 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Deep Large-baseline Homography Estimation with Progressive Equivalence Constraint
Dec 06, 2022Homography estimation is erroneous in the case of large-baseline due to the low image overlay and limited receptive field. To address it, we propose a progressive estimation strategy by converting large-baseline homography into multiple intermediate ones, cumulatively multiplying these intermediate items can reconstruct the initial homography. Meanwhile, a semi-supervised homography identity loss, which consists of two components: a supervised objective and an unsupervised objective, is introduced. The first supervised loss is acting to optimize intermediate homographies, while the second unsupervised one helps to estimate a large-baseline homography without photometric losses. To validate our method, we propose a large-scale dataset that covers regular and challenging scenes. Experiments show that our method achieves state-of-the-art performance in large-baseline scenes while keeping competitive performance in small-baseline scenes. Code and dataset are available at https://github.com/megvii-research/LBHomo.
Minimum Latency Deep Online Video Stabilization
Dec 05, 2022



We present a novel camera path optimization framework for the task of online video stabilization. Typically, a stabilization pipeline consists of three steps: motion estimating, path smoothing, and novel view rendering. Most previous methods concentrate on motion estimation, proposing various global or local motion models. In contrast, path optimization receives relatively less attention, especially in the important online setting, where no future frames are available. In this work, we adopt recent off-the-shelf high-quality deep motion models for the motion estimation to recover the camera trajectory and focus on the latter two steps. Our network takes a short 2D camera path in a sliding window as input and outputs the stabilizing warp field of the last frame in the window, which warps the coming frame to its stabilized position. A hybrid loss is well-defined to constrain the spatial and temporal consistency. In addition, we build a motion dataset that contains stable and unstable motion pairs for the training. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art online methods both qualitatively and quantitatively and achieves comparable performance to offline methods.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Fast Nearest Convolution for Real-Time Efficient Image Super-Resolution
Aug 24, 2022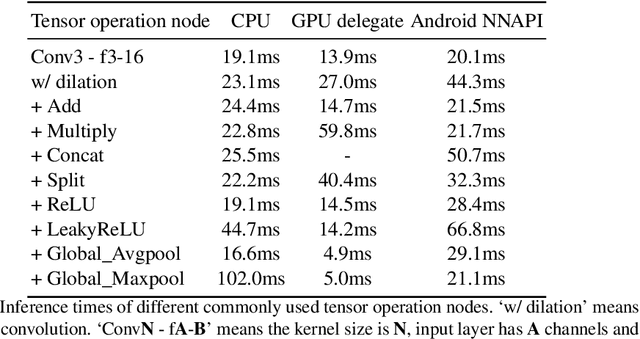
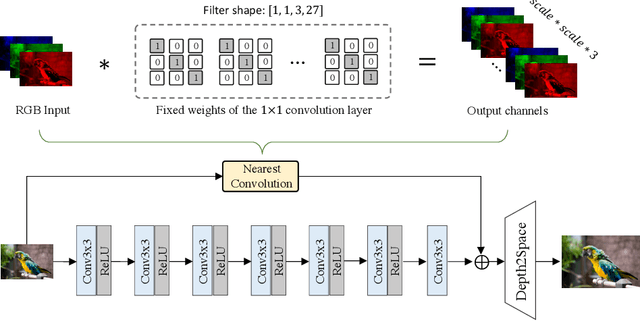
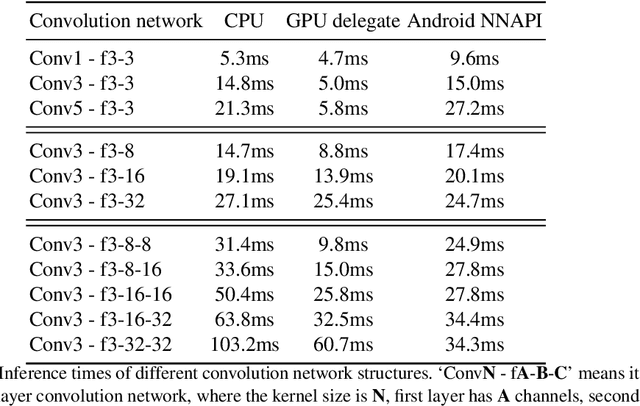

Deep learning-based single image super-resolution (SISR) approaches have drawn much attention and achieved remarkable success on modern advanced GPUs. However, most state-of-the-art methods require a huge number of parameters, memories, and computational resources, which usually show inferior inference times when applying them to current mobile device CPUs/NPUs. In this paper, we propose a simple plain convolution network with a fast nearest convolution module (NCNet), which is NPU-friendly and can perform a reliable super-resolution in real-time. The proposed nearest convolution has the same performance as the nearest upsampling but is much faster and more suitable for Android NNAPI. Our model can be easily deployed on mobile devices with 8-bit quantization and is fully compatible with all major mobile AI accelerators. Moreover, we conduct comprehensive experiments on different tensor operations on a mobile device to illustrate the efficiency of our network architecture. Our NCNet is trained and validated on the DIV2K 3x dataset, and the comparison with other efficient SR methods demonstrated that the NCNet can achieve high fidelity SR results while using fewer inference times. Our codes and pretrained models are publicly available at \url{https://github.com/Algolzw/NCNet}.
