 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ingredients of Real-World Robotic Reinforcement Learning
Apr 27, 2020
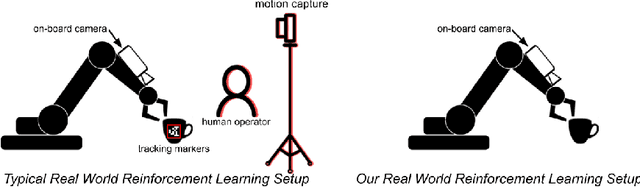
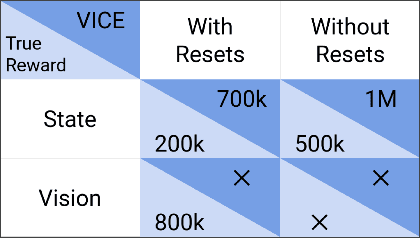
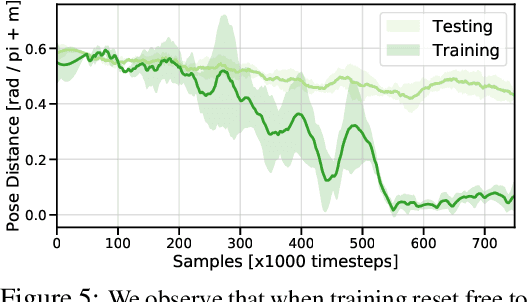
The success of reinforcement learning for real world robotics has been, in many cases limited to instrumented laboratory scenarios, often requiring arduous human effort and oversight to enable continuous learning. In this work, we discuss the elements that are needed for a robotic learning system that can continually and autonomously improve with data collected in the real world. We propose a particular instantiation of such a system, using dexterous manipulation as our case study. Subsequently, we investigate a number of challenges that come up when learning without instrumentation. In such settings, learning must be feasible without manually designed resets, using only on-board perception, and without hand-engineered reward functions. We propose simple and scalable solutions to these challenges, and then demonstrate the efficacy of our proposed system on a set of dexterous robotic manipulation tasks, providing an in-depth analysis of the challenges associated with this learning paradigm. We demonstrate that our complete system can learn without any human intervention, acquiring a variety of vision-based skills with a real-world three-fingered hand. Results and videos can be found at https://sites.google.com/view/realworld-rl/
Thinking While Moving: Deep Reinforcement Learning with Concurrent Control
Apr 25, 2020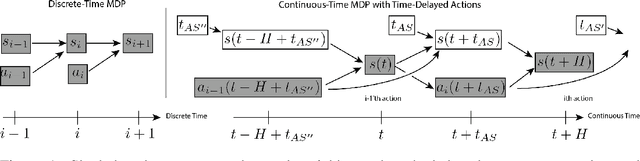
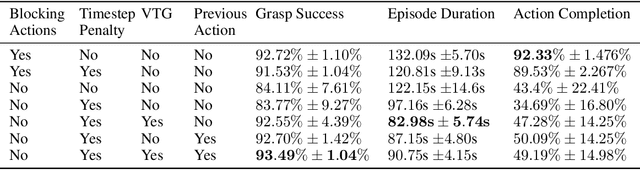
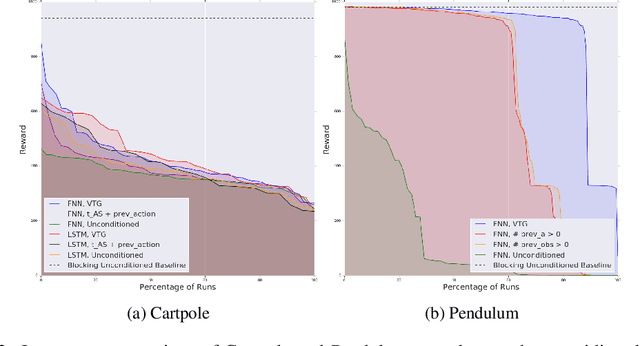

We study reinforcement learning in settings where sampling an action from the policy must be done concurrently with the time evolution of the controlled system, such as when a robot must decide on the next action while still performing the previous action. Much like a person or an animal, the robot must think and move at the same time, deciding on its next action before the previous one has completed. In order to develop an algorithmic framework for such concurrent control problems, we start with a continuous-time formulation of the Bellman equations, and then discretize them in a way that is aware of system delays. We instantiate this new class of approximate dynamic programming methods via a simple architectural extension to existing value-based deep reinforcement learning algorithms. We evaluate our methods on simulated benchmark tasks and a large-scale robotic grasping task where the robot must "think while moving".
