 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMlingConf: A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Oct 16, 2024



The tendency of Large Language Models (LLMs) to generate hallucinations raises concerns regarding their reliability. Therefore, confidence estimations indicating the extent of trustworthiness of the generations become essential. However, current LLM confidence estimations in languages other than English remain underexplored. This paper addresses this gap by introducing a comprehensive investigation of Multilingual Confidence estimation (MlingConf) on LLMs, focusing on both language-agnostic (LA) and language-specific (LS) tasks to explore the performance and language dominance effects of multilingual confidence estimations on different tasks. The benchmark comprises four meticulously checked and human-evaluate high-quality multilingual datasets for LA tasks and one for the LS task tailored to specific social, cultural, and geographical contexts of a language. Our experiments reveal that on LA tasks English exhibits notable linguistic dominance in confidence estimations than other languages, while on LS tasks, using question-related language to prompt LLMs demonstrates better linguistic dominance in multilingual confidence estimations. The phenomena inspire a simple yet effective native-tone prompting strategy by employing language-specific prompts for LS tasks, effectively improving LLMs' reliability and accuracy on LS tasks.
MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models
Oct 16, 2024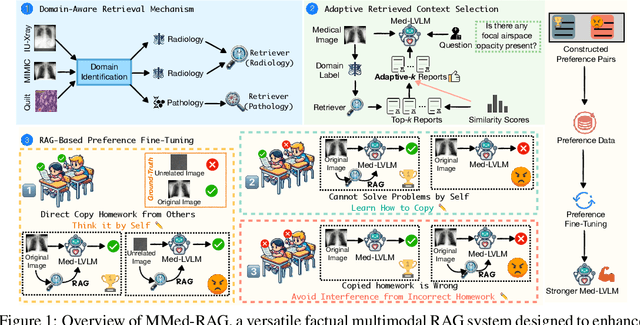
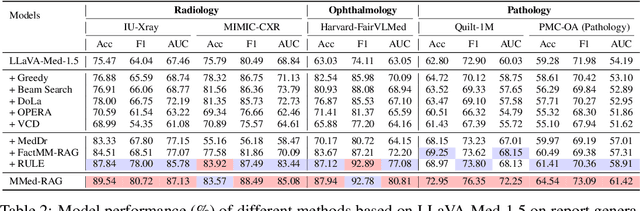
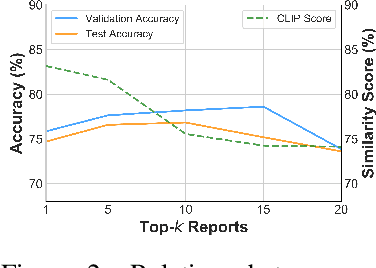
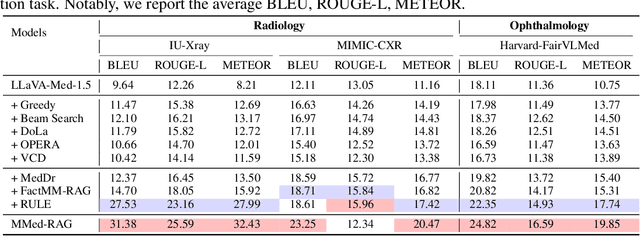
Artificial Intelligence (AI) has demonstrated significant potential in healthcare, particularly in disease diagnosis and treatment planning. Recent progress in Medical Large Vision-Language Models (Med-LVLMs) has opened up new possibilities for interactive diagnostic tools. However, these models often suffer from factual hallucination, which can lead to incorrect diagnoses. Fine-tuning and retrieval-augmented generation (RAG) have emerged as methods to address these issues. However, the amount of high-quality data and distribution shifts between training data and deployment data limit the application of fine-tuning methods. Although RAG is lightweight and effective, existing RAG-based approaches are not sufficiently general to different medical domains and can potentially cause misalignment issues, both between modalities and between the model and the ground truth. In this paper, we propose a versatile multimodal RAG system, MMed-RAG, designed to enhance the factuality of Med-LVLMs. Our approach introduces a domain-aware retrieval mechanism, an adaptive retrieved contexts selection method, and a provable RAG-based preference fine-tuning strategy. These innovations make the RAG process sufficiently general and reliable, significantly improving alignment when introducing retrieved contexts. Experimental results across five medical datasets (involving radiology, ophthalmology, pathology) on medical VQA and report generation demonstrate that MMed-RAG can achieve an average improvement of 43.8% in the factual accuracy of Med-LVLMs. Our data and code are available in https://github.com/richard-peng-xia/MMed-RAG.
Unleashing the Power of LLMs as Multi-Modal Encoders for Text and Graph-Structured Data
Oct 15, 2024