Ghost-free High Dynamic Range Imaging with Context-aware Transformer
Aug 10, 2022
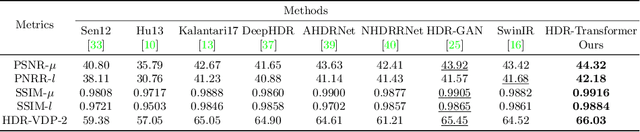
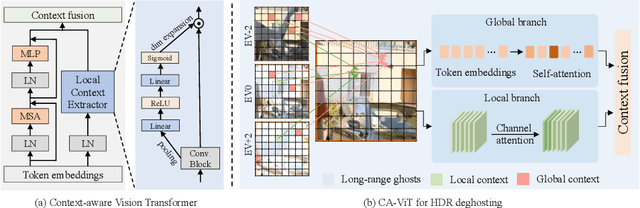

High dynamic range (HDR) deghosting algorithms aim to generate ghost-free HDR images with realistic details. Restricted by the locality of the receptive field, existing CNN-based methods are typically prone to producing ghosting artifacts and intensity distortions in the presence of large motion and severe saturation. In this paper, we propose a novel Context-Aware Vision Transformer (CA-ViT) for ghost-free high dynamic range imaging. The CA-ViT is designed as a dual-branch architecture, which can jointly capture both global and local dependencies. Specifically, the global branch employs a window-based Transformer encoder to model long-range object movements and intensity variations to solve ghosting. For the local branch, we design a local context extractor (LCE) to capture short-range image features and use the channel attention mechanism to select informative local details across the extracted features to complement the global branch. By incorporating the CA-ViT as basic components, we further build the HDR-Transformer, a hierarchical network to reconstruct high-quality ghost-free HDR images. Extensive experiments on three benchmark datasets show that our approach outperforms state-of-the-art methods qualitatively and quantitatively with considerably reduced computational budgets. Codes are available at https://github.com/megvii-research/HDR-Transformer
RealFlow: EM-based Realistic Optical Flow Dataset Generation from Videos
Jul 22, 2022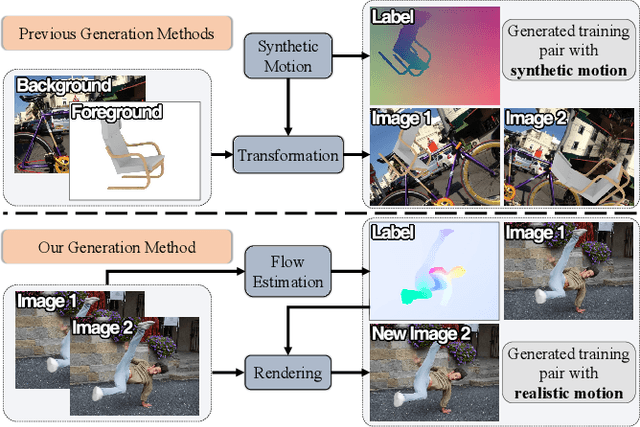
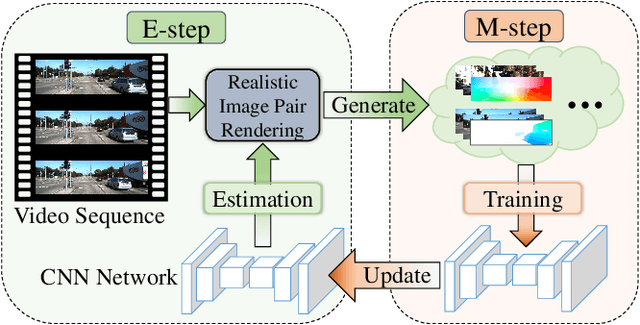
Obtaining the ground truth labels from a video is challenging since the manual annotation of pixel-wise flow labels is prohibitively expensive and laborious. Besides, existing approaches try to adapt the trained model on synthetic datasets to authentic videos, which inevitably suffers from domain discrepancy and hinders the performance for real-world applications. To solve these problems, we propose RealFlow, an Expectation-Maximization based framework that can create large-scale optical flow datasets directly from any unlabeled realistic videos. Specifically, we first estimate optical flow between a pair of video frames, and then