The Variational Bandwidth Bottleneck: Stochastic Evaluation on an Information Budget
Apr 24, 2020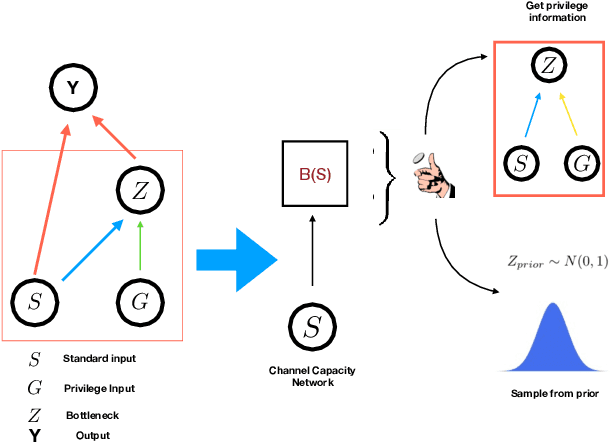

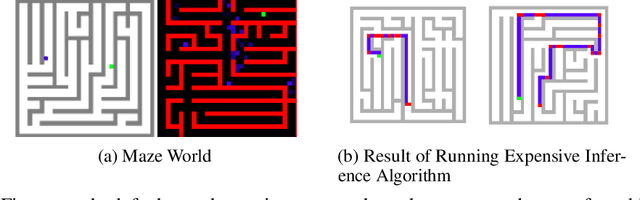
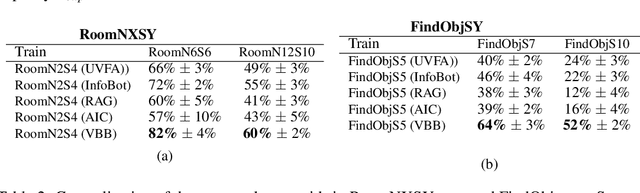
In many applications, it is desirable to extract only the relevant information from complex input data, which involves making a decision about which input features are relevant. The information bottleneck method formalizes this as an information-theoretic optimization problem by maintaining an optimal tradeoff between compression (throwing away irrelevant input information), and predicting the target. In many problem settings, including the reinforcement learning problems we consider in this work, we might prefer to compress only part of the input. This is typically the case when we have a standard conditioning input, such as a state observation, and a "privileged" input, which might correspond to the goal of a task, the output of a costly planning algorithm, or communication with another agent. In such cases, we might prefer to compress the privileged input, either to achieve better generalization (e.g., with respect to goals) or to minimize access to costly information (e.g., in the case of communication). Practical implementations of the information bottleneck based on variational inference require access to the privileged input in order to compute the bottleneck variable, so although they perform compression, this compression operation itself needs unrestricted, lossless access. In this work, we propose the variational bandwidth bottleneck, which decides for each example on the estimated value of the privileged information before seeing it, i.e., only based on the standard input, and then accordingly chooses stochastically, whether to access the privileged input or not. We formulate a tractable approximation to this framework and demonstrate in a series of reinforcement learning experiments that it can improve generalization and reduce access to computationally costly information.
