 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSR: A Unified Framework for Document Layout Analysis combining Vision, Semantics and Relations
May 13, 2021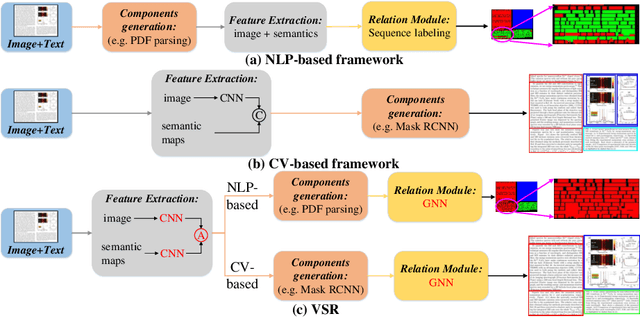
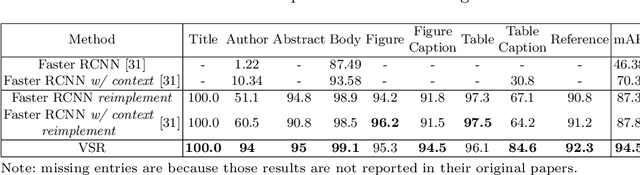
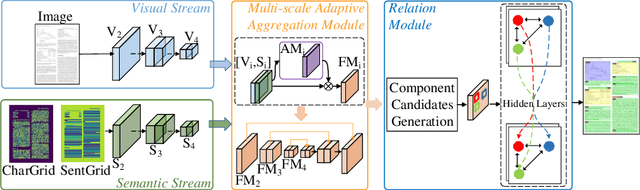
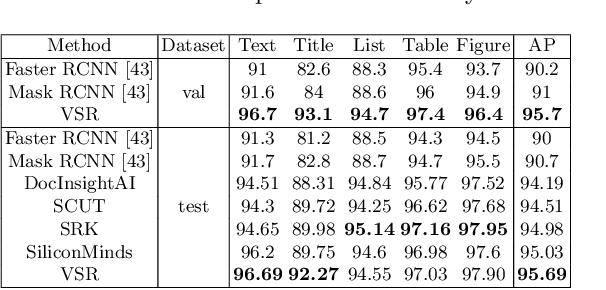
Document layout analysis is crucial for understanding document structures. On this task, vision and semantics of documents, and relations between layout components contribute to the understanding process. Though many works have been proposed to exploit the above information, they show unsatisfactory results. NLP-based methods model layout analysis as a sequence labeling task and show insufficient capabilities in layout modeling. CV-based methods model layout analysis as a detection or segmentation task, but bear limitations of inefficient modality fusion and lack of relation modeling between layout components. To address the above limitations, we propose a unified framework VSR for document layout analysis, combining vision, semantics and relations. VSR supports both NLP-based and CV-based methods. Specifically, we first introduce vision through document image and semantics through text embedding maps. Then, modality-specific visual and semantic features are extracted using a two-stream network, which are adaptively fused to make full use of complementary information. Finally, given component candidates, a relation module based on graph neural network is incorported to model relations between components and output final results. On three popular benchmarks, VSR outperforms previous models by large margins. Code will be released soon.
