 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTartanAviation: Image, Speech, and ADS-B Trajectory Datasets for Terminal Airspace Operations
Mar 05, 2024



We introduce TartanAviation, an open-source multi-modal dataset focused on terminal-area airspace operations. TartanAviation provides a holistic view of the airport environment by concurrently collecting image, speech, and ADS-B trajectory data using setups installed inside airport boundaries. The datasets were collected at both towered and non-towered airfields across multiple months to capture diversity in aircraft operations, seasons, aircraft types, and weather conditions. In total, TartanAviation provides 3.1M images, 3374 hours of Air Traffic Control speech data, and 661 days of ADS-B trajectory data. The data was filtered, processed, and validated to create a curated dataset. In addition to the dataset, we also open-source the code-base used to collect and pre-process the dataset, further enhancing accessibility and usability. We believe this dataset has many potential use cases and would be particularly vital in allowing AI and machine learning technologies to be integrated into air traffic control systems and advance the adoption of autonomous aircraft in the airspace.
A Unified MPC Strategy for a Tilt-rotor VTOL UAV Towards Seamless Mode Transitioning
Feb 12, 2024



Capabilities of long-range flight and vertical take-off and landing (VTOL) are essential for Urban Air Mobility (UAM). Tiltrotor VTOLs have the advantage of balancing control simplicity and system complexity due to their redundant control authority. Prior work on controlling these aircraft either requires separate controllers and switching modes for different vehicle configurations or performs the control allocation on separate actuator sets, which cannot fully use the potential of the redundancy of tiltrotor. This paper introduces a unified MPC-based control strategy for a customized tiltrotor VTOL Unmanned Aerial Vehicle (UAV), which does not require mode-switching and can perform the control allocation in a consistent way. The incorporation of four independently controllable rotors in VTOL design offers an extra level of redundancy, allowing the VTOL to accommodate actuator failures. The result shows that our approach outperforms PID controllers while maintaining unified control. It allows the VTOL to perform smooth acceleration/deceleration, and precise coordinated turns. In addition, the independently controlled tilts enable the vehicle to handle actuator failures, ensuring that the aircraft remains operational even in the event of a servo or motor malfunction.
* In proceedings of the 2024 AIAA SciTech Forum, Session: Guidance, Navigation, and Control GNC-49
TartanDrive 2.0: More Modalities and Better Infrastructure to Further Self-Supervised Learning Research in Off-Road Driving Tasks
Feb 02, 2024