Model-Based Meta-Reinforcement Learning for Flight with Suspended Payloads
Apr 23, 2020
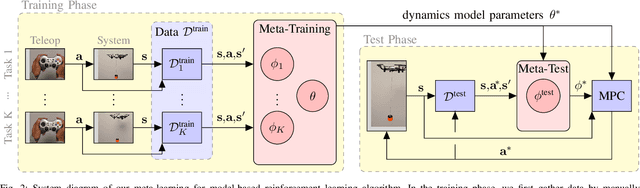
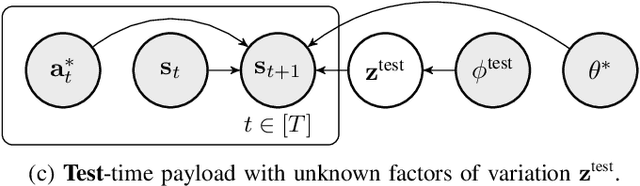

Transporting suspended payloads is challenging for autonomous aerial vehicles because the payload can cause significant and unpredictable changes to the robot's dynamics. These changes can lead to suboptimal flight performance or even catastrophic failure. Although adaptive control and learning-based methods can in principle adapt to changes in these hybrid robot-payload systems, rapid mid-flight adaptation to payloads that have a priori unknown physical properties remains an open problem. We propose a meta-learning approach that "learns how to learn" models of altered dynamics within seconds of post-connection flight data. Our experiments demonstrate that our online adaptation approach outperforms non-adaptive methods on a series of challenging suspended payload transportation tasks. Videos and other supplemental material are available on our website https://sites.google.com/view/meta-rl-for-flight
Efficient Adaptation for End-to-End Vision-Based Robotic Manipulation
Apr 21, 2020
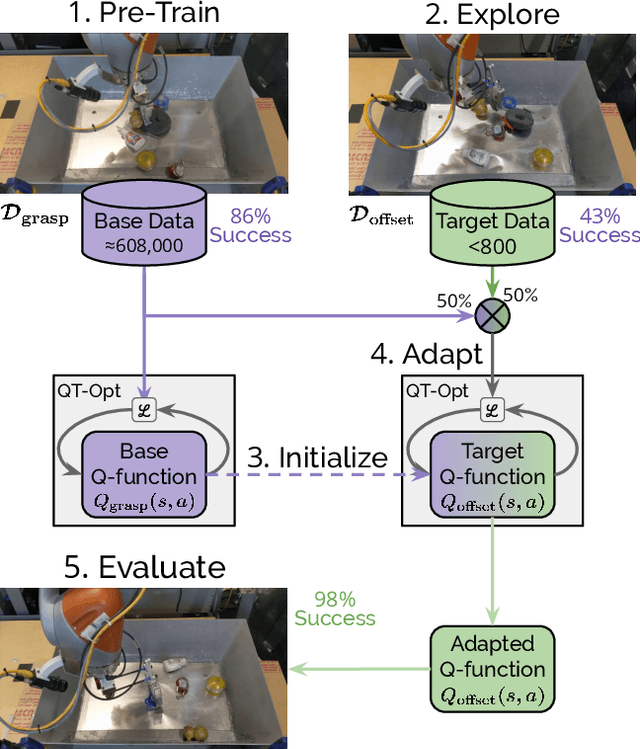
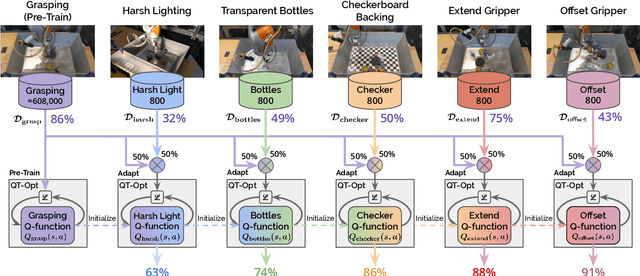
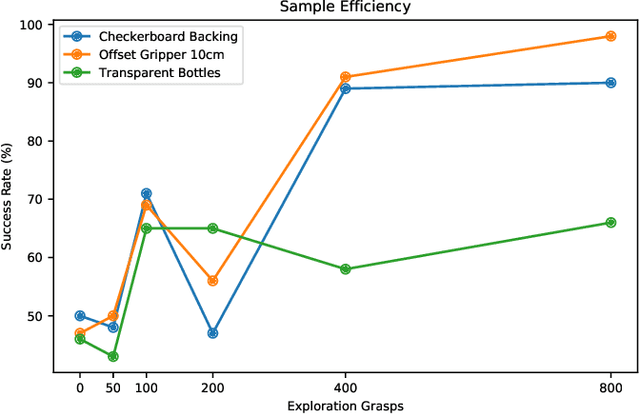
One of the great promises of robot learning systems is that they will be able to learn from their mistakes and continuously adapt to ever-changing environments. Despite this potential, most of the robot learning systems today are deployed as a fixed policy and they are not being adapted after their deployment. Can we efficiently adapt previously learned behaviors to new environments, objects and percepts in the real world? In this paper, we present a method and empirical evidence towards a robot learning framework that facilitates continuous adaption. In particular, we demonstrate how to adapt vision-based robotic manipulation policies to new variations by fine-tuning via off-policy reinforcement learning, including changes in background, object shape and appearance, lighting conditions, and robot morphology. Further, this adaptation uses less than 0.2% of the data necessary to learn the task from scratch. We find that our approach of adapting pre-trained policies leads to substantial performance gains over the course of fine-tuning, and that pre-training via RL is essential: training from scratch or adapting from supervised ImageNet features are both unsuccessful with such small amounts of data. We also find that these positive results hold in a limited continual learning setting, in which we repeatedly fine-tune a single lineage of policies using data from a succession of new tasks. Our empirical conclusions are consistently supported by experiments on simulated manipulation tasks, and by 52 unique fine-tuning experiments on a real robotic grasping system pre-trained on 580,000 grasps.