Modulating Localization and Classification for Harmonized Object Detection
Mar 25, 2021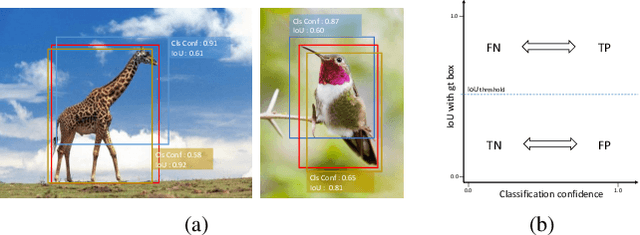

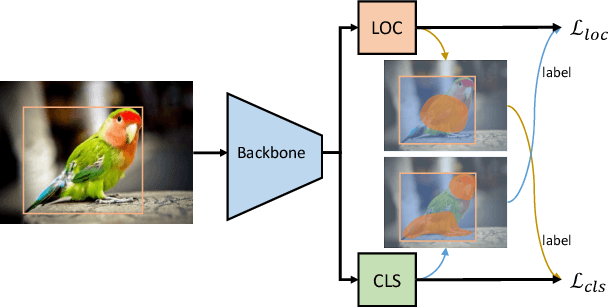
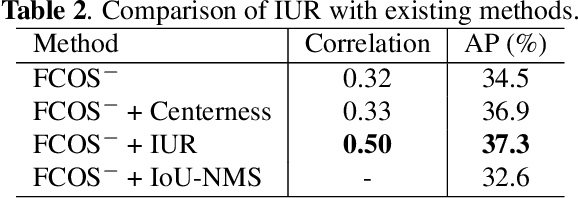
Object detection involves two sub-tasks, i.e. localizing objects in an image and classifying them into various categories. For existing CNN-based detectors, we notice the widespread divergence between localization and classification, which leads to degradation in performance. In this work, we propose a mutual learning framework to modulate the two tasks. In particular, the two tasks are forced to learn from each other with a novel mutual labeling strategy. Besides, we introduce a simple yet effective IoU rescoring scheme, which further reduces the divergence. Moreover, we define a Spearman rank correlation-based metric to quantify the divergence, which correlates well with the detection performance. The proposed approach is general-purpose and can be easily injected into existing detectors such as FCOS and RetinaNet. We achieve a significant performance gain over the baseline detectors on the COCO dataset.
RPVNet: A Deep and Efficient Range-Point-Voxel Fusion Network for LiDAR Point Cloud Segmentation
Mar 24, 2021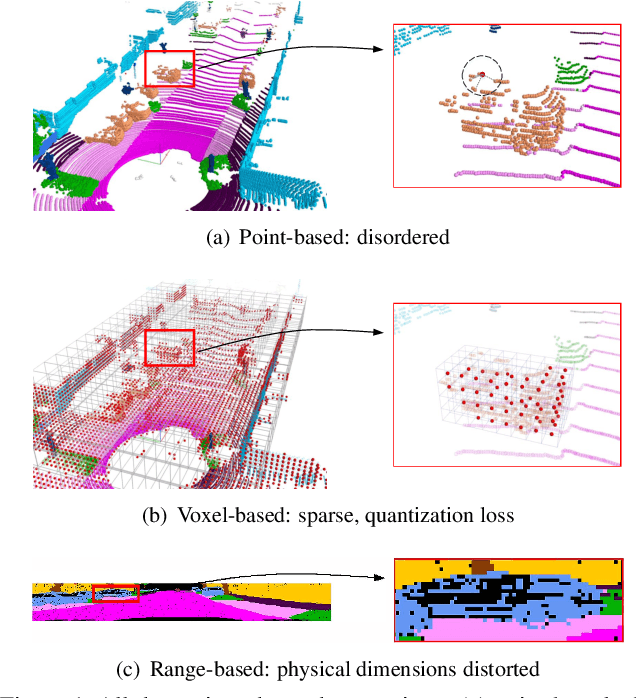
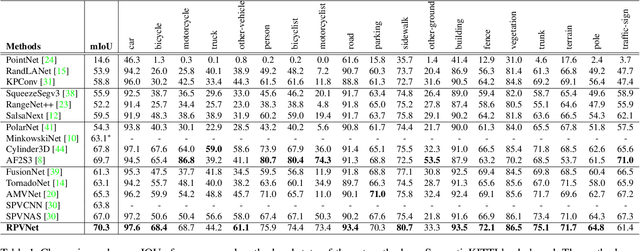
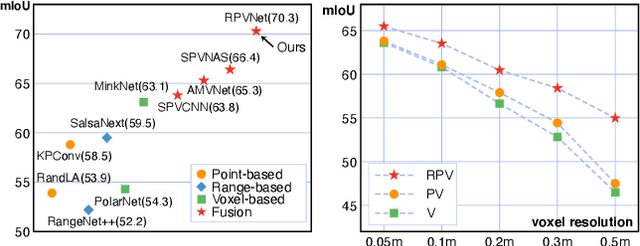

Point clouds can be represented in many forms (views), typically, point-based sets, voxel-based cells or range-based images(i.e., panoramic view). The point-based view is geometrically accurate, but it is disordered, which makes it difficult to find local neighbors efficiently. The voxel-based view is regular, but sparse, and computation grows cubically when voxel resolution increases. The range-based view is regular and generally dense, however spherical projection makes physical dimensions distorted. Both voxel- and range-based views suffer from quantization loss, especially for voxels when facing large-scale scenes. In order to utilize different view's advantages and alleviate their own shortcomings in fine-grained segmentation task, we