synthesize a new image from this pair based on the predicted flow. Thus the new image pairs and their corresponding flows can be regarded as a new training set. Besides, we design a Realistic Image Pair Rendering (RIPR) module that adopts softmax splatting and bi-directional hole filling techniques to alleviate the artifacts of the image synthesis. In the E-step, RIPR renders new images to create a large quantity of training data. In the M-step, we utilize the generated training data to train an optical flow network, which can be used to estimate optical flows in the next E-step. During the iterative learning steps, the capability of the flow network is gradually improved, so is the accuracy of the flow, as well as the quality of the synthesized dataset. Experimental results show that RealFlow outperforms previous dataset generation methods by a considerably large margin. Moreover, based on the generated dataset, our approach achieves state-of-the-art performance on two standard benchmarks compared with both supervised and unsupervised optical flow methods. Our code and dataset are available at https://github.com/megvii-research/RealFlow
Deep Rotation Correction without Angle Prior
Jul 07, 2022



Not everybody can be equipped with professional photography skills and sufficient shooting time, and there can be some tilts in the captured images occasionally. In this paper, we propose a new and practical task, named Rotation Correction, to automatically correct the tilt with high content fidelity in the condition that the rotated angle is unknown. This task can be easily integrated into image editing applications, allowing users to correct the rotated images without any manual operations. To this end, we leverage a neural network to predict the optical flows that can warp the tilted images to be perceptually horizontal. Nevertheless, the pixel-wise optical flow estimation from a single image is severely unstable, especially in large-angle tilted images. To enhance its robustness, we propose a simple but effective prediction strategy to form a robust elastic warp. Particularly, we first regress the mesh deformation that can be transformed into robust initial optical flows. Then we estimate residual optical flows to facilitate our network the flexibility of pixel-wise deformation, further correcting the details of the