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Apr 20, 2020
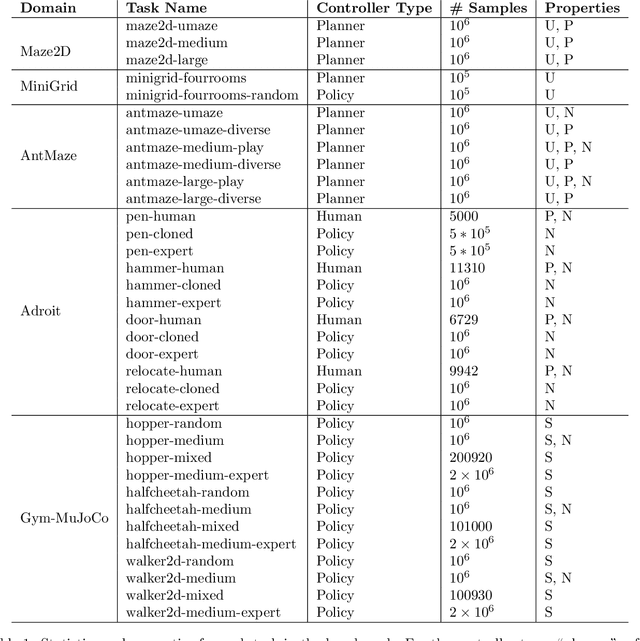
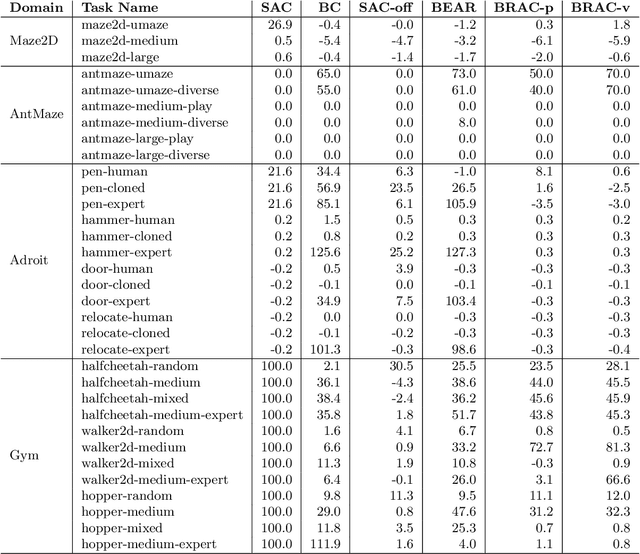
The offline reinforcement learning (RL) problem, also referred to as batch RL, refers to the setting where a policy must be learned from a dataset of previously collected data, without additional online data collection. In supervised learning, large datasets and complex deep neural networks have fueled impressive progress, but in contrast, conventional RL algorithms must collect large amounts of on-policy data and have had little success leveraging previously collected datasets. As a result, existing RL benchmarks are not well-suited for the offline setting, making progress in this area difficult to measure. To design a benchmark tailored to offline RL, we start by outlining key properties of datasets relevant to applications of offline RL. Based on these properties, we design a set of benchmark tasks and datasets that evaluate offline RL algorithms under these conditions. Examples of such properties include: datasets generated via hand-designed controllers and human demonstrators, multi-objective datasets, where an agent can perform different tasks in the same environment, and datasets consisting of a heterogeneous mix of high-quality and low-quality trajectories. By designing the benchmark tasks and datasets to reflect properties of real-world offline RL problems, our benchmark will focus research effort on methods that drive substantial improvements not just on simulated benchmarks, but ultimately on the kinds of real-world problems where offline RL will have the largest impact.