We present TartanDrive 2.0, a large-scale off-road driving dataset for self-supervised learning tasks. In 2021 we released TartanDrive 1.0, which is one of the largest datasets for off-road terrain. As a follow-up to our original dataset, we collected seven hours of data at speeds of up to 15m/s with the addition of three new LiDAR sensors alongside the original camera, inertial, GPS, and proprioceptive sensors. We also release the tools we use for collecting, processing, and querying the data, including our metadata system designed to further the utility of our data. Custom infrastructure allows end users to reconfigure the data to cater to their own platforms. These tools and infrastructure alongside the dataset are useful for a variety of tasks in the field of off-road autonomy and, by releasing them, we encourage collaborative data aggregation. These resources lower the barrier to entry to utilizing large-scale datasets, thereby helping facilitate the advancement of robotics in areas such as self-supervised learning, multi-modal perception, inverse reinforcement learning, and representation learning. The dataset is available at https://github.com/castacks/tartan drive 2.0.
Aerial Field Robotics
Jan 19, 2024Aerial field robotics research represents the domain of study that aims to equip unmanned aerial vehicles - and as it pertains to this chapter, specifically Micro Aerial Vehicles (MAVs)- with the ability to operate in real-life environments that present challenges to safe navigation. We present the key elements of autonomy for MAVs that are resilient to collisions and sensing degradation, while operating under constrained computational resources. We overview aspects of the state of the art, outline bottlenecks to resilient navigation autonomy, and overview the field-readiness of MAVs. We conclude with notable contributions and discuss considerations for future research that are essential for resilience in aerial robotics.
Toward General-Purpose Robots via Foundation Models: A Survey and Meta-Analysis
Dec 15, 2023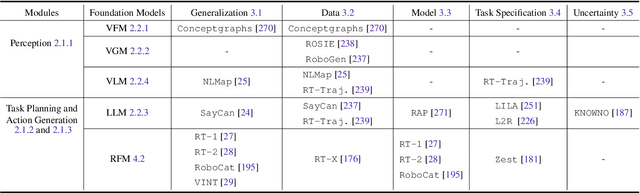
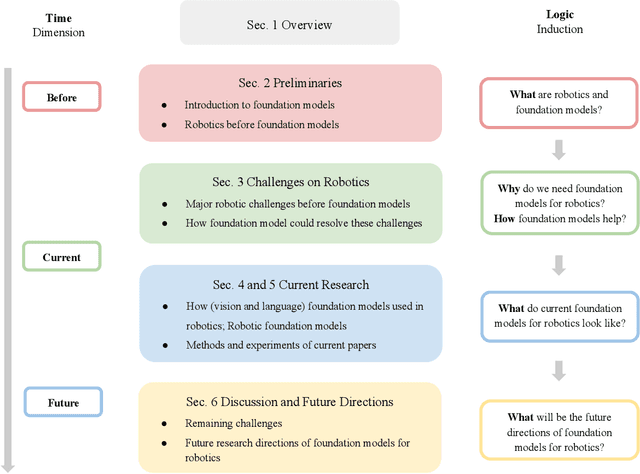
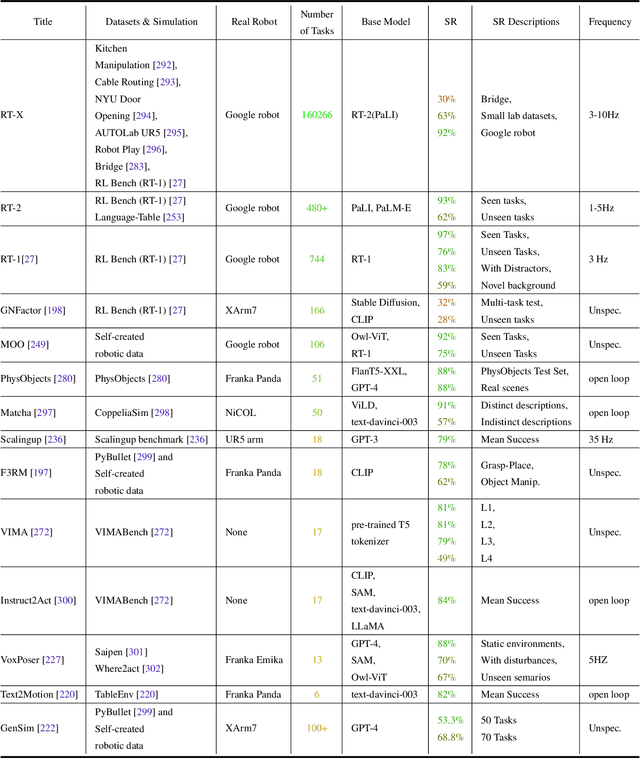
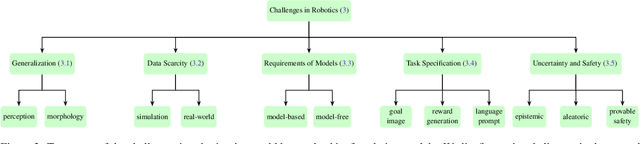
Building general-purpose robots that can operate seamlessly, in any environment, with any object, and utilizing various skills to complete diverse tasks has been a long-standing goal in Artificial Intelligence. Unfortunately, however, most existing robotic systems have been constrained - having been designed for specific tasks, trained on specific datasets, and deployed within specific environments. These systems usually require extensively-labeled data, rely on task-specific models, have numerous generalization issues when deployed in real-world scenarios, and struggle to remain robust to distribution shifts. Motivated by the impressive open-set performance and content generation capabilities of web-scale, large-capacity pre-trained models (i.e., foundation models) in research fields such as Natural Language Processing (NLP) and Computer Vision (CV), we devote this survey to exploring (i) how these existing foundation models from NLP and CV can be applied to the field of robotics, and also exploring (ii) what a robotics-specific foundation model would look like. We begin by providing an overview of what constitutes a conventional robotic system and the fundamental barriers to making it universally applicable. Next, we establish a taxonomy to discuss current work exploring ways to leverage existing foundation models for robotics and develop ones catered to robotics. Finally, we discuss key challenges and promising future directions in using foundation models for enabling general-purpose robotic systems. We encourage readers to view our living GitHub repository of resources, including papers reviewed in this survey as well as related projects and repositories for developing foundation models for robotics.
WIT-UAS: A Wildland-fire Infrared Thermal Dataset to Detect Crew Assets From Aerial Views
Dec 14, 2023



