 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeaLLMs -- Large Language Models for Southeast Asia
Dec 01, 2023



Despite the remarkable achievements of large language models (LLMs) in various tasks, there remains a linguistic bias that favors high-resource languages, such as English, often at the expense of low-resource and regional languages. To address this imbalance, we introduce SeaLLMs, an innovative series of language models that specifically focuses on Southeast Asian (SEA) languages. SeaLLMs are built upon the Llama-2 model and further advanced through continued pre-training with an extended vocabulary, specialized instruction and alignment tuning to better capture the intricacies of regional languages. This allows them to respect and reflect local cultural norms, customs, stylistic preferences, and legal considerations. Our comprehensive evaluation demonstrates that SeaLLM-13b models exhibit superior performance across a wide spectrum of linguistic tasks and assistant-style instruction-following capabilities relative to comparable open-source models. Moreover, they outperform ChatGPT-3.5 in non-Latin languages, such as Thai, Khmer, Lao, and Burmese, by large margins while remaining lightweight and cost-effective to operate.
Neuro-Symbolic Integration Brings Causal and Reliable Reasoning Proofs
Nov 16, 2023



Though prompting LLMs with various reasoning structures produces reasoning proofs along with answers, these proofs are not ensured to be causal and reliable due to the inherent defects of LLMs. Tracking such deficiencies, we present a neuro-symbolic integration method, in which a neural LLM is used to represent the knowledge of the problem while an LLM-free symbolic solver is adopted to do deliberative reasoning using the knowledge. Specifically, our customized meta-interpreters allow the production of reasoning proofs and support flexible search strategies. These reasoning proofs are ensured to be causal and reliable because of the deterministic executing nature of the symbolic solvers. Empirically, on ProofWriter, our method surpasses the CoT baseline by nearly double in accuracy and more than triple in proof similarity. On GSM8K, our method also shows accuracy improvements and nearly doubled proof similarity. Our code is released at https://github.com/DAMO-NLP-SG/CaRing
Once Upon a $\textit{Time}$ in $\textit{Graph}$: Relative-Time Pretraining for Complex Temporal Reasoning
Oct 23, 2023Our physical world is constantly evolving over time, rendering challenges for pre-trained language models to understand and reason over the temporal contexts of texts. Existing work focuses on strengthening the direct association between a piece of text and its time-stamp. However, the knowledge-time association is usually insufficient for the downstream tasks that require reasoning over temporal dependencies between knowledge. In this work, we make use of the underlying nature of time, all temporally-scoped sentences are strung together through a one-dimensional time axis, and suggest creating a graph structure based on the relative placements of events along the time axis. Inspired by the graph view, we propose RemeMo ($\underline{Re}$lative Ti$\underline{me}$ $\underline{Mo}$deling), which explicitly connects all temporally-scoped facts by modeling the time relations between any two sentences. Experimental results show that RemeMo outperforms the baseline T5 on multiple temporal question answering datasets under various settings. Further analysis suggests that RemeMo is especially good at modeling long-range complex temporal dependencies. We release our code and pre-trained checkpoints at $\href{https://github.com/DAMO-NLP-SG/RemeMo}{\text{this url}}$.
Domain generalization across tumor types, laboratories, and species -- insights from the 2022 edition of the Mitosis Domain Generalization Challenge
Sep 27, 2023
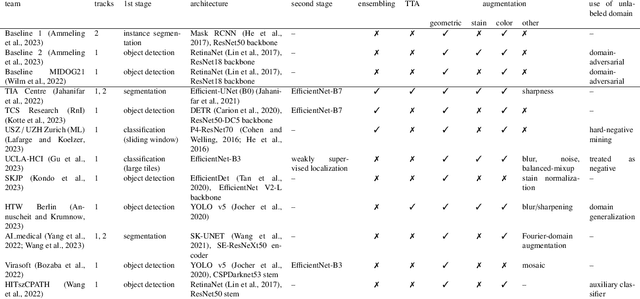
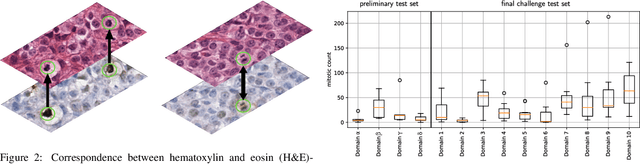

Recognition of mitotic figures in histologic tumor specimens is highly relevant to patient outcome assessment. This task is challenging for algorithms and human experts alike, with deterioration of algorithmic performance under shifts in image representations. Considerable covariate shifts occur when assessment is performed on different tumor types, images are acquired using different digitization devices, or specimens are produced in different laboratories. This observation motivated the inception of the 2022 challenge on MItosis Domain Generalization (MIDOG 2022). The challenge provided annotated histologic tumor images from six different domains and evaluated the algorithmic approaches for mitotic figure detection provided by nine challenge participants on ten independent domains. Ground truth for mitotic figure detection was established in two ways: a three-expert consensus and an independent, immunohistochemistry-assisted set of labels. This work represents an overview of the challenge tasks, the algorithmic strategies employed by the participants, and potential factors contributing to their success. With an $F_1$ score of 0.764 for the top-performing team, we summarize that domain generalization across various tumor domains is possible with today's deep learning-based recognition pipelines. When assessed against the immunohistochemistry-assisted reference standard, all methods resulted in reduced recall scores, but with only minor changes in the order of participants in the ranking.
ADNet: Lane Shape Prediction via Anchor Decomposition
Aug 21, 2023