Learning Agile Robotic Locomotion Skills by Imitating Animals
Apr 02, 2020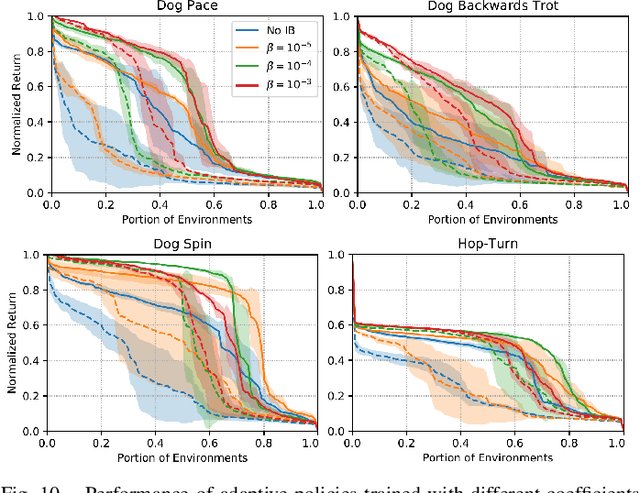
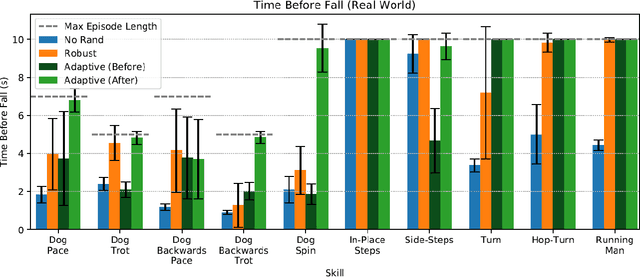
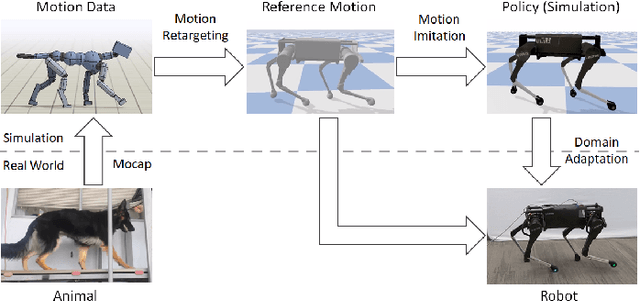
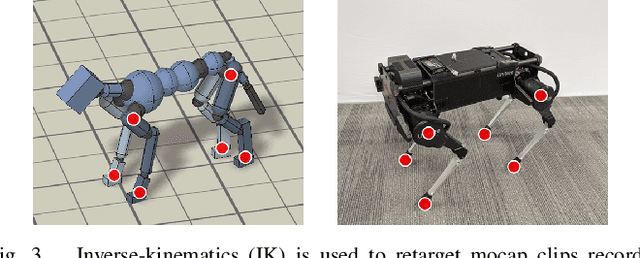
Reproducing the diverse and agile locomotion skills of animals has been a longstanding challenge in robotics. While manually-designed controllers have been able to emulate many complex behaviors, building such controllers involves a time-consuming and difficult development process, often requiring substantial expertise of the nuances of each skill. Reinforcement learning provides an appealing alternative for automating the manual effort involved in the development of controllers. However, designing learning objectives that elicit the desired behaviors from an agent can also require a great deal of skill-specific expertise. In this work, we present an imitation learning system that enables legged robots to learn agile locomotion skills by imitating real-world animals. We show that by leveraging reference motion data, a single learning-based approach is able to automatically synthesize controllers for a diverse repertoire behaviors for legged robots. By incorporating sample efficient domain adaptation techniques into the training process, our system is able to learn adaptive policies in simulation that can then be quickly adapted for real-world deployment. To demonstrate the effectiveness of our system, we train an 18-DoF quadruped robot to perform a variety of agile behaviors ranging from different locomotion gaits to dynamic hops and turns.
