 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication-driven Validation of Posteriors in Inverse Problems
Sep 18, 2023



Current deep learning-based solutions for image analysis tasks are commonly incapable of handling problems to which multiple different plausible solutions exist. In response, posterior-based methods such as conditional Diffusion Models and Invertible Neural Networks have emerged; however, their translation is hampered by a lack of research on adequate validation. In other words, the way progress is measured often does not reflect the needs of the driving practical application. Closing this gap in the literature, we present the first systematic framework for the application-driven validation of posterior-based methods in inverse problems. As a methodological novelty, it adopts key principles from the field of object detection validation, which has a long history of addressing the question of how to locate and match multiple object instances in an image. Treating modes as instances enables us to perform mode-centric validation, using well-interpretable metrics from the application perspective. We demonstrate the value of our framework through instantiations for a synthetic toy example and two medical vision use cases: pose estimation in surgery and imaging-based quantification of functional tissue parameters for diagnostics. Our framework offers key advantages over common approaches to posterior validation in all three examples and could thus revolutionize performance assessment in inverse problems.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Self-distillation for surgical action recognition
Mar 22, 2023



Surgical scene understanding is a key prerequisite for contextaware decision support in the operating room. While deep learning-based approaches have already reached or even surpassed human performance in various fields, the task of surgical action recognition remains a major challenge. With this contribution, we are the first to investigate the concept of self-distillation as a means of addressing class imbalance and potential label ambiguity in surgical video analysis. Our proposed method is a heterogeneous ensemble of three models that use Swin Transfomers as backbone and the concepts of self-distillation and multi-task learning as core design choices. According to ablation studies performed with the CholecT45 challenge data via cross-validation, the biggest performance boost is achieved by the usage of soft labels obtained by self-distillation. External validation of our method on an independent test set was achieved by providing a Docker container of our inference model to the challenge organizers. According to their analysis, our method outperforms all other solutions submitted to the latest challenge in the field. Our approach thus shows the potential of self-distillation for becoming an important tool in medical image analysis applications.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Sources of performance variability in deep learning-based polyp detection
Nov 17, 2022Validation metrics are a key prerequisite for the reliable tracking of scientific progress and for deciding on the potential clinical translation of methods. While recent initiatives aim to develop comprehensive theoretical frameworks for understanding metric-related pitfalls in image analysis problems, there is a lack of experimental evidence on the concrete effects of common and rare pitfalls on specific applications. We address this gap in the literature in the context of colon cancer screening. Our contribution is twofold. Firstly, we present the winning solution of the Endoscopy computer vision challenge (EndoCV) on colon cancer detection, conducted in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2022. Secondly, we demonstrate the sensitivity of commonly used metrics to a range of hyperparameters as well as the consequences of poor metric choices. Based on comprehensive validation studies performed with patient data from six clinical centers, we found all commonly applied object detection metrics to be subject to high inter-center variability. Furthermore, our results clearly demonstrate that the adaptation of standard hyperparameters used in the computer vision community does not generally lead to the clinically most plausible results. Finally, we present localization criteria that correspond well to clinical relevance. Our work could be a first step towards reconsidering common validation strategies in automatic colon cancer screening applications.
