 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvalancheBench: Evaluating Enterprise Data Agents Through Latent World Recovery
May 22, 2026We introduce AvalancheBench, a benchmark for evaluating enterprise data agents through \emph{latent world recovery}. AvalancheBench improves on existing benchmarks in three ways. First, it evaluates analytical understanding rather than pipeline completion: systems are scored on whether they recover the segments, drivers, temporal events, and relationships that explain the data, not merely on whether they execute a workflow or produce a plausible report. Second, it provides ground truth for goal-driven analytics by generating observations from a known latent world, enabling partial credit for incomplete but valid recoveries. Third, it exposes how early analytical mistakes propagate into later conclusions: missed segments, merged events, or wrong attributions can lead to systematically wrong recommendations. In this sense, AvalancheBench complements real-data benchmarks by providing a controlled setting for diagnosing whether agents recover the analytical structure behind enterprise data. On a first e-commerce use case, the strongest configuration of a leading coding agent recovers only 26\% of the rubric, with failures concentrated in generic customer segmentations and merged temporal events.
Making Prompts First-Class Citizens for Adaptive LLM Pipelines
Aug 07, 2025Modern LLM pipelines increasingly resemble data-centric systems: they retrieve external context, compose intermediate outputs, validate results, and adapt based on runtime feedback. Yet, the central element guiding this process -- the prompt -- remains a brittle, opaque string, disconnected from the surrounding dataflow. This disconnect limits reuse, optimization, and runtime control. In this paper, we describe our vision and an initial design for SPEAR, a language and runtime that fills this prompt management gap by making prompts structured, adaptive, and first-class components of the execution model. SPEAR enables (1) runtime prompt refinement -- modifying prompts dynamically in response to execution-time signals such as confidence, latency, or missing context; and (2) structured prompt management -- organizing prompt fragments into versioned views with support for introspection and logging. SPEAR defines a prompt algebra that governs how prompts are constructed and adapted within a pipeline. It supports multiple refinement modes (manual, assisted, and automatic), giving developers a balance between control and automation. By treating prompt logic as structured data, SPEAR enables optimizations such as operator fusion, prefix caching, and view reuse. Preliminary experiments quantify the behavior of different refinement modes compared to static prompts and agentic retries, as well as the impact of prompt-level optimizations such as operator fusion.
An End-to-end Neural Natural Language Interface for Databases
Apr 02, 2018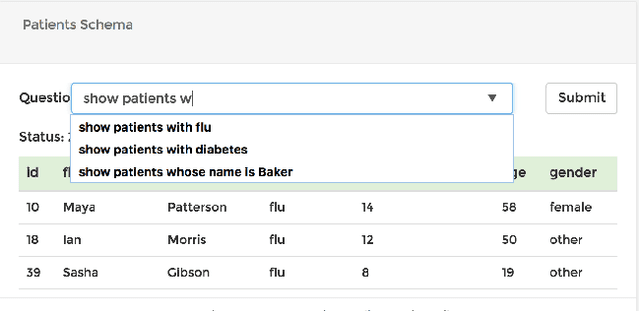
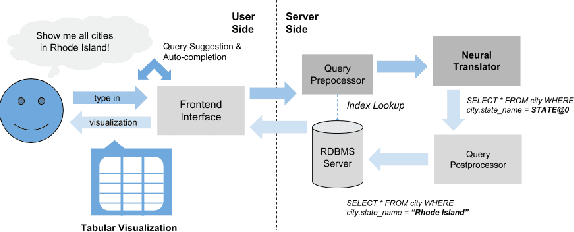
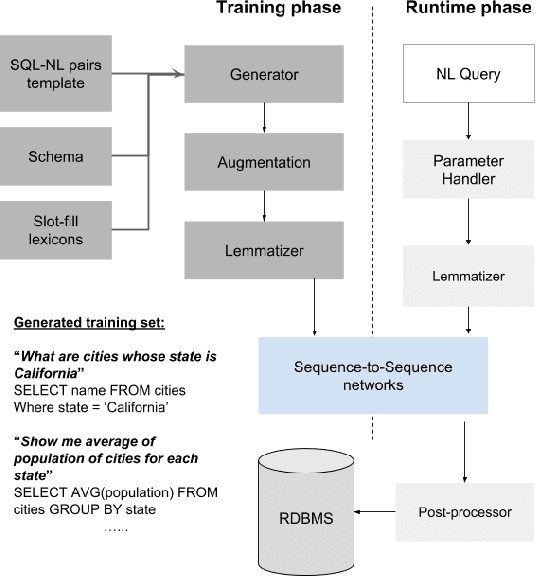