Unsupervised Sequence Forecasting of 100,000 Points for Unsupervised Trajectory Forecasting
Mar 29, 2020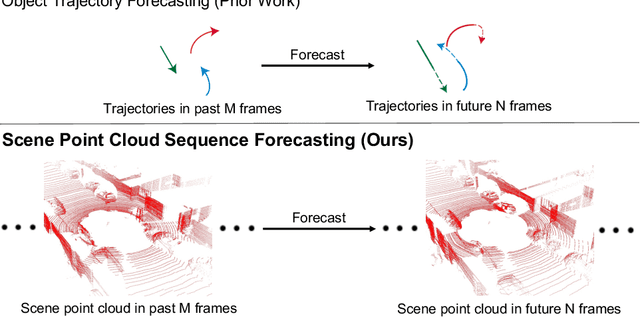
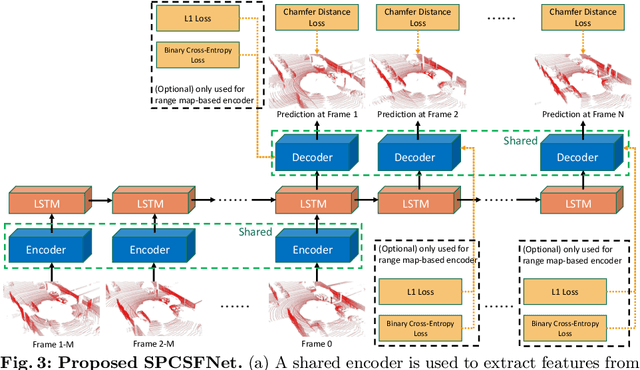
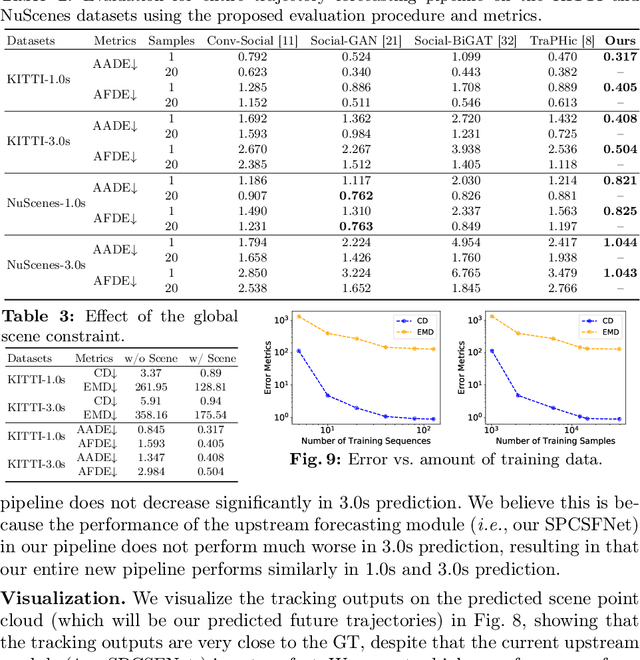
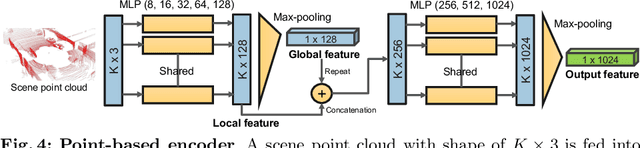
Predicting the future is a crucial first step to effective control, since systems that can predict the future can select plans that lead to desired outcomes. In this work, we study the problem of future prediction at the level of 3D scenes, represented by point clouds captured by a LiDAR sensor, i.e., directly learning to forecast the evolution of >100,000 points that comprise a complete scene. We term this Scene Point Cloud Sequence Forecasting (SPCSF). By directly predicting the densest-possible 3D representation of the future, the output contains richer information than other representations such as future object trajectories. We design a method, SPCSFNet, evaluate it on the KITTI and nuScenes datasets, and find that it demonstrates excellent performance on the SPCSF task. To show that SPCSF can benefit downstream tasks such as object trajectory forecasting, we present a new object trajectory forecasting pipeline leveraging SPCSFNet. Specifically, instead of forecasting at the object level as in conventional trajectory forecasting, we propose to forecast at the sensor level and then apply detection and tracking on the predicted sensor data. As a result, our new pipeline can remove the need of object trajectory labels and enable large-scale training with unlabeled sensor data. Surprisingly, we found our new pipeline based on SPCSFNet was able to outperform the conventional pipeline using state-of-the-art trajectory forecasting methods, all of which require future object trajectory labels. Finally, we propose a new evaluation procedure and two new metrics to measure the end-to-end performance of the trajectory forecasting pipeline. Our code will be made publicly available at https://github.com/xinshuoweng/SPCSF
DisCor: Corrective Feedback in Reinforcement Learning via Distribution Correction
Mar 16, 2020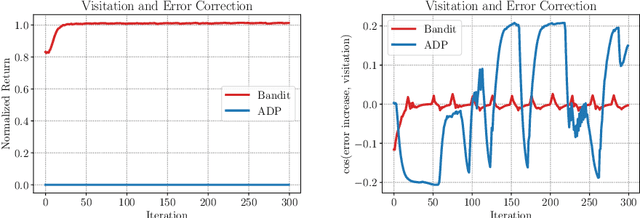
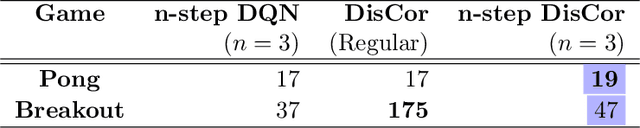
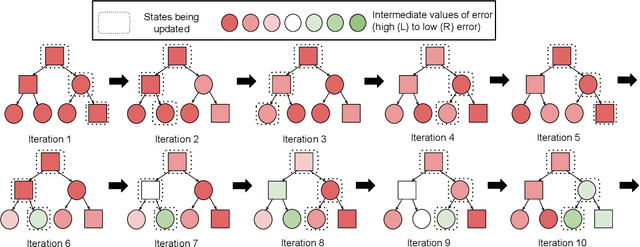
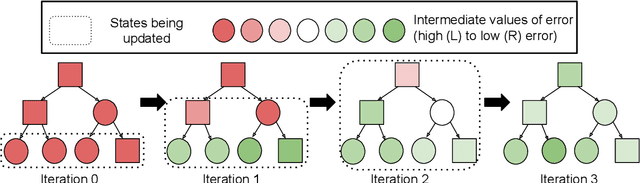
Deep reinforcement learning can learn effective policies for a wide range of tasks, but is notoriously difficult to use due to instability and sensitivity to hyperparameters. The reasons for this remain unclear. When using standard supervised methods (e.g., for bandits), on-policy data collection provides "hard negatives" that correct the model in precisely those states and actions that the policy is likely to visit. We call this phenomenon "corrective feedback." We show that bootstrapping-based Q-learning algorithms