speaker recognition performance.
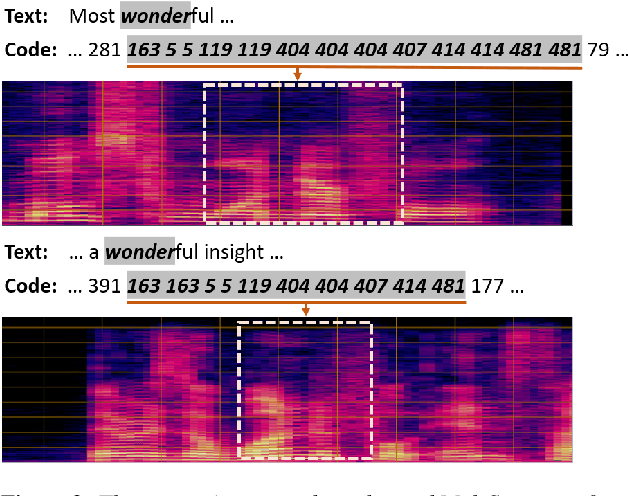
Speech Pre-training with Acoustic Piece
Apr 07, 2022

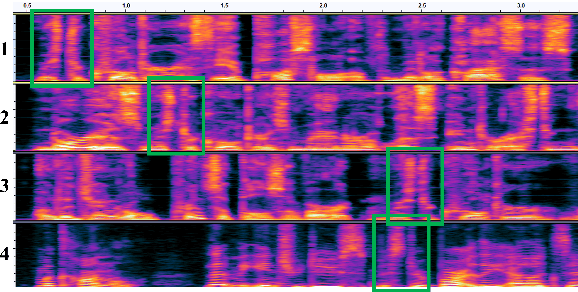
Previous speech pre-training methods, such as wav2vec2.0 and HuBERT, pre-train a Transformer encoder to learn deep representations from audio data, with objectives predicting either elements from latent vector quantized space or pre-generated labels (known as target codes) with offline clustering. However, those training signals (quantized elements or codes) are independent across different tokens without considering their relations. According to our observation and analysis, the target codes share obvious patterns aligned with phonemized text data. Based on that, we propose to leverage those patterns to better pre-train the model considering the relations among the codes. The patterns we extracted, called "acoustic piece"s, are from the sentence piece result of HuBERT codes. With the acoustic piece as the training signal, we can implicitly bridge the input audio and natural language, which benefits audio-to-text tasks, such as automatic speech recognition (ASR). Simple but effective, our method "HuBERT-AP" significantly outperforms strong baselines on the LibriSpeech ASR task.