The ability to extract insights from new data sets is critical for decision making. Visual interactive tools play an important role in data exploration since they provide non-technical users with an effective way to visually compose queries and comprehend the results. Natural language has recently gained traction as an alternative query interface to databases with the potential to enable non-expert users to formulate complex questions and information needs efficiently and effectively. However, understanding natural language questions and translating them accurately to SQL is a challenging task, and thus Natural Language Interfaces for Databases (NLIDBs) have not yet made their way into practical tools and commercial products. In this paper, we present DBPal, a novel data exploration tool with a natural language interface. DBPal leverages recent advances in deep models to make query understanding more robust in the following ways: First, DBPal uses a deep model to translate natural language statements to SQL, making the translation process more robust to paraphrasing and other linguistic variations. Second, to support the users in phrasing questions without knowing the database schema and the query features, DBPal provides a learned auto-completion model that suggests partial query extensions to users during query formulation and thus helps to write complex queries.
The VC-Dimension of Queries and Selectivity Estimation Through Sampling
Aug 11, 2011

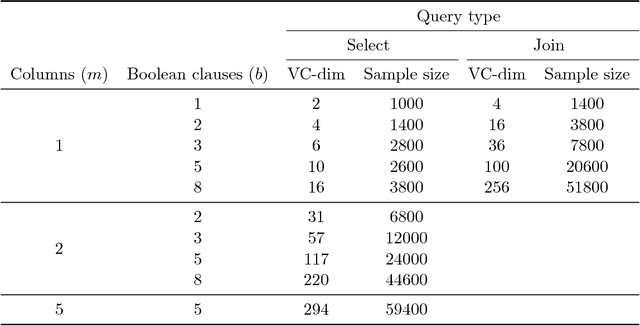
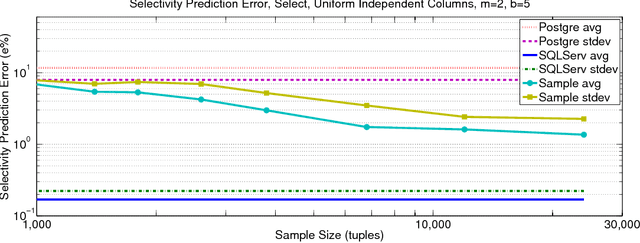
We develop a novel method, based on the statistical concept of the Vapnik-Chervonenkis dimension, to evaluate the selectivity (output cardinality) of SQL queries - a crucial step in optimizing the execution of large scale database and data-mining operations. The major theoretical contribution of this work, which is of independent interest, is an explicit bound to the VC-dimension of a range space defined by all possible outcomes of a collection (class) of queries. We prove that the VC-dimension is a function of the maximum number of Boolean operations in the selection predicate and of the maximum number of select and join operations in any individual query in the collection, but it is neither a function of the number of queries in the collection nor of the size (number of tuples) of the database. We leverage on this result and develop a method that, given a class of queries, builds a concise random sample of a database, such that with high probability the execution of any query in the class on the sample provides an accurate estimate for the selectivity of the query on the original large database. The error probability holds simultaneously for the selectivity estimates of all queries in the collection, thus the same sample can be used to evaluate the selectivity of multiple queries, and the sample needs to be refreshed only following major changes in the database. The sample representation computed by our method is typically sufficiently small to be stored in main memory. We present extensive experimental results, validating our theoretical analysis and demonstrating the advantage of our technique when compared to complex selectivity estimation techniques used in PostgreSQL and the Microsoft SQL Server.