 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Set Knowledge-Based Visual Question Answering with Inference Paths
Oct 12, 2023



Given an image and an associated textual question, the purpose of Knowledge-Based Visual Question Answering (KB-VQA) is to provide a correct answer to the question with the aid of external knowledge bases. Prior KB-VQA models are usually formulated as a retriever-classifier framework, where a pre-trained retriever extracts textual or visual information from knowledge graphs and then makes a prediction among the candidates. Despite promising progress, there are two drawbacks with existing models. Firstly, modeling question-answering as multi-class classification limits the answer space to a preset corpus and lacks the ability of flexible reasoning. Secondly, the classifier merely consider "what is the answer" without "how to get the answer", which cannot ground the answer to explicit reasoning paths. In this paper, we confront the challenge of \emph{explainable open-set} KB-VQA, where the system is required to answer questions with entities at wild and retain an explainable reasoning path. To resolve the aforementioned issues, we propose a new retriever-ranker paradigm of KB-VQA, Graph pATH rankER (GATHER for brevity). Specifically, it contains graph constructing, pruning, and path-level ranking, which not only retrieves accurate answers but also provides inference paths that explain the reasoning process. To comprehensively evaluate our model, we reformulate the benchmark dataset OK-VQA with manually corrected entity-level annotations and release it as ConceptVQA. Extensive experiments on real-world questions demonstrate that our framework is not only able to perform open-set question answering across the whole knowledge base but provide explicit reasoning path.
Dual-view Curricular Optimal Transport for Cross-lingual Cross-modal Retrieval
Sep 11, 2023Current research on cross-modal retrieval is mostly English-oriented, as the availability of a large number of English-oriented human-labeled vision-language corpora. In order to break the limit of non-English labeled data, cross-lingual cross-modal retrieval (CCR) has attracted increasing attention. Most CCR methods construct pseudo-parallel vision-language corpora via Machine Translation (MT) to achieve cross-lingual transfer. However, the translated sentences from MT are generally imperfect in describing the corresponding visual contents. Improperly assuming the pseudo-parallel data are correctly correlated will make the networks overfit to the noisy correspondence. Therefore, we propose Dual-view Curricular Optimal Transport (DCOT) to learn with noisy correspondence in CCR. In particular, we quantify the confidence of the sample pair correlation with optimal transport theory from both the cross-lingual and cross-modal views, and design dual-view curriculum learning to dynamically model the transportation costs according to the learning stage of the two views. Extensive experiments are conducted on two multilingual image-text datasets and one video-text dataset, and the results demonstrate the effectiveness and robustness of the proposed method. Besides, our proposed method also shows a good expansibility to cross-lingual image-text baselines and a decent generalization on out-of-domain data.
Orthogonal Temporal Interpolation for Zero-Shot Video Recognition
Aug 14, 2023Zero-shot video recognition (ZSVR) is a task that aims to recognize video categories that have not been seen during the model training process. Recently, vision-language models (VLMs) pre-trained on large-scale image-text pairs have demonstrated impressive transferability for ZSVR. To make VLMs applicable to the video domain, existing methods often use an additional temporal learning module after the image-level encoder to learn the temporal relationships among video frames. Unfortunately, for video from unseen categories, we observe an abnormal phenomenon where the model that uses spatial-temporal feature performs much worse than the model that removes temporal learning module and uses only spatial feature. We conjecture that improper temporal modeling on video disrupts the spatial feature of the video. To verify our hypothesis, we propose Feature Factorization to retain the orthogonal temporal feature of the video and use interpolation to construct refined spatial-temporal feature. The model using appropriately refined spatial-temporal feature performs better than the one using only spatial feature, which verifies the effectiveness of the orthogonal temporal feature for the ZSVR task. Therefore, an Orthogonal Temporal Interpolation module is designed to learn a better refined spatial-temporal video feature during training. Additionally, a Matching Loss is introduced to improve the quality of the orthogonal temporal feature. We propose a model called OTI for ZSVR by employing orthogonal temporal interpolation and the matching loss based on VLMs. The ZSVR accuracies on popular video datasets (i.e., Kinetics-600, UCF101 and HMDB51) show that OTI outperforms the previous state-of-the-art method by a clear margin.
