 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultistep Quasimetric Learning for Scalable Goal-conditioned Reinforcement Learning
Nov 14, 2025



Learning how to reach goals in an environment is a longstanding challenge in AI, yet reasoning over long horizons remains a challenge for modern methods. The key question is how to estimate the temporal distance between pairs of observations. While temporal difference methods leverage local updates to provide optimality guarantees, they often perform worse than Monte Carlo methods that perform global updates (e.g., with multi-step returns), which lack such guarantees. We show how these approaches can be integrated into a practical GCRL method that fits a quasimetric distance using a multistep Monte-Carlo return. We show our method outperforms existing GCRL methods on long-horizon simulated tasks with up to 4000 steps, even with visual observations. We also demonstrate that our method can enable stitching in the real-world robotic manipulation domain (Bridge setup). Our approach is the first end-to-end GCRL method that enables multistep stitching in this real-world manipulation domain from an unlabeled offline dataset of visual observations.
Multi-Agent Inverse Q-Learning from Demonstrations
Mar 06, 2025

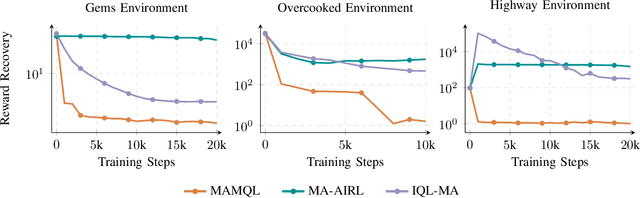
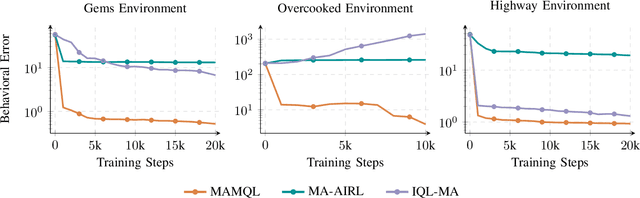
When reward functions are hand-designed, deep reinforcement learning algorithms often suffer from reward misspecification, causing them to learn suboptimal policies in terms of the intended task objectives. In the single-agent case, inverse reinforcement learning (IRL) techniques attempt to address this issue by inferring the reward function from expert demonstrations. However, in multi-agent problems, misalignment between the learned and true objectives is exacerbated due to increased environment non-stationarity and variance that scales with multiple agents. As such, in multi-agent general-sum games, multi-agent IRL algorithms have difficulty balancing cooperative and competitive objectives. To address these issues, we propose Multi-Agent Marginal Q-Learning from Demonstrations (MAMQL), a novel sample-efficient framework for multi-agent IRL. For each agent, MAMQL learns a critic marginalized over the other agents' policies, allowing for a well-motivated use of Boltzmann policies in the multi-agent context. We identify a connection between optimal marginalized critics and single-agent soft-Q IRL, allowing us to apply a direct, simple optimization criterion from the single-agent domain. Across our experiments on three different simulated domains, MAMQL significantly outperforms previous multi-agent methods in average reward, sample efficiency, and reward recovery by often more than 2-5x. We make our code available at https://sites.google.com/view/mamql .
Temporal Representation Alignment: Successor Features Enable Emergent Compositionality in Robot Instruction Following Temporal Representation Alignment
Feb 08, 2025



Effective task representations should facilitate compositionality, such that after learning a variety of basic tasks, an agent can perform compound tasks consisting of multiple steps simply by composing the representations of the constituent steps together. While this is conceptually simple and appealing, it is not clear how to automatically learn representations that enable this sort of compositionality. We show that learning to associate the representations of current and future states with a temporal alignment loss can improve compositional generalization, even in the absence of any explicit subtask planning or reinforcement learning. We evaluate our approach across diverse robotic manipulation tasks as well as in simulation, showing substantial improvements for tasks specified with either language or goal images.
Horizon Generalization in Reinforcement Learning
Jan 06, 2025



We study goal-conditioned RL through the lens of generalization, but not in the traditional sense of random augmentations and domain randomization. Rather, we aim to learn goal-directed policies that generalize with respect to the horizon: after training to reach nearby goals (which are easy to learn), these policies should succeed in reaching distant goals (which are quite challenging to learn). In the same way that invariance is closely linked with generalization is other areas of machine learning (e.g., normalization layers make a network invariant to scale, and therefore generalize to inputs of varying scales), we show that this notion of horizon generalization is closely linked with invariance to planning: a policy navigating towards a goal will select the same actions as if it were navigating to a waypoint en route to that goal. Thus, such a policy trained to reach nearby goals should succeed at reaching arbitrarily-distant goals. Our theoretical analysis proves that both horizon generalization and planning invariance are possible, under some assumptions. We present new experimental results and recall findings from prior work in support of our theoretical results. Taken together, our results open the door to studying how techniques for invariance and generalization developed in other areas of machine learning might be adapted to achieve this alluring property.
Learning to Assist Humans without Inferring Rewards
Nov 04, 2024Assistive agents should make humans' lives easier. Classically, such assistance is studied through the lens of inverse reinforcement learning, where an assistive agent (e.g., a chatbot, a robot) infers a human's intention and then selects actions to help the human reach that goal. This approach requires inferring intentions, which can be difficult in high-dimensional settings. We build upon prior work that studies assistance through the lens of empowerment: an assistive agent aims to maximize the influence of the human's actions such that they exert a greater control over the environmental outcomes and can solve tasks in fewer steps. We lift the major limitation of prior work in this area--scalability to high-dimensional settings--with contrastive successor representations. We formally prove that these representations estimate a similar notion of empowerment to that studied by prior work and provide a ready-made mechanism for optimizing it. Empirically, our proposed method outperforms prior methods on synthetic benchmarks, and scales to Overcooked, a cooperative game setting. Theoretically, our work connects ideas from information theory, neuroscience, and reinforcement learning, and charts a path for representations to play a critical role in solving assistive problems.
Policy Adaptation via Language Optimization: Decomposing Tasks for Few-Shot Imitation
Aug 29, 2024



