 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Large Language Reasoning Models via Extreme-Ratio Chain-of-Thought Compression
Feb 09, 2026Chain-of-Thought (CoT) reasoning successfully enhances the reasoning capabilities of Large Language Models (LLMs), yet it incurs substantial computational overhead for inference. Existing CoT compression methods often suffer from a critical loss of logical fidelity at high compression ratios, resulting in significant performance degradation. To achieve high-fidelity, fast reasoning, we propose a novel EXTreme-RAtio Chain-of-Thought Compression framework, termed Extra-CoT, which aggressively reduces the token budget while preserving answer accuracy. To generate reliable, high-fidelity supervision, we first train a dedicated semantically-preserved compressor on mathematical CoT data with fine-grained annotations. An LLM is then fine-tuned on these compressed pairs via a mixed-ratio supervised fine-tuning (SFT), teaching it to follow a spectrum of compression budgets and providing a stable initialization for reinforcement learning (RL). We further propose Constrained and Hierarchical Ratio Policy Optimization (CHRPO) to explicitly incentivize question-solving ability under lower budgets by a hierarchical reward. Experiments on three mathematical reasoning benchmarks show the superiority of Extra-CoT. For example, on MATH-500 using Qwen3-1.7B, Extra-CoT achieves over 73\% token reduction with an accuracy improvement of 0.6\%, significantly outperforming state-of-the-art (SOTA) methods.
Interleaving Reasoning for Better Text-to-Image Generation
Sep 09, 2025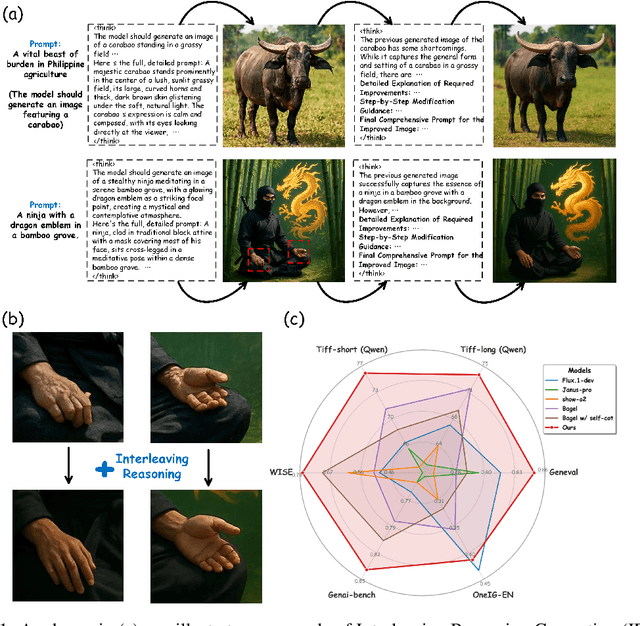
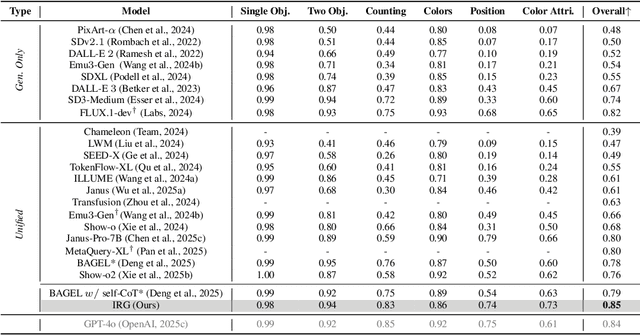

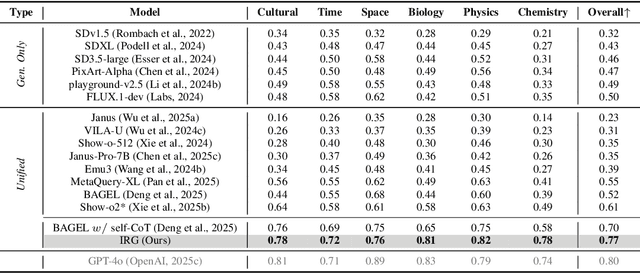
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
CompBench: Benchmarking Complex Instruction-guided Image Editing
May 18, 2025While real-world applications increasingly demand intricate scene manipulation, existing instruction-guided image editing benchmarks often oversimplify task complexity and lack comprehensive, fine-grained instructions. To bridge this gap, we introduce, a large-scale benchmark specifically designed for complex instruction-guided image editing. CompBench features challenging editing scenarios that incorporate fine-grained instruction following, spatial and contextual reasoning, thereby enabling comprehensive evaluation of image editing models' precise manipulation capabilities. To construct CompBench, We propose an MLLM-human collaborative framework with tailored task pipelines. Furthermore, we propose an instruction decoupling strategy that disentangles editing intents into four key dimensions: location, appearance, dynamics, and objects, ensuring closer alignment between instructions and complex editing requirements. Extensive evaluations reveal that CompBench exposes fundamental limitations of current image editing models and provides critical insights for the development of next-generation instruction-guided image editing systems.