 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Prompts First-Class Citizens for Adaptive LLM Pipelines
Aug 07, 2025Modern LLM pipelines increasingly resemble data-centric systems: they retrieve external context, compose intermediate outputs, validate results, and adapt based on runtime feedback. Yet, the central element guiding this process -- the prompt -- remains a brittle, opaque string, disconnected from the surrounding dataflow. This disconnect limits reuse, optimization, and runtime control. In this paper, we describe our vision and an initial design for SPEAR, a language and runtime that fills this prompt management gap by making prompts structured, adaptive, and first-class components of the execution model. SPEAR enables (1) runtime prompt refinement -- modifying prompts dynamically in response to execution-time signals such as confidence, latency, or missing context; and (2) structured prompt management -- organizing prompt fragments into versioned views with support for introspection and logging. SPEAR defines a prompt algebra that governs how prompts are constructed and adapted within a pipeline. It supports multiple refinement modes (manual, assisted, and automatic), giving developers a balance between control and automation. By treating prompt logic as structured data, SPEAR enables optimizations such as operator fusion, prefix caching, and view reuse. Preliminary experiments quantify the behavior of different refinement modes compared to static prompts and agentic retries, as well as the impact of prompt-level optimizations such as operator fusion.
ALTO: An Efficient Network Orchestrator for Compound AI Systems
Mar 07, 2024We present ALTO, a network orchestrator for efficiently serving compound AI systems such as pipelines of language models. ALTO achieves high throughput and low latency by taking advantage of an optimization opportunity specific to generative language models: streaming intermediate outputs. As language models produce outputs token by token, ALTO exposes opportunities to stream intermediate outputs between stages when possible. We highlight two new challenges of correctness and load balancing which emerge when streaming intermediate data across distributed pipeline stage instances. We also motivate the need for an aggregation-aware routing interface and distributed prompt-aware scheduling to address these challenges. We demonstrate the impact of ALTO's partial output streaming on a complex chatbot verification pipeline, increasing throughput by up to 3x for a fixed latency target of 4 seconds / request while also reducing tail latency by 1.8x compared to a baseline serving approach.
Model Assertions for Monitoring and Improving ML Models
Mar 11, 2020

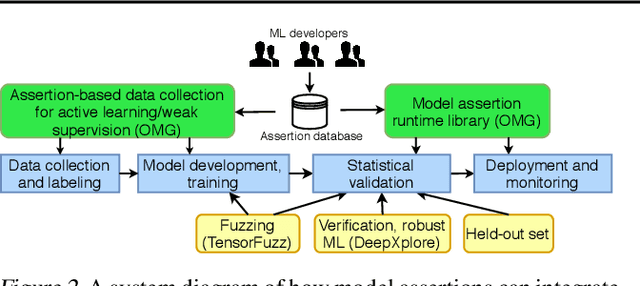

ML models are increasingly deployed in settings with real world interactions such as vehicles, but unfortunately, these models can fail in systematic ways. To prevent errors, ML engineering teams monitor and continuously improve these models. We propose a new abstraction, model assertions, that adapts the classical use of program assertions as a way to monitor and improve ML models. Model assertions are arbitrary functions over a model's input and output that indicate when errors may be occurring, e.g., a function that triggers if an object rapidly changes its class in a video. We propose methods of using model assertions at all stages of ML system deployment, including runtime monitoring, validating labels, and continuously improving ML models. For runtime monitoring, we show that model assertions can find high confidence errors, where a model returns the wrong output with high confidence, which uncertainty-based monitoring techniques would not detect. For training, we propose two methods of using model assertions. First, we propose a bandit-based active learning algorithm that can sample from data flagged by assertions and show that it can reduce labeling costs by up to 40% over traditional uncertainty-based methods. Second, we propose an API for generating "consistency assertions" (e.g., the class change example) and weak labels for inputs where the consistency assertions fail, and show that these weak labels can improve relative model quality by up to 46%. We evaluate model assertions on four real-world tasks with video, LIDAR, and ECG data.