Learned language-conditioned robot policies often struggle to effectively adapt to new real-world tasks even when pre-trained across a diverse set of instructions. We propose a novel approach for few-shot adaptation to unseen tasks that exploits the semantic understanding of task decomposition provided by vision-language models (VLMs). Our method, Policy Adaptation via Language Optimization (PALO), combines a handful of demonstrations of a task with proposed language decompositions sampled from a VLM to quickly enable rapid nonparametric adaptation, avoiding the need for a larger fine-tuning dataset. We evaluate PALO on extensive real-world experiments consisting of challenging unseen, long-horizon robot manipulation tasks. We find that PALO is able of consistently complete long-horizon, multi-tier tasks in the real world, outperforming state of the art pre-trained generalist policies, and methods that have access to the same demonstrations.
Accelerating Goal-Conditioned RL Algorithms and Research
Aug 20, 2024Self-supervision has the potential to transform reinforcement learning (RL), paralleling the breakthroughs it has enabled in other areas of machine learning. While self-supervised learning in other domains aims to find patterns in a fixed dataset, self-supervised goal-conditioned reinforcement learning (GCRL) agents discover new behaviors by learning from the goals achieved during unstructured interaction with the environment. However, these methods have failed to see similar success, both due to a lack of data from slow environments as well as a lack of stable algorithms. We take a step toward addressing both of these issues by releasing a high-performance codebase and benchmark JaxGCRL for self-supervised GCRL, enabling researchers to train agents for millions of environment steps in minutes on a single GPU. The key to this performance is a combination of GPU-accelerated environments and a stable, batched version of the contrastive reinforcement learning algorithm, based on an infoNCE objective, that effectively makes use of this increased data throughput. With this approach, we provide a foundation for future research in self-supervised GCRL, enabling researchers to quickly iterate on new ideas and evaluate them in a diverse set of challenging environments. Website + Code: https://github.com/MichalBortkiewicz/JaxGCRL
Learning Temporal Distances: Contrastive Successor Features Can Provide a Metric Structure for Decision-Making
Jun 24, 2024Temporal distances lie at the heart of many algorithms for planning, control, and reinforcement learning that involve reaching goals, allowing one to estimate the transit time between two states. However, prior attempts to define such temporal distances in stochastic settings have been stymied by an important limitation: these prior approaches do not satisfy the triangle inequality. This is not merely a definitional concern, but translates to an inability to generalize and find shortest paths. In this paper, we build on prior work in contrastive learning and quasimetrics to show how successor features learned by contrastive learning (after a change of variables) form a temporal distance that does satisfy the triangle inequality, even in stochastic settings. Importantly, this temporal distance is computationally efficient to estimate, even in high-dimensional and stochastic settings. Experiments in controlled settings and benchmark suites demonstrate that an RL algorithm based on these new temporal distances exhibits combinatorial generalization (i.e., "stitching") and can sometimes learn more quickly than prior methods, including those based on quasimetrics.
Coprocessor Actor Critic: A Model-Based Reinforcement Learning Approach For Adaptive Brain Stimulation
Jun 10, 2024



Adaptive brain stimulation can treat neurological conditions such as Parkinson's disease and post-stroke motor deficits by influencing abnormal neural activity. Because of patient heterogeneity, each patient requires a unique stimulation policy to achieve optimal neural responses. Model-free reinforcement learning (MFRL) holds promise in learning effective policies for a variety of similar control tasks, but is limited in domains like brain stimulation by a need for numerous costly environment interactions. In this work we introduce Coprocessor Actor Critic, a novel, model-based reinforcement learning (MBRL) approach for learning neural coprocessor policies for brain stimulation. Our key insight is that coprocessor policy learning is a combination of learning how to act optimally in the world and learning how to induce optimal actions in the world through stimulation of an injured brain. We show that our approach overcomes the limitations of traditional MFRL methods in terms of sample efficiency and task success and outperforms baseline MBRL approaches in a neurologically realistic model of an injured brain.
Inference via Interpolation: Contrastive Representations Provably Enable Planning and Inference
Mar 06, 2024Given time series data, how can we answer questions like "what will happen in the future?" and "how did we get here?" These sorts of probabilistic inference questions are challenging when observations are high-dimensional. In this paper, we show how these questions can have compact, closed form solutions in terms of learned representations. The key idea is to apply a variant of contrastive learning to time series data. Prior work already shows that the representations learned by contrastive learning encode a probability ratio. By extending prior work to show that the marginal distribution over representations is Gaussian, we can then prove that joint distribution of representations is also Gaussian. Taken together, these results show that representations learned via temporal contrastive learning follow a Gauss-Markov chain, a graphical model where inference (e.g., prediction, planning) over representations corresponds to inverting a low-dimensional matrix. In one special case, inferring intermediate representations will be equivalent to interpolating between the learned representations. We validate our theory using numerical simulations on tasks up to 46-dimensions.