 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Hierarchy-Based Meta-Reinforcement Learning
Oct 18, 2021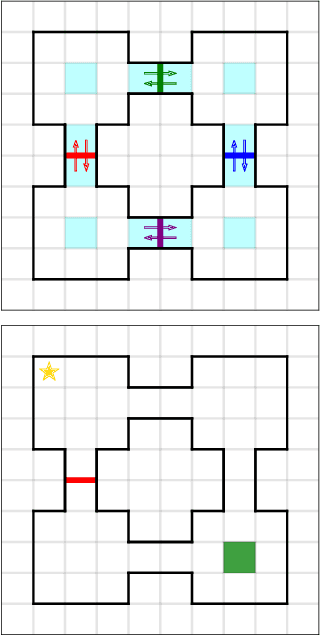



Hierarchical reinforcement learning (HRL) has seen widespread interest as an approach to tractable learning of complex modular behaviors. However, existing work either assume access to expert-constructed hierarchies, or use hierarchy-learning heuristics with no provable guarantees. To address this gap, we analyze HRL in the meta-RL setting, where a learner learns latent hierarchical structure during meta-training for use in a downstream task. We consider a tabular setting where natural hierarchical structure is embedded in the transition dynamics. Analogous to supervised meta-learning theory, we provide "diversity conditions" which, together with a tractable optimism-based algorithm, guarantee sample-efficient recovery of this natural hierarchy. Furthermore, we provide regret bounds on a learner using the recovered hierarchy to solve a meta-test task. Our bounds incorporate common notions in HRL literature such as temporal and state/action abstractions, suggesting that our setting and analysis capture important features of HRL in practice.
How Fine-Tuning Allows for Effective Meta-Learning
May 05, 2021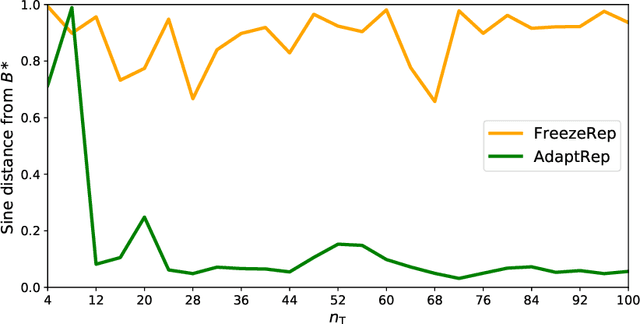
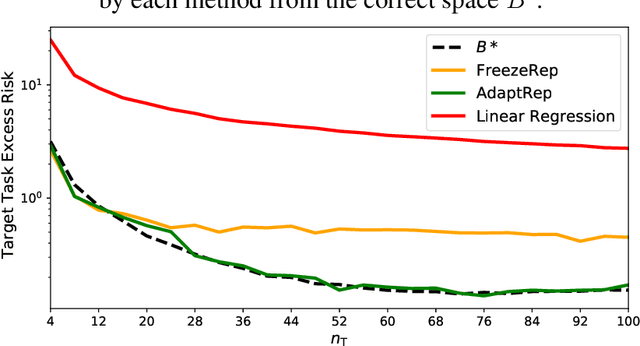
Representation learning has been widely studied in the context of meta-learning, enabling rapid learning of new tasks through shared representations. Recent works such as MAML have explored using fine-tuning-based metrics, which measure the ease by which fine-tuning can achieve good performance, as proxies for obtaining representations. We present a theoretical framework for analyzing representations derived from a MAML-like algorithm, assuming the available tasks use approximately the same underlying representation. We then provide risk bounds on the best predictor found by fine-tuning via gradient descent, demonstrating that the algorithm can provably leverage the shared structure. The upper bound applies to general function classes, which we demonstrate by instantiating the guarantees of our framework in the logistic regression and neural network settings. In contrast, we establish the existence of settings where any algorithm, using a representation trained with no consideration for task-specific fine-tuning, performs as well as a learner with no access to source tasks in the worst case. This separation result underscores the benefit of fine-tuning-based methods, such as MAML, over methods with "frozen representation" objectives in few-shot learning.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