propose a novel range-point-voxel fusion network, namely RPVNet. In this network, we devise a deep fusion framework with multiple and mutual information interactions among these three views and propose a gated fusion module (termed as GFM), which can adaptively merge the three features based on concurrent inputs. Moreover, the proposed RPV interaction mechanism is highly efficient, and we summarize it into a more general formulation. By leveraging this efficient interaction and relatively lower voxel resolution, our method is also proved to be more efficient. Finally, we evaluated the proposed model on two large-scale datasets, i.e., SemanticKITTI and nuScenes, and it shows state-of-the-art performance on both of them. Note that, our method currently ranks 1st on SemanticKITTI leaderboard without any extra tricks.
Ground-SLAM: Ground Constrained LiDAR SLAM for Structured Multi-Floor Environments
Mar 05, 2021

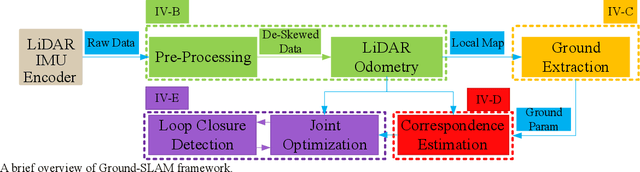
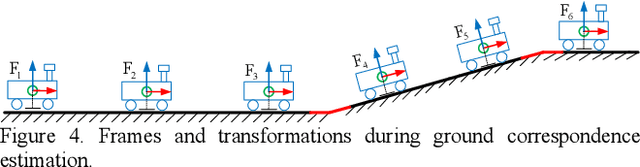
This paper proposes a 3D LiDAR SLAM algorithm named Ground-SLAM, which exploits grounds in structured multi-floor environments to compress the pose drift mainly caused by LiDAR measurement bias. Ground-SLAM is developed based on the well-known pose graph optimization framework. In the front-end, motion estimation is conducted using LiDAR Odometry (LO) with a novel sensor-centric sliding map introduced, which is maintained by filtering out expired features based on the model of error propagation. At each key-frame, the sliding map is recorded as a local map. The ground nearby is extracted and modelled as an infinite planar landmark in the form of Closest Point (CP) parameterization. Then, ground planes observed at different key-frames are associated, and the ground constraints are fused into the pose graph optimization framework to compress the pose drift of LO. Finally, loop-closure detection is carried out, and the residual error is jointly minimized, which could lead to a globally consistent map. Experimental results demonstrate superior performances in the accuracy of the proposed approach.