Graph-structured information offers rich contextual information that can enhance language models by providing structured relationships and hierarchies, leading to more expressive embeddings for various applications such as retrieval, question answering, and classification. However, existing methods for integrating graph and text embeddings, often based on Multi-layer Perceptrons (MLPs) or shallow transformers, are limited in their ability to fully exploit the heterogeneous nature of these modalities. To overcome this, we propose Janus, a simple yet effective framework that leverages Large Language Models (LLMs) to jointly encode text and graph data. Specifically, Janus employs an MLP adapter to project graph embeddings into the same space as text embeddings, allowing the LLM to process both modalities jointly. Unlike prior work, we also introduce contrastive learning to align the graph and text spaces more effectively, thereby improving the quality of learned joint embeddings. Empirical results across six datasets spanning three tasks, knowledge graph-contextualized question answering, graph-text pair classification, and retrieval, demonstrate that Janus consistently outperforms existing baselines, achieving significant improvements across multiple datasets, with gains of up to 11.4% in QA tasks. These results highlight Janus's effectiveness in integrating graph and text data. Ablation studies further validate the effectiveness of our method.
QSpec: Speculative Decoding with Complementary Quantization Schemes
Oct 15, 2024



Quantization has been substantially adopted to accelerate inference and reduce memory consumption of large language models (LLMs). While activation-weight joint quantization speeds up the inference process through low-precision kernels, we demonstrate that it suffers severe performance degradation on multi-step reasoning tasks, rendering it ineffective. We propose a novel quantization paradigm called QSPEC, which seamlessly integrates two complementary quantization schemes for speculative decoding. Leveraging nearly cost-free execution switching, QSPEC drafts tokens with low-precision, fast activation-weight quantization, and verifies them with high-precision weight-only quantization, effectively combining the strengths of both quantization schemes. Compared to high-precision quantization methods, QSPEC empirically boosts token generation throughput by up to 1.80x without any quality compromise, distinguishing it from other low-precision quantization approaches. This enhancement is also consistent across various serving tasks, model sizes, quantization methods, and batch sizes. Unlike existing speculative decoding techniques, our approach reuses weights and the KV cache, avoiding additional memory overhead. Furthermore, QSPEC offers a plug-and-play advantage without requiring any training. We believe that QSPEC demonstrates unique strengths for future deployment of high-fidelity quantization schemes, particularly in memory-constrained scenarios (e.g., edge devices).
MoS: Unleashing Parameter Efficiency of Low-Rank Adaptation with Mixture of Shards
Oct 01, 2024



The rapid scaling of large language models necessitates more lightweight finetuning methods to reduce the explosive GPU memory overhead when numerous customized models are served simultaneously. Targeting more parameter-efficient low-rank adaptation (LoRA), parameter sharing presents a promising solution. Empirically, our research into high-level sharing principles highlights the indispensable role of differentiation in reversing the detrimental effects of pure sharing. Guided by this finding, we propose Mixture of Shards (MoS), incorporating both inter-layer and intra-layer sharing schemes, and integrating four nearly cost-free differentiation strategies, namely subset selection, pair dissociation, vector sharding, and shard privatization. Briefly, it selects a designated number of shards from global pools with a Mixture-of-Experts (MoE)-like routing mechanism before sequentially concatenating them to low-rank matrices. Hence, it retains all the advantages of LoRA while offering enhanced parameter efficiency, and effectively circumvents the drawbacks of peer parameter-sharing methods. Our empirical experiments demonstrate approximately 8x parameter savings in a standard LoRA setting. The ablation study confirms the significance of each component. Our insights into parameter sharing and MoS method may illuminate future developments of more parameter-efficient finetuning methods.
How Far Can Cantonese NLP Go? Benchmarking Cantonese Capabilities of Large Language Models
Aug 29, 2024