Pre-Training Transformer Decoder for End-to-End ASR Model with Unpaired Speech Data
Mar 31, 2022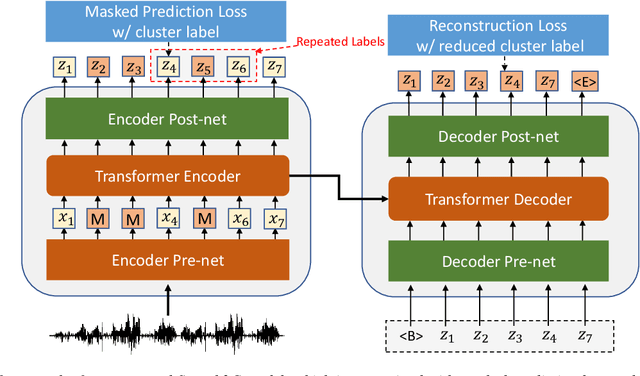
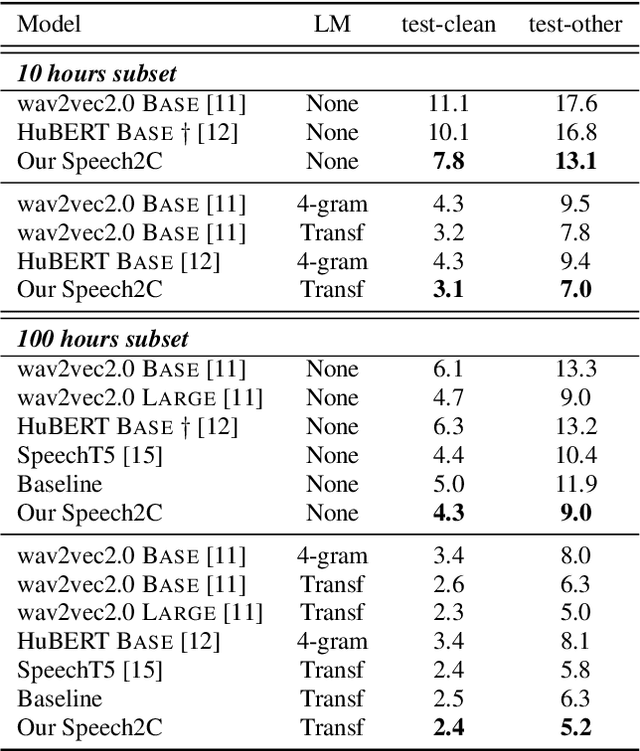

This paper studies a novel pre-training technique with unpaired speech data, Speech2C, for encoder-decoder based automatic speech recognition (ASR). Within a multi-task learning framework, we introduce two pre-training tasks for the encoder-decoder network using acoustic units, i.e., pseudo codes, derived from an offline clustering model. One is to predict the pseudo codes via masked language modeling in encoder output, like HuBERT model, while the other lets the decoder learn to reconstruct pseudo codes autoregressively instead of generating textual scripts. In this way, the decoder learns to reconstruct original speech information with codes before learning to generate correct text. Comprehensive experiments on the LibriSpeech corpus show that the proposed Speech2C can relatively reduce the word error rate (WER) by 19.2% over the method without decoder pre-training, and also outperforms significantly the state-of-the-art wav2vec 2.0 and HuBERT on fine-tuning subsets of 10h and 100h.
Self-Supervised Learning for speech recognition with Intermediate layer supervision