In this paper, we revisit the limitations of anchor-based lane detection methods, which have predominantly focused on fixed anchors that stem from the edges of the image, disregarding their versatility and quality. To overcome the inflexibility of anchors, we decompose them into learning the heat map of starting points and their associated directions. This decomposition removes the limitations on the starting point of anchors, making our algorithm adaptable to different lane types in various datasets. To enhance the quality of anchors, we introduce the Large Kernel Attention (LKA) for Feature Pyramid Network (FPN). This significantly increases the receptive field, which is crucial in capturing the sufficient context as lane lines typically run throughout the entire image. We have named our proposed system the Anchor Decomposition Network (ADNet). Additionally, we propose the General Lane IoU (GLIoU) loss, which significantly improves the performance of ADNet in complex scenarios. Experimental results on three widely used lane detection benchmarks, VIL-100, CULane, and TuSimple, demonstrate that our approach outperforms the state-of-the-art methods on VIL-100 and exhibits competitive accuracy on CULane and TuSimple. Code and models will be released on https://github.com/ Sephirex-X/ADNet.
SNR-based beaconless multi-scan link acquisition model with vibration for LEO-to-ground laser communication
Aug 06, 2023We propose a link acquisition time model deeply involving the process from the transmitted power to received signal-to-noise ratio (SNR) for LEO-to-ground laser communication for the first time. Compared with the conventional acquisition models founded on geometry analysis with divergence angle threshold, utilizing SNR as the decision criterion is more appropriate for practical engineering requirements. Specially, under the combined effects of platform vibration and turbulence, we decouple the parameters of beam divergence angle, spiral pitch, and coverage factor at a fixed transmitted power for a given average received SNR threshold. Then the single-scan acquisition probability is obtained by integrating the field of uncertainty (FOU), probability distribution of coverage factor, and receiver field angle. Consequently, the closed-form analytical expression of acquisition time expectation adopting multi-scan, which ensures acquisition success, with essential reset time between single-scan is derived. The optimizations concerning the beam divergence angle, spiral pitch, and FOU are presented. Moreover, the influence of platform vibration is investigated. All the analytical derivations are confirmed by Monte Carlo simulations. Notably, we provide a theoretical method for designing the minimum divergence angle modulated by the laser, which not only improves the acquisition performance within a certain vibration range, but also achieves a good trade-off with the system complexity.
Enhancing Grammatical Error Correction Systems with Explanations
May 25, 2023Grammatical error correction systems improve written communication by detecting and correcting language mistakes. To help language learners better understand why the GEC system makes a certain correction, the causes of errors (evidence words) and the corresponding error types are two key factors. To enhance GEC systems with explanations, we introduce EXPECT, a large dataset annotated with evidence words and grammatical error types. We propose several baselines and anlysis to understand this task. Furthermore, human evaluation verifies our explainable GEC system's explanations can assist second-language learners in determining whether to accept a correction suggestion and in understanding the associated grammar rule.
MedGPTEval: A Dataset and Benchmark to Evaluate Responses of Large Language Models in Medicine
May 12, 2023



METHODS: First, a set of evaluation criteria is designed based on a comprehensive literature review. Second, existing candidate criteria are optimized for using a Delphi method by five experts in medicine and engineering. Third, three clinical experts design a set of medical datasets to interact with LLMs. Finally, benchmarking experiments are conducted on the datasets. The responses generated by chatbots based on LLMs are recorded for blind evaluations by five licensed medical experts. RESULTS: The obtained evaluation criteria cover medical professional capabilities, social comprehensive capabilities, contextual capabilities, and computational robustness, with sixteen detailed indicators. The medical datasets include twenty-seven medical dialogues and seven case reports in Chinese. Three chatbots are evaluated, ChatGPT by OpenAI, ERNIE Bot by Baidu Inc., and Doctor PuJiang (Dr. PJ) by Shanghai Artificial Intelligence Laboratory. Experimental results show that Dr. PJ outperforms ChatGPT and ERNIE Bot in both multiple-turn medical dialogue and case report scenarios.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
CoNIC Challenge: Pushing the Frontiers of Nuclear Detection, Segmentation, Classification and Counting
Mar 14, 2023



Nuclear detection, segmentation and morphometric profiling are essential in helping us further understand the relationship between histology and patient outcome. To drive innovation in this area, we setup a community-wide challenge using the largest available dataset of its kind to assess nuclear segmentation and cellular composition. Our challenge, named CoNIC, stimulated the development of reproducible algorithms for cellular recognition with real-time result inspection on public leaderboards. We conducted an extensive post-challenge analysis based on the top-performing models using 1,658 whole-slide images of colon tissue. With around 700 million detected nuclei per model, associated features were used for dysplasia grading and survival analysis, where we demonstrated that the challenge's improvement over the previous state-of-the-art led to significant boosts in downstream performance. Our findings also suggest that eosinophils and neutrophils play an important role in the tumour microevironment. We release challenge models and WSI-level results to foster the development of further methods for biomarker discovery.