ImageNet-E: Benchmarking Neural Network Robustness via Attribute Editing
Mar 30, 2023



Recent studies have shown that higher accuracy on ImageNet usually leads to better robustness against different corruptions. Therefore, in this paper, instead of following the traditional research paradigm that investigates new out-of-distribution corruptions or perturbations deep models may encounter, we conduct model debugging in in-distribution data to explore which object attributes a model may be sensitive to. To achieve this goal, we create a toolkit for object editing with controls of backgrounds, sizes, positions, and directions, and create a rigorous benchmark named ImageNet-E(diting) for evaluating the image classifier robustness in terms of object attributes. With our ImageNet-E, we evaluate the performance of current deep learning models, including both convolutional neural networks and vision transformers. We find that most models are quite sensitive to attribute changes. A small change in the background can lead to an average of 9.23\% drop on top-1 accuracy. We also evaluate some robust models including both adversarially trained models and other robust trained models and find that some models show worse robustness against attribute changes than vanilla models. Based on these findings, we discover ways to enhance attribute robustness with preprocessing, architecture designs, and training strategies. We hope this work can provide some insights to the community and open up a new avenue for research in robust computer vision. The code and dataset are available at https://github.com/alibaba/easyrobust.
* Accepted by CVPR2023
Stable Attribute Group Editing for Reliable Few-shot Image Generation
Feb 01, 2023



Few-shot image generation aims to generate data of an unseen category based on only a few samples. Apart from basic content generation, a bunch of downstream applications hopefully benefit from this task, such as low-data detection and few-shot classification. To achieve this goal, the generated images should guarantee category retention for classification beyond the visual quality and diversity. In our preliminary work, we present an ``editing-based'' framework Attribute Group Editing (AGE) for reliable few-shot image generation, which largely improves the generation performance. Nevertheless, AGE's performance on downstream classification is not as satisfactory as expected. This paper investigates the class inconsistency problem and proposes Stable Attribute Group Editing (SAGE) for more stable class-relevant image generation. SAGE takes use of all given few-shot images and estimates a class center embedding based on the category-relevant attribute dictionary. Meanwhile, according to the projection weights on the category-relevant attribute dictionary, we can select category-irrelevant attributes from the similar seen categories. Consequently, SAGE injects the whole distribution of the novel class into StyleGAN's latent space, thus largely remains the category retention and stability of the generated images. Going one step further, we find that class inconsistency is a common problem in GAN-generated images for downstream classification. Even though the generated images look photo-realistic and requires no category-relevant editing, they are usually of limited help for downstream classification. We systematically discuss this issue from both the generative model and classification model perspectives, and propose to boost the downstream classification performance of SAGE by enhancing the pixel and frequency components.
Exploiting Completeness and Uncertainty of Pseudo Labels for Weakly Supervised Video Anomaly Detection
Dec 08, 2022



Weakly supervised video anomaly detection aims to identify abnormal events in videos using only video-level labels. Recently, two-stage self-training methods have achieved significant improvements by self-generating pseudo labels and self-refining anomaly scores with these labels. As the pseudo labels play a crucial role, we propose an enhancement framework by exploiting completeness and uncertainty properties for effective self-training. Specifically, we first design a multi-head classification module (each head serves as a classifier) with a diversity loss to maximize the distribution differences of predicted pseudo labels across heads. This encourages the generated pseudo labels to cover as many abnormal events as possible. We then devise an iterative uncertainty pseudo label refinement strategy, which improves not only the initial pseudo labels but also the updated ones obtained by the desired classifier in the second stage. Extensive experimental results demonstrate the proposed method performs favorably against state-of-the-art approaches on the UCF-Crime, TAD, and XD-Violence benchmark datasets.
The Euclidean Space is Evil: Hyperbolic Attribute Editing for Few-shot Image Generation
Nov 22, 2022Few-shot image generation is a challenging task since it aims to generate diverse new images for an unseen category with only a few images. Existing methods suffer from the trade-off between the quality and diversity of generated images. To tackle this problem, we propose Hyperbolic Attribute Editing (HAE), a simple yet effective method. Unlike other methods that work in Euclidean space, HAE captures the hierarchy among images using data from seen categories in hyperbolic space. Given a well-trained HAE, images of unseen categories can be generated by moving the latent code of a given image toward any meaningful directions in the Poincar\'e disk with a fixing radius. Most importantly, the hyperbolic space allows us to control the semantic diversity of the generated images by setting different radii in the disk. Extensive experiments and visualizations demonstrate that HAE is capable of not only generating images with promising quality and diversity using limited data but achieving a highly controllable and interpretable editing process.