Dec 16, 2021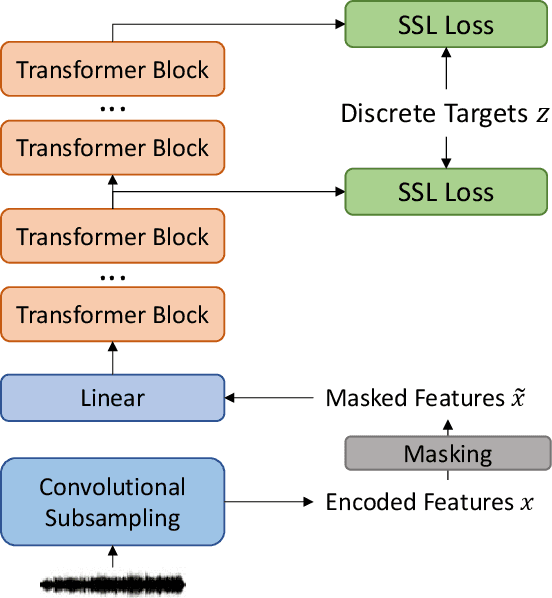
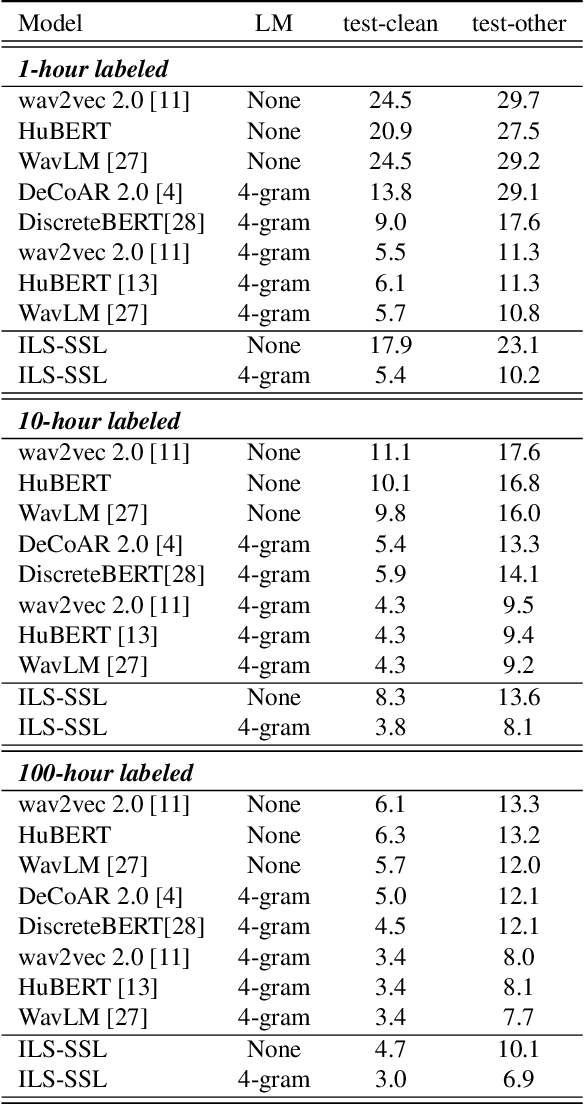
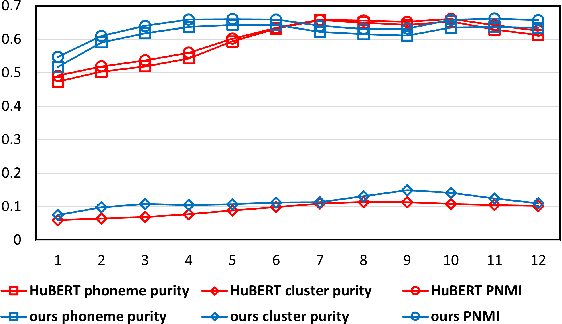
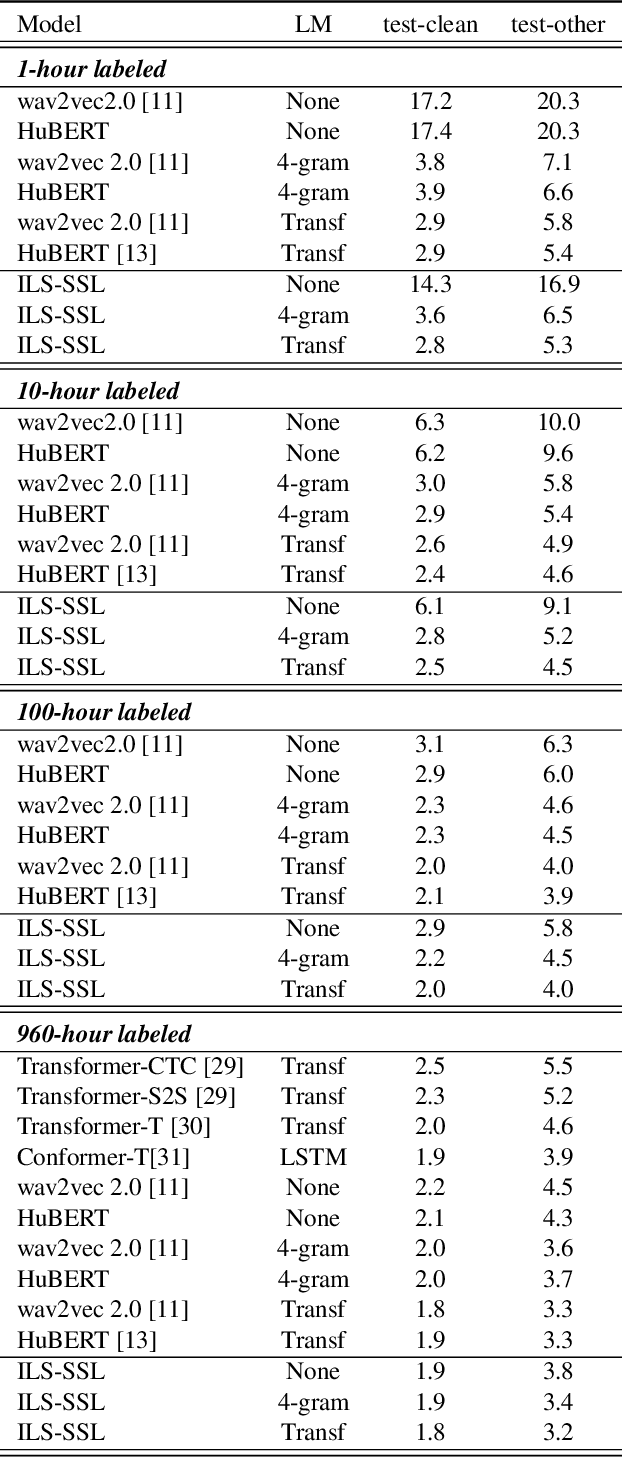
Recently, pioneer work finds that speech pre-trained models can solve full-stack speech processing tasks, because the model utilizes bottom layers to learn speaker-related information and top layers to encode content-related information. Since the network capacity is limited, we believe the speech recognition performance could be further improved if the model is dedicated to audio content information learning. To this end, we propose Intermediate Layer Supervision for Self-Supervised Learning (ILS-SSL), which forces the model to concentrate on content information as much as possible by adding an additional SSL loss on the intermediate layers. Experiments on LibriSpeech test-other set show that our method outperforms HuBERT significantly, which achieves a 23.5%/11.6% relative word error rate reduction in the w/o language model setting for base/large models. Detailed analysis shows the bottom layers of our model have a better correlation with phonetic units, which is consistent with our intuition and explains the success of our method for ASR.
Separating Long-Form Speech with Group-Wise Permutation Invariant Training