Multi-Level Adaptive Region of Interest and Graph Learning for Facial Action Unit Recognition
Feb 24, 2021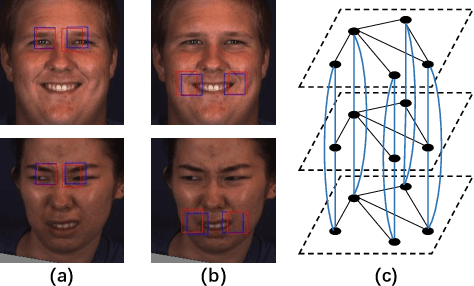

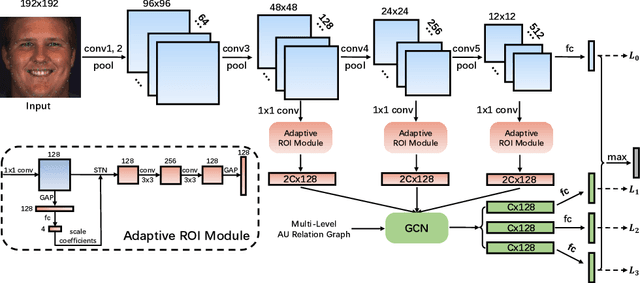
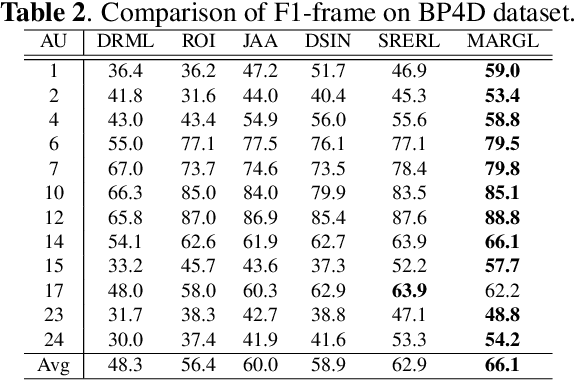
In facial action unit (AU) recognition tasks, regional feature learning and AU relation modeling are two effective aspects which are worth exploring. However, the limited representation capacity of regional features makes it difficult for relation models to embed AU relationship knowledge. In this paper, we propose a novel multi-level adaptive ROI and graph learning (MARGL) framework to tackle this problem. Specifically, an adaptive ROI learning module is designed to automatically adjust the location and size of the predefined AU regions. Meanwhile, besides relationship between AUs, there exists strong relevance between regional features across multiple levels of the backbone network as level-wise features focus on different aspects of representation. In order to incorporate the intra-level AU relation and inter-level AU regional relevance simultaneously, a multi-level AU relation graph is constructed and graph convolution is performed to further enhance AU regional features of each level. Experiments on BP4D and DISFA demonstrate the proposed MARGL significantly outperforms the previous state-of-the-art methods.
Self-Domain Adaptation for Face Anti-Spoofing
Feb 24, 2021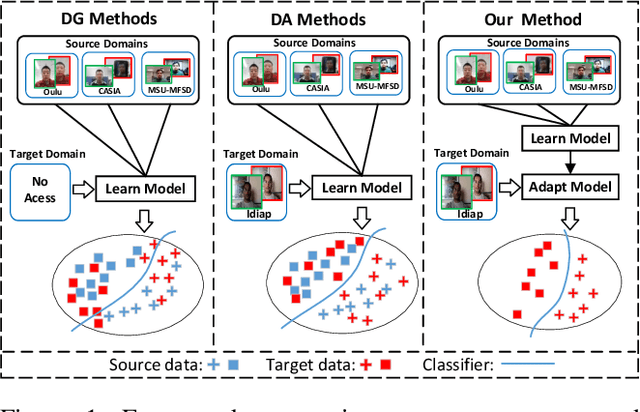
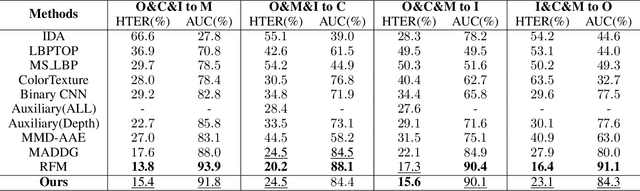
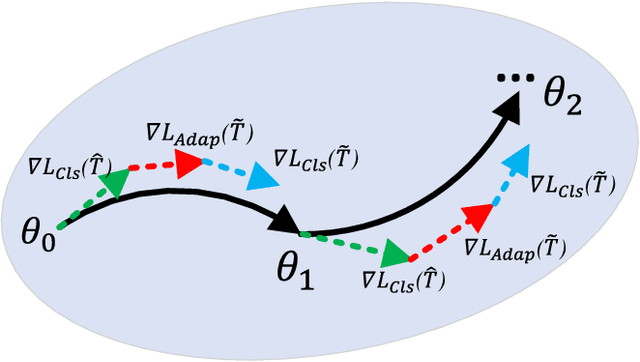

Although current face anti-spoofing methods achieve promising results under intra-dataset testing, they suffer from poor generalization to unseen attacks. Most existing works adopt domain adaptation (DA) or domain generalization (DG) techniques to address this problem. However, the target domain is often unknown during training which limits the utilization of DA methods. DG methods can conquer this by learning domain invariant features