Feb 26, 2021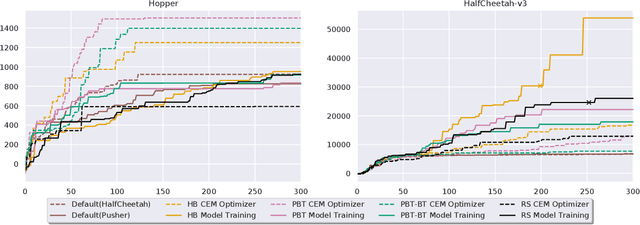
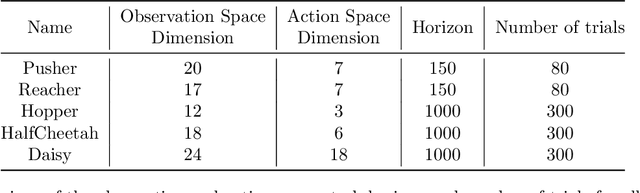
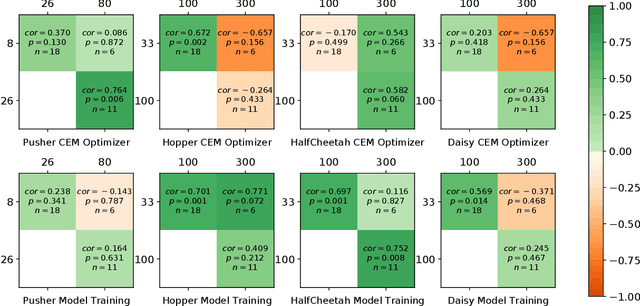
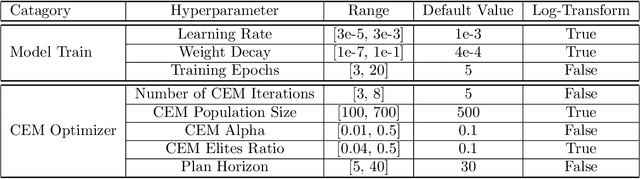
Model-based Reinforcement Learning (MBRL) is a promising framework for learning control in a data-efficient manner. MBRL algorithms can be fairly complex due to the separate dynamics modeling and the subsequent planning algorithm, and as a result, they often possess tens of hyperparameters and architectural choices. For this reason, MBRL typically requires significant human expertise before it can be applied to new problems and domains. To alleviate this problem, we propose to use automatic hyperparameter optimization (HPO). We demonstrate that this problem can be tackled effectively with automated HPO, which we demonstrate to yield significantly improved performance compared to human experts. In addition, we show that tuning of several MBRL hyperparameters dynamically, i.e. during the training itself, further improves the performance compared to using static hyperparameters which are kept fixed for the whole training. Finally, our experiments provide valuable insights into the effects of several hyperparameters, such as plan horizon or learning rate and their influence on the stability of training and resulting rewards.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Nov 02, 2018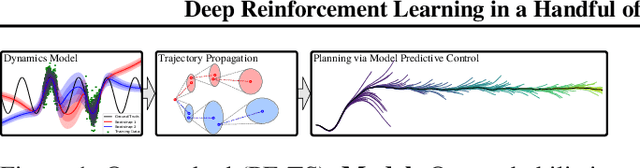
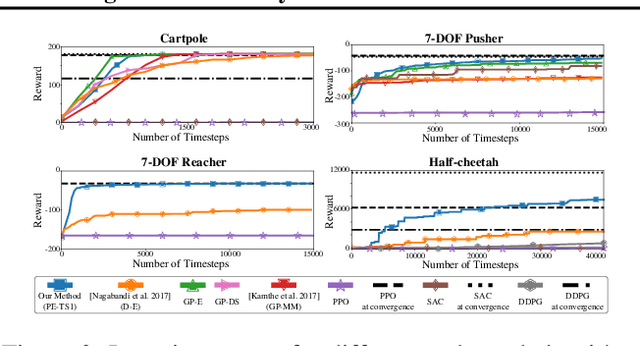
Model-based reinforcement learning (RL) algorithms can attain excellent sample efficiency, but often lag behind the best model-free algorithms in terms of asymptotic performance. This is especially true with high-capacity parametric function approximators, such as deep networks. In this paper, we study how to bridge this gap, by employing uncertainty-aware dynamics models. We propose a new algorithm called probabilistic ensembles with trajectory sampling (PETS) that combines uncertainty-aware deep network dynamics models with sampling-based uncertainty propagation. Our comparison to state-of-the-art model-based and model-free deep RL algorithms shows that our approach matches the asymptotic performance of model-free algorithms on several challenging benchmark tasks, while requiring significantly fewer samples (e.g., 8 and 125 times fewer samples than Soft Actor Critic and Proximal Policy Optimization respectively on the half-cheetah task).