The rapid evolution of large language models (LLMs) has transformed the competitive landscape in natural language processing (NLP), particularly for English and other data-rich languages. However, underrepresented languages like Cantonese, spoken by over 85 million people, face significant development gaps, which is particularly concerning given the economic significance of the Guangdong-Hong Kong-Macau Greater Bay Area, and in substantial Cantonese-speaking populations in places like Singapore and North America. Despite its wide use, Cantonese has scant representation in NLP research, especially compared to other languages from similarly developed regions. To bridge these gaps, we outline current Cantonese NLP methods and introduce new benchmarks designed to evaluate LLM performance in factual generation, mathematical logic, complex reasoning, and general knowledge in Cantonese, which aim to advance open-source Cantonese LLM technology. We also propose future research directions and recommended models to enhance Cantonese LLM development.
OCTCube: A 3D foundation model for optical coherence tomography that improves cross-dataset, cross-disease, cross-device and cross-modality analysis
Aug 20, 2024Optical coherence tomography (OCT) has become critical for diagnosing retinal diseases as it enables 3D images of the retina and optic nerve. OCT acquisition is fast, non-invasive, affordable, and scalable. Due to its broad applicability, massive numbers of OCT images have been accumulated in routine exams, making it possible to train large-scale foundation models that can generalize to various diagnostic tasks using OCT images. Nevertheless, existing foundation models for OCT only consider 2D image slices, overlooking the rich 3D structure. Here, we present OCTCube, a 3D foundation model pre-trained on 26,605 3D OCT volumes encompassing 1.62 million 2D OCT images. OCTCube is developed based on 3D masked autoencoders and exploits FlashAttention to reduce the larger GPU memory usage caused by modeling 3D volumes. OCTCube outperforms 2D models when predicting 8 retinal diseases in both inductive and cross-dataset settings, indicating that utilizing the 3D structure in the model instead of 2D data results in significant improvement. OCTCube further shows superior performance on cross-device prediction and when predicting systemic diseases, such as diabetes and hypertension, further demonstrating its strong generalizability. Finally, we propose a contrastive-self-supervised-learning-based OCT-IR pre-training framework (COIP) for cross-modality analysis on OCT and infrared retinal (IR) images, where the OCT volumes are embedded using OCTCube. We demonstrate that COIP enables accurate alignment between OCT and IR en face images. Collectively, OCTCube, a 3D OCT foundation model, demonstrates significantly better performance against 2D models on 27 out of 29 tasks and comparable performance on the other two tasks, paving the way for AI-based retinal disease diagnosis.
Unleash the Power of Ellipsis: Accuracy-enhanced Sparse Vector Technique with Exponential Noise
Jul 29, 2024The Sparse Vector Technique (SVT) is one of the most fundamental tools in differential privacy (DP). It works as a backbone for adaptive data analysis by answering a sequence of queries on a given dataset, and gleaning useful information in a privacy-preserving manner. Unlike the typical private query releases that directly publicize the noisy query results, SVT is less informative -- it keeps the noisy query results to itself and only reveals a binary bit for each query, indicating whether the query result surpasses a predefined threshold. To provide a rigorous DP guarantee for SVT, prior works in the literature adopt a conservative privacy analysis by assuming the direct disclosure of noisy query results as in typical private query releases. This approach, however, hinders SVT from achieving higher query accuracy due to an overestimation of the privacy risks, which further leads to an excessive noise injection using the Laplacian or Gaussian noise for perturbation. Motivated by this, we provide a new privacy analysis for SVT by considering its less informative nature. Our analysis results not only broaden the range of applicable noise types for perturbation in SVT, but also identify the exponential noise as optimal among all evaluated noises (which, however, is usually deemed non-applicable in prior works). The main challenge in applying exponential noise to SVT is mitigating the sub-optimal performance due to the bias introduced by noise distributions. To address this, we develop a utility-oriented optimal threshold correction method and an appending strategy, which enhances the performance of SVT by increasing the precision and recall, respectively. The effectiveness of our proposed methods is substantiated both theoretically and empirically, demonstrating significant improvements up to $50\%$ across evaluated metrics.
On ADMM in Heterogeneous Federated Learning: Personalization, Robustness, and Fairness
Jul 23, 2024



Statistical heterogeneity is a root cause of tension among accuracy, fairness, and robustness of federated learning (FL), and is key in paving a path forward. Personalized FL (PFL) is an approach that aims to reduce the impact of statistical heterogeneity by developing personalized models for individual users, while also inherently providing benefits in terms of fairness and robustness. However, existing PFL frameworks focus on improving the performance of personalized models while neglecting the global model. Moreover, these frameworks achieve sublinear convergence rates and rely on strong assumptions. In this paper, we propose FLAME, an optimization framework by utilizing the alternating direction method of multipliers (ADMM) to train personalized and global models. We propose a model selection strategy to improve performance in situations where clients have different types of heterogeneous data. Our theoretical analysis establishes the global convergence and two kinds of convergence rates for FLAME under mild assumptions. We theoretically demonstrate that FLAME is more robust and fair than the state-of-the-art methods on a class of linear problems. Our experimental findings show that FLAME outperforms state-of-the-art methods in convergence and accuracy, and it achieves higher test accuracy under various attacks and performs more uniformly across clients.
Efficient k-means with Individual Fairness via Exponential Tilting
Jun 24, 2024In location-based resource allocation scenarios, the distances between each individual and the facility are desired to be approximately equal, thereby ensuring fairness. Individually fair clustering is often employed to achieve the principle of treating all points equally, which can be applied in these scenarios. This paper proposes a novel algorithm, tilted k-means (TKM), aiming to achieve individual fairness in clustering. We integrate the exponential tilting into the sum of squared errors (SSE) to formulate a novel objective function called tilted SSE. We demonstrate that the tilted SSE can generalize to SSE and employ the coordinate descent and first-order gradient method for optimization. We propose a novel fairness metric, the variance of the distances within each cluster, which can alleviate the Matthew Effect typically caused by existing fairness metrics. Our theoretical analysis demonstrates that the well-known k-means++ incurs a multiplicative error of O(k log k), and we establish the convergence of TKM under mild conditions. In terms of fairness, we prove that the variance generated by TKM decreases with a scaled hyperparameter. In terms of efficiency, we demonstrate the time complexity is linear with the dataset size. Our experiments demonstrate that TKM outperforms state-of-the-art methods in effectiveness, fairness, and efficiency.