without seeing any target data. However, they fail in utilizing the information of target data. In this paper, we propose a self-domain adaptation framework to leverage the unlabeled test domain data at inference. Specifically, a domain adaptor is designed to adapt the model for test domain. In order to learn a better adaptor, a meta-learning based adaptor learning algorithm is proposed using the data of multiple source domains at the training step. At test time, the adaptor is updated using only the test domain data according to the proposed unsupervised adaptor loss to further improve the performance. Extensive experiments on four public datasets validate the effectiveness of the proposed method.
Self-Supervised Noisy Label Learning for Source-Free Unsupervised Domain Adaptation
Feb 23, 2021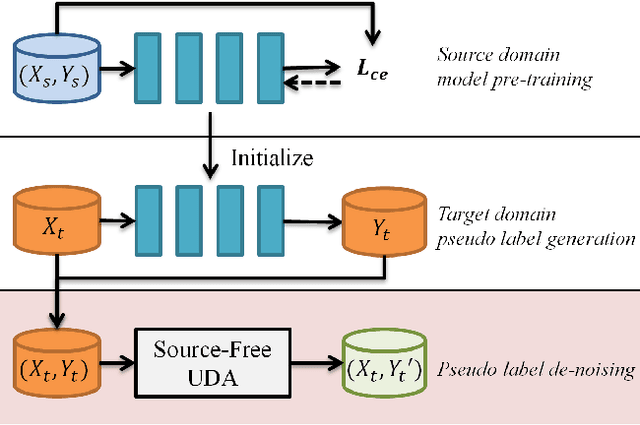

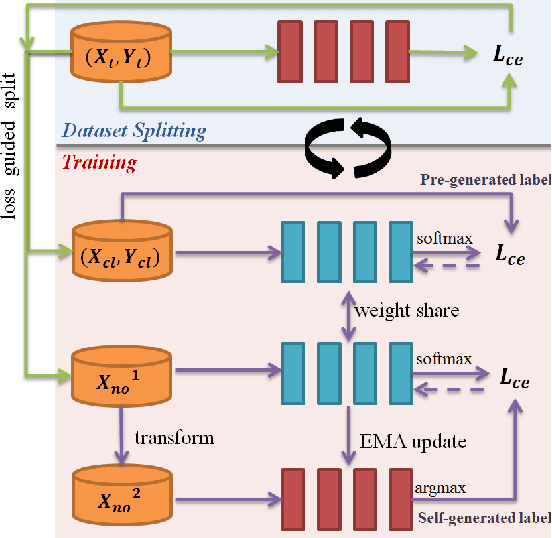

It is a strong prerequisite to access source data freely in many existing unsupervised domain adaptation approaches. However, source data is agnostic in many practical scenarios due to the constraints of expensive data transmission and data privacy protection. Usually, the given source domain pre-trained model is expected to optimize with only unlabeled target data, which is termed as source-free unsupervised domain adaptation. In this paper, we solve this problem from the perspective of noisy label learning, since the given pre-trained model can pre-generate noisy label for unlabeled target data via directly network inference. Under this problem modeling, incorporating self-supervised learning, we propose a novel Self-Supervised Noisy Label Learning method, which can effectively fine-tune the pre-trained model with pre-generated label as well as selfgenerated label on the fly. Extensive experiments had been conducted to validate its effectiveness. Our method can easily achieve state-of-the-art results and surpass other methods by a very large margin. Code will be released.