do not necessarily benefit from this corrective feedback, and training on the experience collected by the algorithm is not sufficient to correct errors in the Q-function. In fact, Q-learning and related methods can exhibit pathological interactions between the distribution of experience collected by the agent and the policy induced by training on that experience, leading to potential instability, sub-optimal convergence, and poor results when learning from noisy, sparse or delayed rewards. We demonstrate the existence of this problem, both theoretically and empirically. We then show that a specific correction to the data distribution can mitigate this issue. Based on these observations, we propose a new algorithm, DisCor, which computes an approximation to this optimal distribution and uses it to re-weight the transitions used for training, resulting in substantial improvements in a range of challenging RL settings, such as multi-task learning and learning from noisy reward signals. Blog post presenting a summary of this work is available at: https://bair.berkeley.edu/blog/2020/03/16/discor/.
OmniTact: A Multi-Directional High Resolution Touch Sensor
Mar 16, 2020



Incorporating touch as a sensing modality for robots can enable finer and more robust manipulation skills. Existing tactile sensors are either flat, have small sensitive fields or only provide low-resolution signals. In this paper, we introduce OmniTact, a multi-directional high-resolution tactile sensor. OmniTact is designed to be used as a fingertip for robotic manipulation with robotic hands, and uses multiple micro-cameras to detect multi-directional deformations of a gel-based skin. This provides a rich signal from which a variety of different contact state variables can be inferred using modern image processing and computer vision methods. We evaluate the capabilities of OmniTact on a challenging robotic control task that requires inserting an electrical connector into an outlet, as well as a state estimation problem that is representative of those typically encountered in dexterous robotic manipulation, where the goal is to infer the angle of contact of a curved finger pressing against an object. Both tasks are performed using only touch sensing and deep convolutional neural networks to process images from the sensor's cameras. We compare with a state-of-the-art tactile sensor that is only sensitive on one side, as well as a state-of-the-art multi-directional tactile sensor, and find that OmniTact's combination of high-resolution and multi-directional sensing is crucial for reliably inserting the electrical connector and allows for higher accuracy in the state estimation task. Videos and supplementary material can be found at https://sites.google.com/berkeley.edu/omnitact