 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoEval: Autonomous Evaluation of Generalist Robot Manipulation Policies in the Real World
Mar 31, 2025Scalable and reproducible policy evaluation has been a long-standing challenge in robot learning. Evaluations are critical to assess progress and build better policies, but evaluation in the real world, especially at a scale that would provide statistically reliable results, is costly in terms of human time and hard to obtain. Evaluation of increasingly generalist robot policies requires an increasingly diverse repertoire of evaluation environments, making the evaluation bottleneck even more pronounced. To make real-world evaluation of robotic policies more practical, we propose AutoEval, a system to autonomously evaluate generalist robot policies around the clock with minimal human intervention. Users interact with AutoEval by submitting evaluation jobs to the AutoEval queue, much like how software jobs are submitted with a cluster scheduling system, and AutoEval will schedule the policies for evaluation within a framework supplying automatic success detection and automatic scene resets. We show that AutoEval can nearly fully eliminate human involvement in the evaluation process, permitting around the clock evaluations, and the evaluation results correspond closely to ground truth evaluations conducted by hand. To facilitate the evaluation of generalist policies in the robotics community, we provide public access to multiple AutoEval scenes in the popular BridgeData robot setup with WidowX robot arms. In the future, we hope that AutoEval scenes can be set up across institutions to form a diverse and distributed evaluation network.
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
Mar 19, 2025



Large language model (LLM) agents need to perform multi-turn interactions in real-world tasks. However, existing multi-turn RL algorithms for optimizing LLM agents fail to perform effective credit assignment over multiple turns while leveraging the generalization capabilities of LLMs and it remains unclear how to develop such algorithms. To study this, we first introduce a new benchmark, ColBench, where an LLM agent interacts with a human collaborator over multiple turns to solve realistic tasks in backend programming and frontend design. Building on this benchmark, we propose a novel RL algorithm, SWEET-RL (RL with Step-WisE Evaluation from Training-time information), that uses a carefully designed optimization objective to train a critic model with access to additional training-time information. The critic provides step-level rewards for improving the policy model. Our experiments demonstrate that SWEET-RL achieves a 6% absolute improvement in success and win rates on ColBench compared to other state-of-the-art multi-turn RL algorithms, enabling Llama-3.1-8B to match or exceed the performance of GPT4-o in realistic collaborative content creation.
Dynamic Search for Inference-Time Alignment in Diffusion Models
Mar 03, 2025



Diffusion models have shown promising generative capabilities across diverse domains, yet aligning their outputs with desired reward functions remains a challenge, particularly in cases where reward functions are non-differentiable. Some gradient-free guidance methods have been developed, but they often struggle to achieve optimal inference-time alignment. In this work, we newly frame inference-time alignment in diffusion as a search problem and propose Dynamic Search for Diffusion (DSearch), which subsamples from denoising processes and approximates intermediate node rewards. It also dynamically adjusts beam width and tree expansion to efficiently explore high-reward generations. To refine intermediate decisions, DSearch incorporates adaptive scheduling based on noise levels and a lookahead heuristic function. We validate DSearch across multiple domains, including biological sequence design, molecular optimization, and image generation, demonstrating superior reward optimization compared to existing approaches.
Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models
Feb 26, 2025Generalist robots that can perform a range of different tasks in open-world settings must be able to not only reason about the steps needed to accomplish their goals, but also process complex instructions, prompts, and even feedback during task execution. Intricate instructions (e.g., "Could you make me a vegetarian sandwich?" or "I don't like that one") require not just the ability to physically perform the individual steps, but the ability to situate complex commands and feedback in the physical world. In this work, we describe a system that uses vision-language models in a hierarchical structure, first reasoning over complex prompts and user feedback to deduce the most appropriate next step to fulfill the task, and then performing that step with low-level actions. In contrast to direct instruction following methods that can fulfill simple commands ("pick up the cup"), our system can reason through complex prompts and incorporate situated feedback during task execution ("that's not trash"). We evaluate our system across three robotic platforms, including single-arm, dual-arm, and dual-arm mobile robots, demonstrating its ability to handle tasks such as cleaning messy tables, making sandwiches, and grocery shopping.
Reflective Planning: Vision-Language Models for Multi-Stage Long-Horizon Robotic Manipulation
Feb 23, 2025



Solving complex long-horizon robotic manipulation problems requires sophisticated high-level planning capabilities, the ability to reason about the physical world, and reactively choose appropriate motor skills. Vision-language models (VLMs) pretrained on Internet data could in principle offer a framework for tackling such problems. However, in their current form, VLMs lack both the nuanced understanding of intricate physics required for robotic manipulation and the ability to reason over long horizons to address error compounding issues. In this paper, we introduce a novel test-time computation framework that enhances VLMs' physical reasoning capabilities for multi-stage manipulation tasks. At its core, our approach iteratively improves a pretrained VLM with a "reflection" mechanism - it uses a generative model to imagine future world states, leverages these predictions to guide action selection, and critically reflects on potential suboptimalities to refine its reasoning. Experimental results demonstrate that our method significantly outperforms several state-of-the-art commercial VLMs as well as other post-training approaches such as Monte Carlo Tree Search (MCTS). Videos are available at https://reflect-vlm.github.io.
Reward-Guided Iterative Refinement in Diffusion Models at Test-Time with Applications to Protein and DNA Design
Feb 20, 2025