Box Re-Ranking: Unsupervised False Positive Suppression for Domain Adaptive Pedestrian Detection
Feb 01, 2021
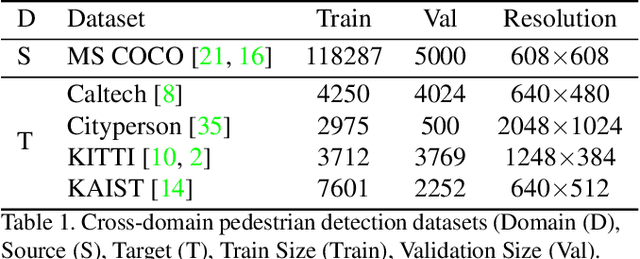
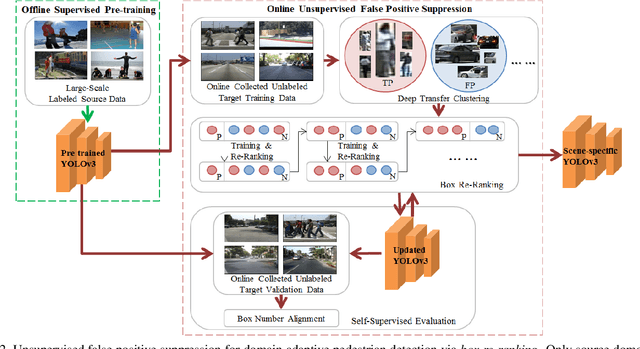
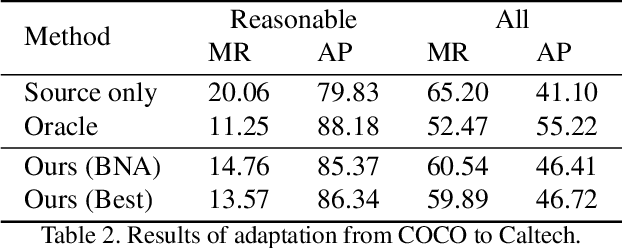
False positive is one of the most serious problems brought by agnostic domain shift in domain adaptive pedestrian detection. However, it is impossible to label each box in countless target domains. Therefore, it yields our attention to suppress false positive in each target domain in an unsupervised way. In this paper, we model an object detection task into a ranking task among positive and negative boxes innovatively, and thus transform a false positive suppression problem into a box re-ranking problem elegantly, which makes it feasible to solve without manual annotation. An attached problem during box re-ranking appears that no labeled validation data is available for cherrypicking. Considering we aim to keep the detection of true positive unchanged, we propose box number alignment, a self-supervised evaluation metric, to prevent the optimized model from capacity degeneration. Extensive experiments conducted on cross-domain pedestrian detection datasets have demonstrated the effectiveness of our proposed framework. Furthermore, the extension to two general unsupervised domain adaptive object detection benchmarks also supports our superiority to other state-of-the-arts.