First Glance Diagnosis: Brain Disease Classification with Single fMRI Volume
Aug 10, 2022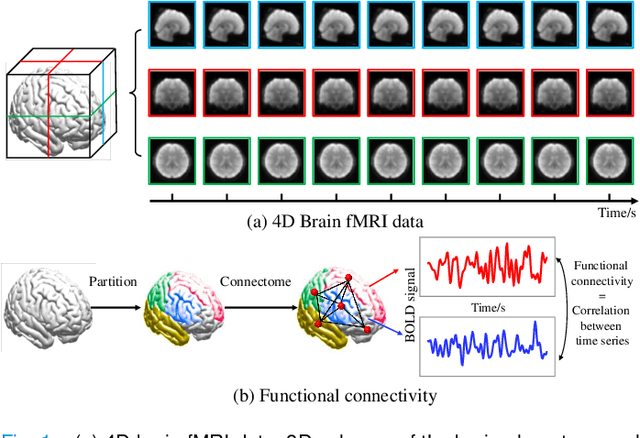
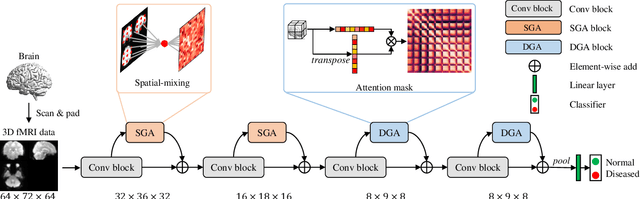
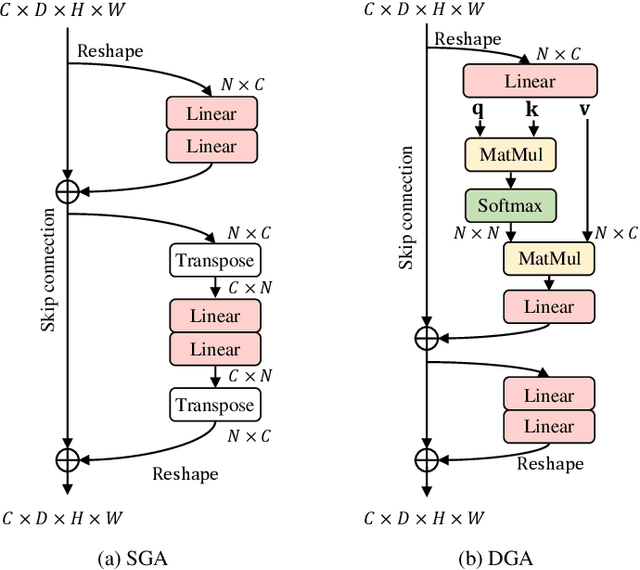

In neuroimaging analysis, functional magnetic resonance imaging (fMRI) can well assess brain function changes for brain diseases with no obvious structural lesions. So far, most deep-learning-based fMRI studies take functional connectivity as the basic feature in disease classification. However, functional connectivity is often calculated based on time series of predefined regions of interest and neglects detailed information contained in each voxel, which may accordingly deteriorate the performance of diagnostic models. Another methodological drawback is the limited sample size for the training of deep models. In this study, we propose BrainFormer, a general hybrid Transformer architecture for brain disease classification with single fMRI volume to fully exploit the voxel-wise details with sufficient data dimensions and sizes. BrainFormer is constructed by modeling the local cues within each voxel with 3D convolutions and capturing the global relations among distant regions with two global attention blocks. The local and global cues are aggregated in BrainFormer by a single-stream model. To handle multisite data, we propose a normalization layer to normalize the data into identical distribution. Finally, a Gradient-based Localization-map Visualization method is utilized for locating the possible disease-related biomarker. We evaluate BrainFormer on five independently acquired datasets including ABIDE, ADNI, MPILMBB, ADHD-200 and ECHO, with diseases of autism, Alzheimer's disease, depression, attention deficit hyperactivity disorder, and headache disorders. The results demonstrate the effectiveness and generalizability of BrainFormer for multiple brain diseases diagnosis. BrainFormer may promote neuroimaging-based precision diagnosis in clinical practice and motivate future study in fMRI analysis. Code is available at: https://github.com/ZiyaoZhangforPCL/BrainFormer.