To fully leverage the capabilities of diffusion models, we are often interested in optimizing downstream reward functions during inference. While numerous algorithms for reward-guided generation have been recently proposed due to their significance, current approaches predominantly focus on single-shot generation, transitioning from fully noised to denoised states. We propose a novel framework for inference-time reward optimization with diffusion models inspired by evolutionary algorithms. Our approach employs an iterative refinement process consisting of two steps in each iteration: noising and reward-guided denoising. This sequential refinement allows for the gradual correction of errors introduced during reward optimization. Besides, we provide a theoretical guarantee for our framework. Finally, we demonstrate its superior empirical performance in protein and cell-type-specific regulatory DNA design. The code is available at \href{https://github.com/masa-ue/ProDifEvo-Refinement}{https://github.com/masa-ue/ProDifEvo-Refinement}.
Scaling Test-Time Compute Without Verification or RL is Suboptimal
Feb 18, 2025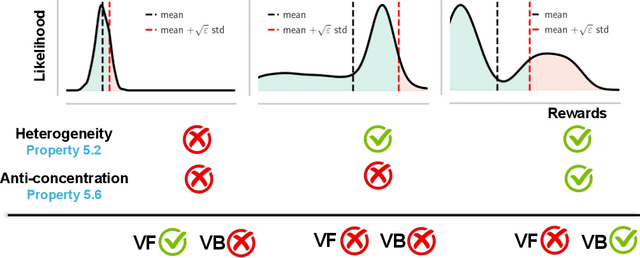
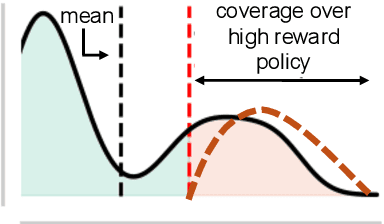
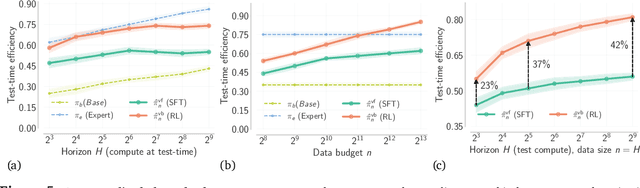
Despite substantial advances in scaling test-time compute, an ongoing debate in the community is how it should be scaled up to enable continued and efficient improvements with scaling. There are largely two approaches: first, distilling successful search or thinking traces; and second, using verification (e.g., 0/1 outcome rewards, reward models, or verifiers) to guide reinforcement learning (RL) and search algorithms. In this paper, we prove that finetuning LLMs with verifier-based (VB) methods based on RL or search is far superior to verifier-free (VF) approaches based on distilling or cloning search traces, given a fixed amount of compute/data budget. Further, we show that as we scale test-time compute (measured as the output token length) and training data, suboptimality of VF methods scales poorly compared to VB when the base pre-trained LLM presents a heterogeneous distribution over correct solution traces (e.g., different lengths, styles, etc.) and admits a non-sharp distribution over rewards on traces sampled from it. We formalize this condition using anti-concentration [Erd\H{o}s, 1945]. This implies a stronger result that VB methods scale better asymptotically, with the performance gap between VB and VF methods widening as test-time budget grows. We corroborate our theory empirically on both didactic and math reasoning problems with 3/8/32B-sized pre-trained LLMs, where we find verification is crucial for scaling test-time compute.
Temporal Representation Alignment: Successor Features Enable Emergent Compositionality in Robot Instruction Following Temporal Representation Alignment
Feb 08, 2025



Effective task representations should facilitate compositionality, such that after learning a variety of basic tasks, an agent can perform compound tasks consisting of multiple steps simply by composing the representations of the constituent steps together. While this is conceptually simple and appealing, it is not clear how to automatically learn representations that enable this sort of compositionality. We show that learning to associate the representations of current and future states with a temporal alignment loss can improve compositional generalization, even in the absence of any explicit subtask planning or reinforcement learning. We evaluate our approach across diverse robotic manipulation tasks as well as in simulation, showing substantial improvements for tasks specified with either language or goal images.
Value-Based Deep RL Scales Predictably
Feb 06, 2025Scaling data and compute is critical to the success of machine learning. However, scaling demands predictability: we want methods to not only perform well with more compute or data, but also have their performance be predictable from small-scale runs, without running the large-scale experiment. In this paper, we show that value-based off-policy RL methods are predictable despite community lore regarding their pathological behavior. First, we show that data and compute requirements to attain a given performance level lie on a Pareto frontier, controlled by the updates-to-data (UTD) ratio. By estimating this frontier, we can predict this data requirement when given more compute, and this compute requirement when given more data. Second, we determine the optimal allocation of a total resource budget across data and compute for a given performance and use it to determine hyperparameters that maximize performance for a given budget. Third, this scaling behavior is enabled by first estimating predictable relationships between hyperparameters, which is used to manage effects of overfitting and plasticity loss unique to RL. We validate our approach using three algorithms: SAC, BRO, and PQL on DeepMind Control, OpenAI gym, and IsaacGym, when extrapolating to higher levels of data, compute, budget, or performance.
Flow Q-Learning
Feb 04, 2025We present flow Q-learning (FQL), a simple and performant offline reinforcement learning (RL) method that leverages an expressive flow-matching policy to model arbitrarily complex action distributions in data. Training a flow policy with RL is a tricky problem, due to the iterative nature of the action generation process. We address this challenge by training an expressive one-step policy with RL, rather than directly guiding an iterative flow policy to maximize values. This way, we can completely avoid unstable recursive backpropagation, eliminate costly iterative action generation at test time, yet still mostly maintain expressivity. We experimentally show that FQL leads to strong performance across 73 challenging state- and pixel-based OGBench and D4RL tasks in offline RL and offline-to-online RL. Project page: https://seohong.me/projects/fql/