Surgical Data Science -- from Concepts to Clinical Translation
Oct 30, 2020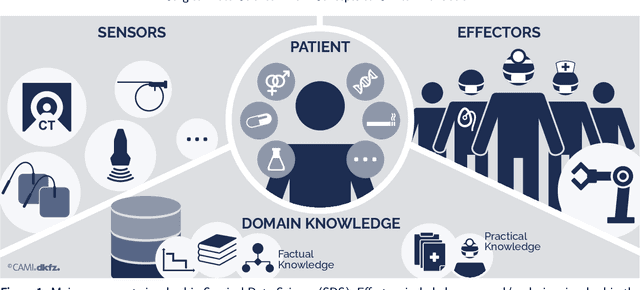
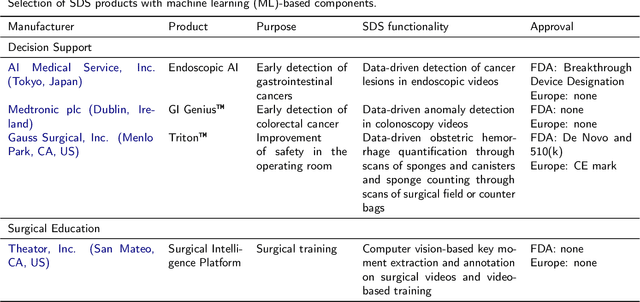
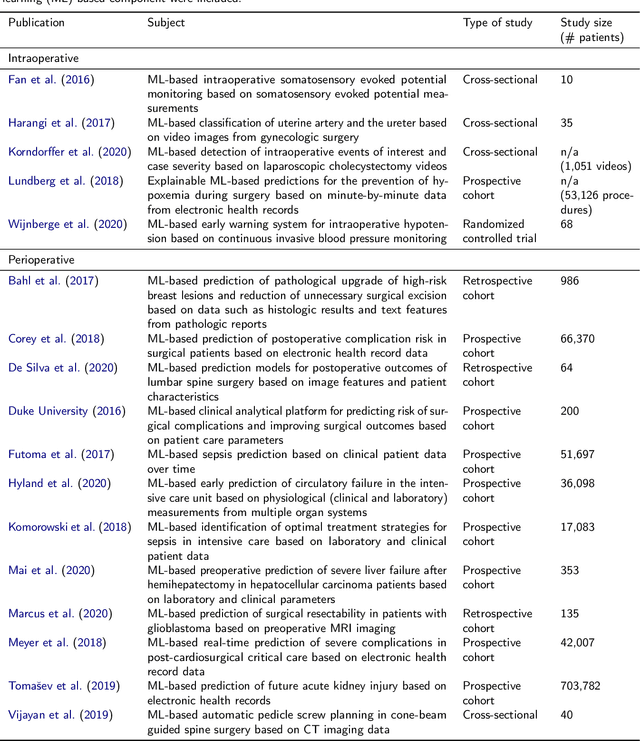
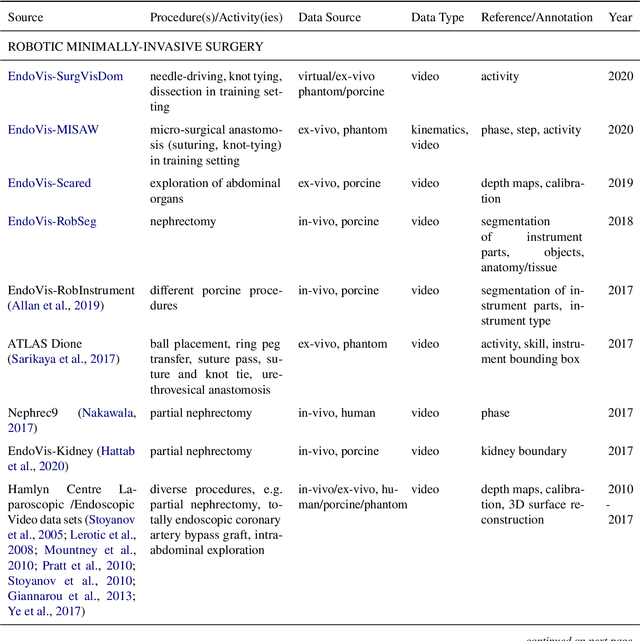
Recent developments in data science in general and machine learning in particular have transformed the way experts envision the future of surgery. Surgical data science is a new research field that aims to improve the quality of interventional healthcare through the capture, organization, analysis and modeling of data. While an increasing number of data-driven approaches and clinical applications have been studied in the fields of radiological and clinical data science, translational success stories are still lacking in surgery. In this publication, we shed light on the underlying reasons and provide a roadmap for future advances in the field. Based on an international workshop involving leading researchers in the field of surgical data science, we review current practice, key achievements and initiatives as well as available standards and tools for a number of topics relevant to the field, namely (1) technical infrastructure for data acquisition, storage and access in the presence of regulatory constraints, (2) data annotation and sharing and (3) data analytics. Drawing from this extensive review, we present current challenges for technology development and (4) describe a roadmap for faster clinical translation and exploitation of the full potential of surgical data science.