Multi-Attention Network for Compressed Video Referring Object Segmentation
Jul 26, 2022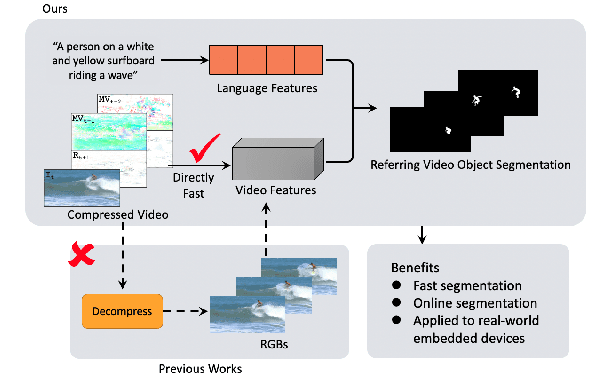
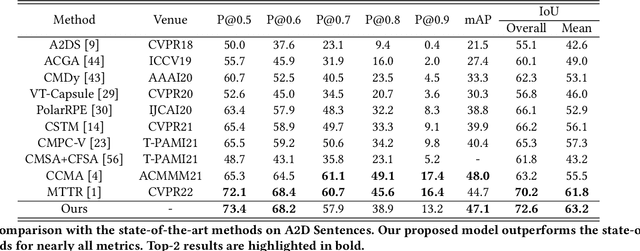
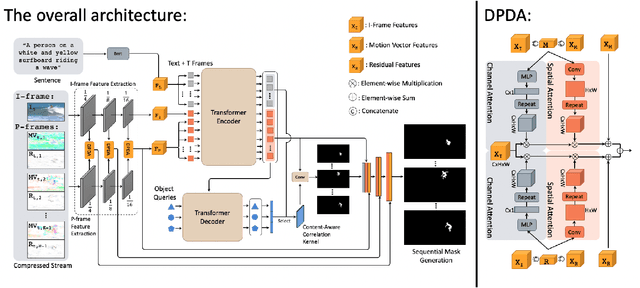
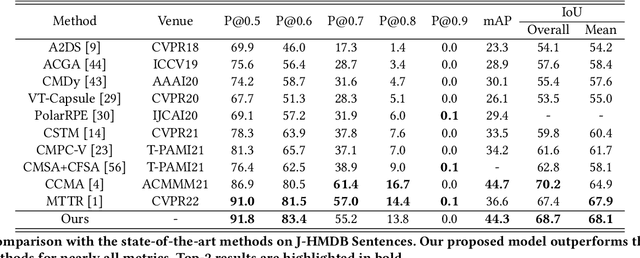
Referring video object segmentation aims to segment the object referred by a given language expression. Existing works typically require compressed video bitstream to be decoded to RGB frames before being segmented, which increases computation and storage requirements and ultimately slows the inference down. This may hamper its application in real-world computing resource limited scenarios, such as autonomous cars and drones. To alleviate this problem, in this paper, we explore the referring object segmentation task on compressed videos, namely on the original video data flow. Besides the inherent difficulty of the video referring object segmentation task itself, obtaining discriminative representation from compressed video is also rather challenging. To address this problem, we propose a multi-attention network which consists of dual-path dual-attention module and a query-based cross-modal Transformer module. Specifically, the dual-path dual-attention module is designed to extract effective representation from compressed data in three modalities, i.e., I-frame, Motion Vector and Residual. The query-based cross-modal Transformer firstly models the correlation between linguistic and visual modalities, and then the fused multi-modality features are used to guide object queries to generate a content-aware dynamic kernel and to predict final segmentation masks. Different from previous works, we propose to learn just one kernel, which thus removes the complicated post mask-matching procedure of existing methods. Extensive promising experimental results on three challenging datasets show the effectiveness of our method compared against several state-of-the-art methods which are proposed for processing RGB data. Source code is available at: https://github.com/DexiangHong/MANet.