Nov 17, 2021
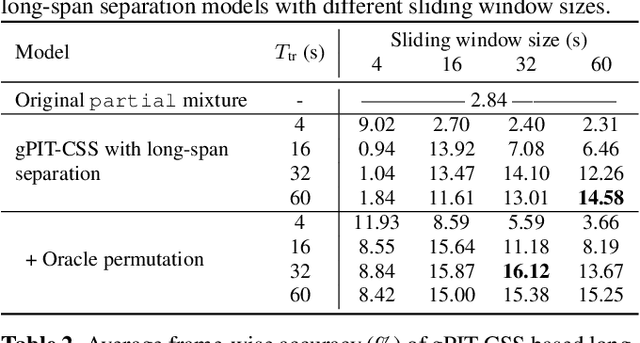
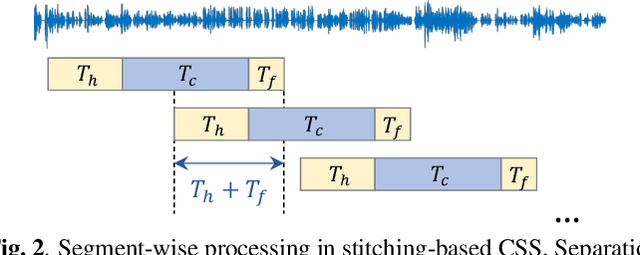
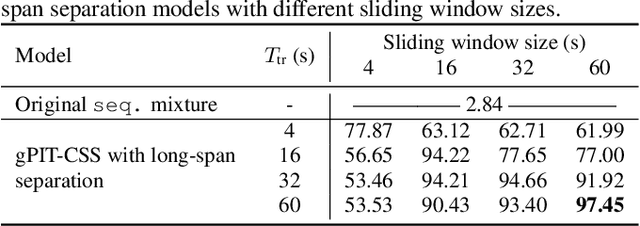
Multi-talker conversational speech processing has drawn many interests for various applications such as meeting transcription. Speech separation is often required to handle overlapped speech that is commonly observed in conversation. Although the original utterancelevel permutation invariant training-based continuous speech separation approach has proven to be effective in various conditions, it lacks the ability to leverage the long-span relationship of utterances and is computationally inefficient due to the highly overlapped sliding windows. To overcome these drawbacks, we propose a novel training scheme named Group-PIT, which allows direct training of the speech separation models on the long-form speech with a low computational cost for label assignment. Two different speech separation approaches with Group-PIT are explored, including direct long-span speech separation and short-span speech separation with long-span tracking. The experiments on the simulated meeting-style data demonstrate the effectiveness of our proposed approaches, especially in dealing with a very long speech input.