A Free Lunch for Unsupervised Domain Adaptive Object Detection without Source Data
Dec 10, 2020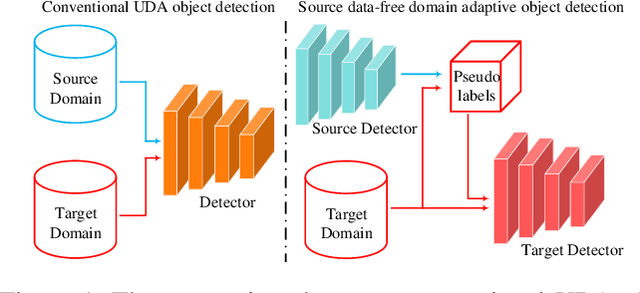
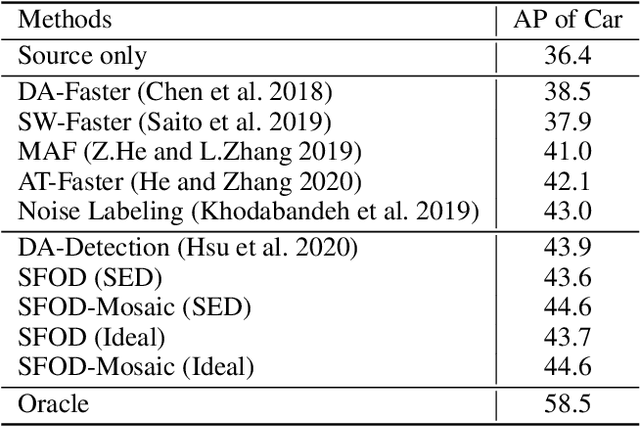
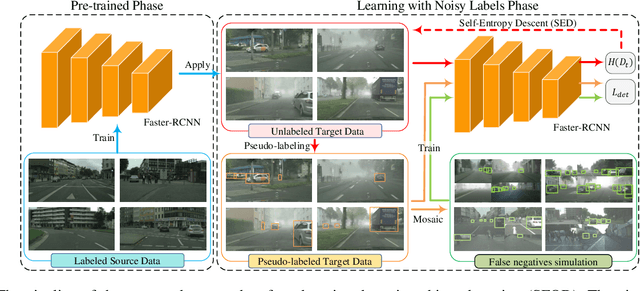
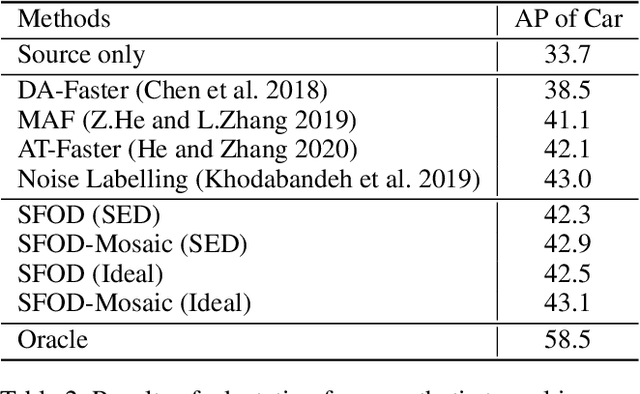
Unsupervised domain adaptation (UDA) assumes that source and target domain data are freely available and usually trained together to reduce the domain gap. However, considering the data privacy and the inefficiency of data transmission, it is impractical in real scenarios. Hence, it draws our eyes to optimize the network in the target domain without accessing labeled source data. To explore this direction in object detection, for the first time, we propose a source data-free domain adaptive object detection (SFOD) framework via modeling it into a problem of learning with noisy labels. Generally, a straightforward method is to leverage the pre-trained network from the source domain to generate the pseudo labels for target domain optimization. However, it is difficult to evaluate the quality of pseudo labels since no labels are available in target domain. In this paper, self-entropy descent (SED) is a metric proposed to search an appropriate confidence threshold for reliable pseudo label generation without using any handcrafted labels. Nonetheless, completely clean labels are still unattainable. After a thorough experimental analysis, false negatives are found to dominate in the generated noisy labels. Undoubtedly, false negatives mining is helpful for performance improvement, and we ease it to false negatives simulation through data augmentation like Mosaic. Extensive experiments conducted in four representative adaptation tasks have demonstrated that the proposed framework can easily achieve state-of-the-art performance. From another view, it also reminds the UDA community that the labeled source data are not fully exploited in the existing methods.