Entity-enhanced Adaptive Reconstruction Network for Weakly Supervised Referring Expression Grounding
Jul 18, 2022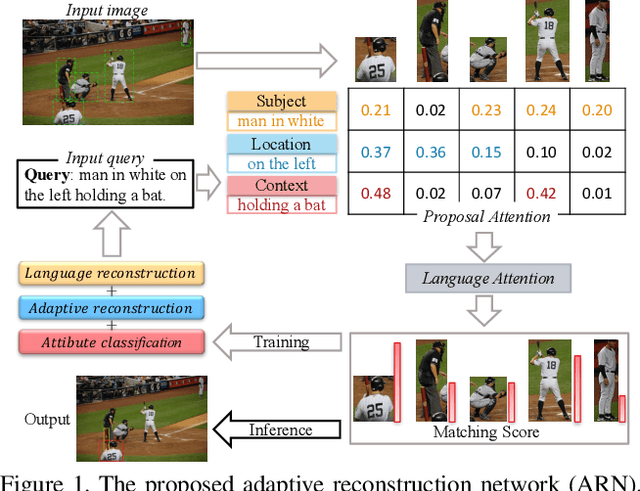
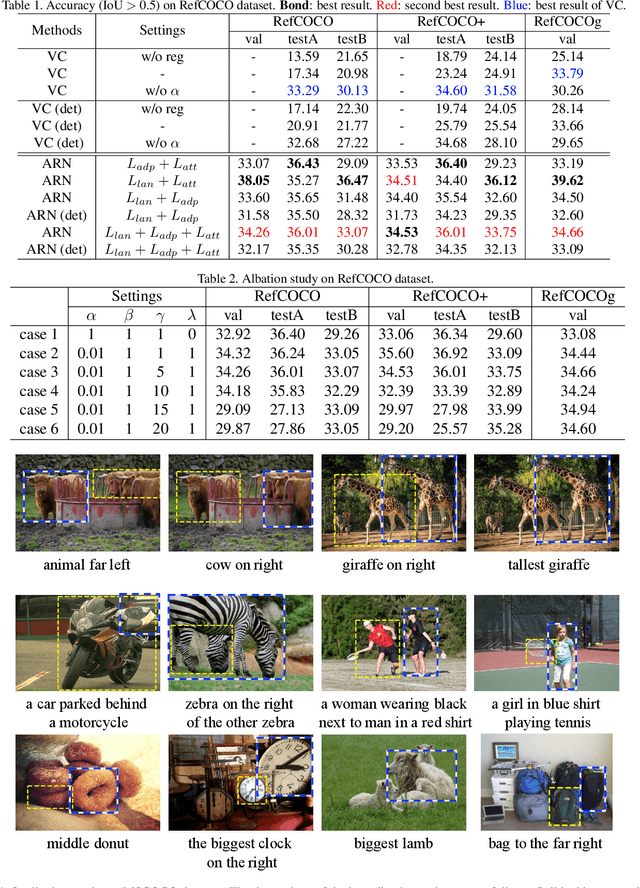
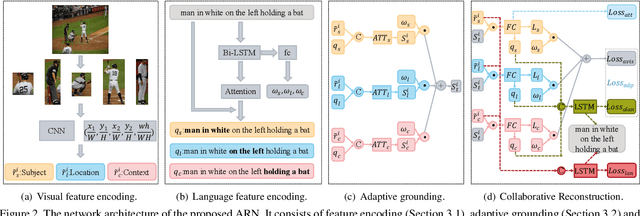
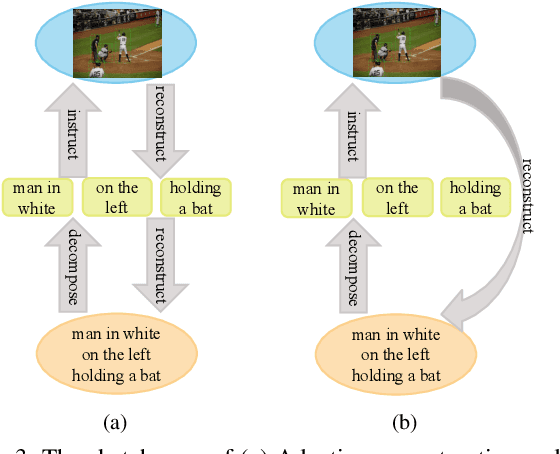
Weakly supervised Referring Expression Grounding (REG) aims to ground a particular target in an image described by a language expression while lacking the correspondence between target and expression. Two main problems exist in weakly supervised REG. First, the lack of region-level annotations introduces ambiguities between proposals and queries. Second, most previous weakly supervised REG methods ignore the discriminative location and context of the referent, causing difficulties in distinguishing the target from other same-category objects. To address the above challenges, we design an entity-enhanced adaptive reconstruction network (EARN). Specifically, EARN includes three modules: entity enhancement, adaptive grounding, and collaborative reconstruction. In entity enhancement, we calculate semantic similarity as supervision to select the candidate proposals. Adaptive grounding calculates the ranking score of candidate proposals upon subject, location and context with hierarchical attention. Collaborative reconstruction measures the ranking result from three perspectives: adaptive reconstruction, language reconstruction and attribute classification. The adaptive mechanism helps to alleviate the variance of different referring expressions. Experiments on five datasets show EARN outperforms existing state-of-the-art methods. Qualitative results demonstrate that the proposed EARN can better handle the situation where multiple objects of a particular category are situated together.