MBMF: Model-Based Priors for Model-Free Reinforcement Learning
Oct 17, 2017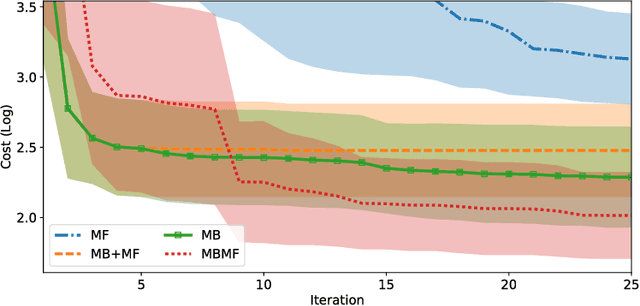
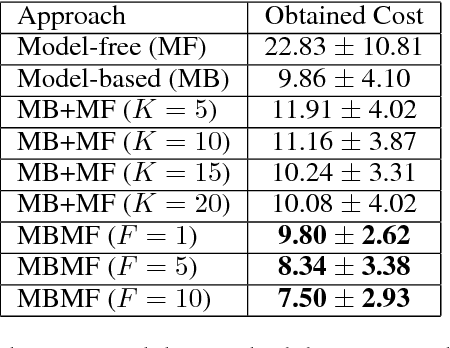
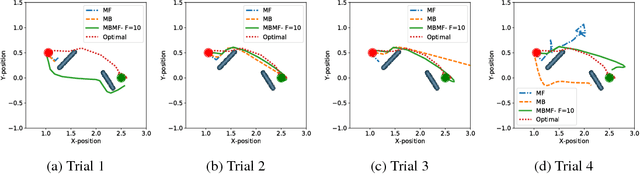
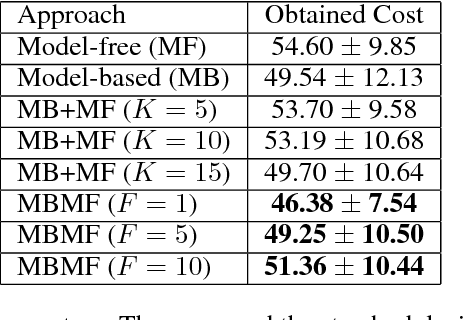
Reinforcement Learning is divided in two main paradigms: model-free and model-based. Each of these two paradigms has strengths and limitations, and has been successfully applied to real world domains that are appropriate to its corresponding strengths. In this paper, we present a new approach aimed at bridging the gap between these two paradigms. We aim to take the best of the two paradigms and combine them in an approach that is at the same time data-efficient and cost-savvy. We do so by learning a probabilistic dynamics model and leveraging it as a prior for the intertwined model-free optimization. As a result, our approach can exploit the generality and structure of the dynamics model, but is also capable of ignoring its inevitable inaccuracies, by directly incorporating the evidence provided by the direct observation of the cost. Preliminary results demonstrate that our approach outperforms purely model-based and model-free approaches, as well as the approach of simply switching from a model-based to a model-free setting.