MANGO: A Mask Attention Guided One-Stage Scene Text Spotter
Dec 08, 2020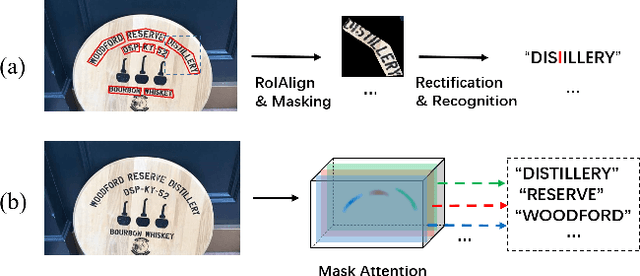
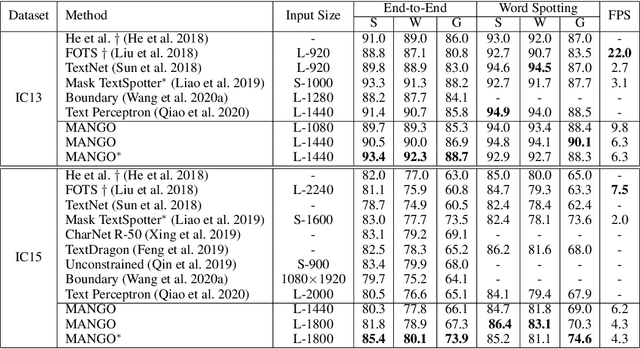
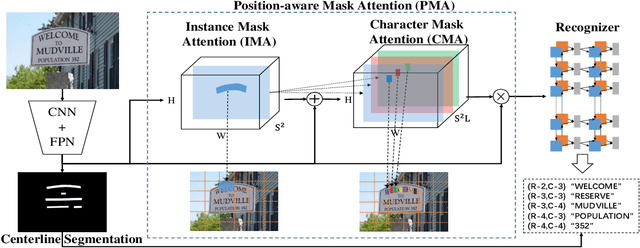
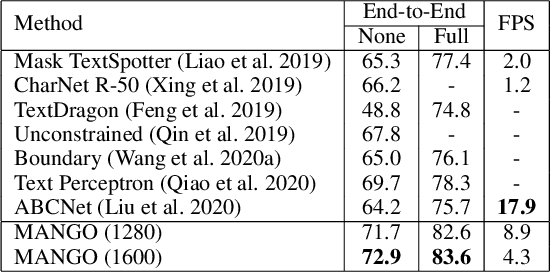
Recently end-to-end scene text spotting has become a popular research topic due to its advantages of global optimization and high maintainability in real applications. Most methods attempt to develop various region of interest (RoI) operations to concatenate the detection part and the sequence recognition part into a two-stage text spotting framework. However, in such framework, the recognition part is highly sensitive to the detected results (\emph{e.g.}, the compactness of text contours). To address this problem, in this paper, we propose a novel Mask AttentioN Guided One-stage text spotting framework named MANGO, in which character sequences can be directly recognized without RoI operation. Concretely, a position-aware mask attention module is developed to generate attention weights on each text instance and its characters. It allows different text instances in an image to be allocated on different feature map channels which are further grouped as a batch of instance features. Finally, a lightweight sequence decoder is applied to generate the character sequences. It is worth noting that MANGO inherently adapts to arbitrary-shaped text spotting and can be trained end-to-end with only coarse position information (\emph{e.g.}, rectangular bounding box) and text annotations. Experimental results show that the proposed method achieves competitive and even new state-of-the-art performance on both regular and irregular text spotting benchmarks, i.e., ICDAR 2013, ICDAR 2015, Total-Text, and SCUT-CTW1500.