tilted images. To establish an evaluation benchmark and train the learning framework, a comprehensive rotation correction dataset is presented with a large diversity in scenes and rotated angles. Extensive experiments demonstrate that even in the absence of the angle prior, our algorithm can outperform other state-of-the-art solutions requiring this prior. The codes and dataset will be available at https://github.com/nie-lang/RotationCorrection.
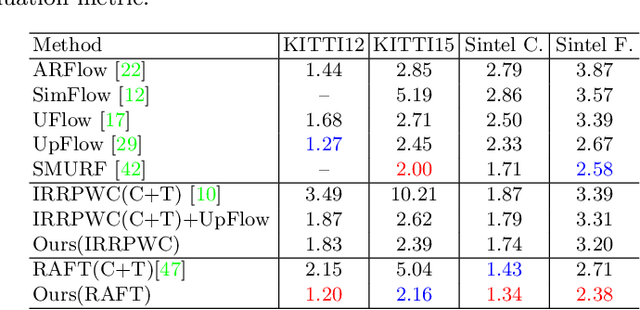
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022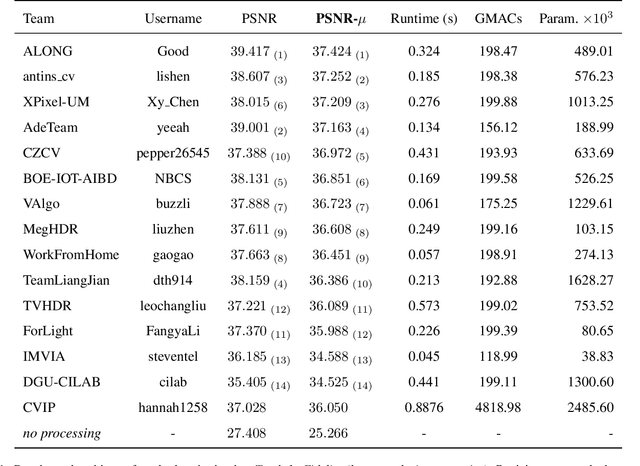
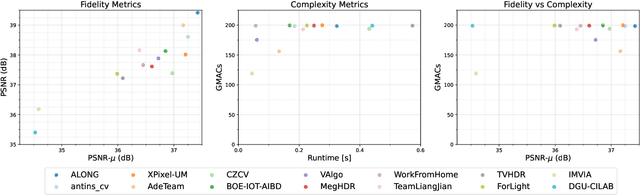
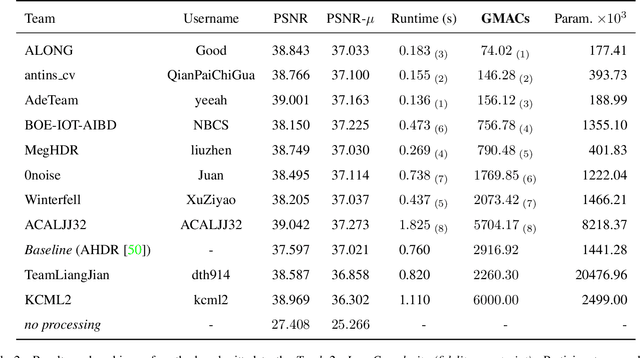
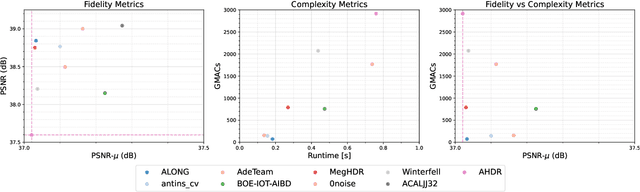
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Thunder: Thumbnail based Fast Lightweight Image Denoising Network
May 24, 2022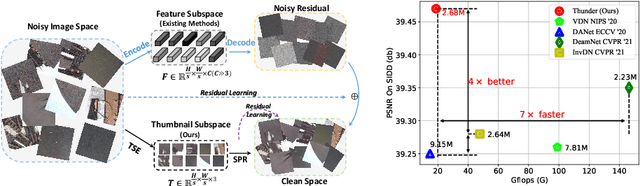
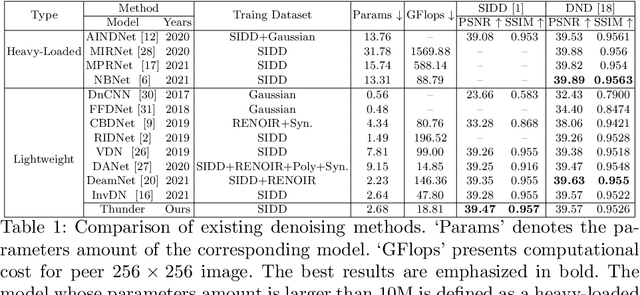
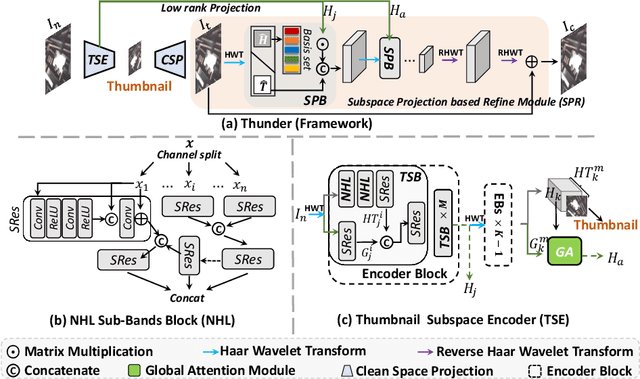
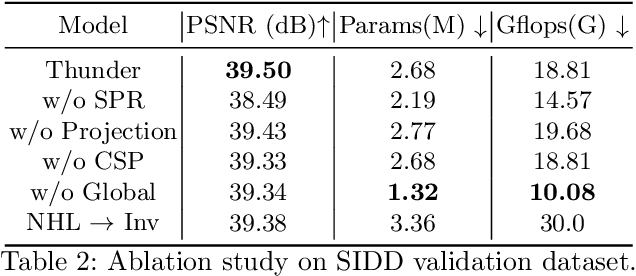
To achieve promising results on removing noise from real-world images, most of existing denoising networks are formulated with complex network structure, making them impractical for deployment. Some attempts focused on reducing the number of filters and feature channels but suffered from large performance loss, and a more practical and lightweight denoising network with fast inference speed is of high demand. To this end, a \textbf{Thu}mb\textbf{n}ail based \textbf{D}\textbf{e}noising Netwo\textbf{r}k dubbed Thunder, is proposed and implemented as a lightweight structure for fast restoration without comprising the denoising capabilities. Specifically, the Thunder model contains two newly-established modules: (1) a wavelet-based Thumbnail Subspace Encoder (TSE) which can leverage sub-bands correlation to provide an approximate thumbnail based on the low-frequent feature; (2) a Subspace Projection based Refine Module (SPR) which can restore the details for thumbnail progressively based on the subspace projection approach. Extensive experiments have been carried out on two real-world denoising benchmarks, demonstrating that the proposed Thunder outperforms the existing lightweight models and achieves competitive performance on PSNR and SSIM when compared with the complex designs.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.