We present the Wildland-fire Infrared Thermal (WIT-UAS) dataset for long-wave infrared sensing of crew and vehicle assets amidst prescribed wildland fire environments. While such a dataset is crucial for safety monitoring in wildland fire applications, to the authors' awareness, no such dataset focusing on assets near fire is publicly available. Presumably, this is due to the barrier to entry of collaborating with fire management personnel. We present two related data subsets: WIT-UAS-ROS consists of full ROS bag files containing sensor and robot data of UAS flight over the fire, and WIT-UAS-Image contains hand-labeled long-wave infrared (LWIR) images extracted from WIT-UAS-ROS. Our dataset is the first to focus on asset detection in a wildland fire environment. We show that thermal detection models trained without fire data frequently detect false positives by classifying fire as people. By adding our dataset to training, we show that the false positive rate is reduced significantly. Yet asset detection in wildland fire environments is still significantly more challenging than detection in urban environments, due to dense obscuring trees, greater heat variation, and overbearing thermal signal of the fire. We publicize this dataset to encourage the community to study more advanced models to tackle this challenging environment. The dataset, code and pretrained models are available at \url{https://github.com/castacks/WIT-UAS-Dataset}.
SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
Dec 04, 2023



Dense simultaneous localization and mapping (SLAM) is pivotal for embodied scene understanding. Recent work has shown that 3D Gaussians enable high-quality reconstruction and real-time rendering of scenes using multiple posed cameras. In this light, we show for the first time that representing a scene by 3D Gaussians can enable dense SLAM using a single unposed monocular RGB-D camera. Our method, SplaTAM, addresses the limitations of prior radiance field-based representations, including fast rendering and optimization, the ability to determine if areas have been previously mapped, and structured map expansion by adding more Gaussians. We employ an online tracking and mapping pipeline while tailoring it to specifically use an underlying Gaussian representation and silhouette-guided optimization via differentiable rendering. Extensive experiments show that SplaTAM achieves up to 2X state-of-the-art performance in camera pose estimation, map construction, and novel-view synthesis, demonstrating its superiority over existing approaches, while allowing real-time rendering of a high-resolution dense 3D map.
PIAug -- Physics Informed Augmentation for Learning Vehicle Dynamics for Off-Road Navigation
Nov 01, 2023



Modeling the precise dynamics of off-road vehicles is a complex yet essential task due to the challenging terrain they encounter and the need for optimal performance and safety. Recently, there has been a focus on integrating nominal physics-based models alongside data-driven neural networks using Physics Informed Neural Networks. These approaches often assume the availability of a well-distributed dataset; however, this assumption may not hold due to regions in the physical distribution that are hard to collect, such as high-speed motions and rare terrains. Therefore, we introduce a physics-informed data augmentation methodology called PIAug. We show an example use case of the same by modeling high-speed and aggressive motion predictions, given a dataset with only low-speed data. During the training phase, we leverage the nominal model for generating target domain (medium and high velocity) data using the available source data (low velocity). Subsequently, we employ a physics-inspired loss function with this augmented dataset to incorporate prior knowledge of physics into the neural network. Our methodology results in up to 67% less mean error in trajectory prediction in comparison to a standalone nominal model, especially during aggressive maneuvers at speeds outside the training domain. In real-life navigation experiments, our model succeeds in 4x tighter waypoint tracking constraints than the Kinematic Bicycle Model (KBM) at out-of-domain velocities.
FoundLoc: Vision-based Onboard Aerial Localization in the Wild
Oct 25, 2023



Robust and accurate localization for Unmanned Aerial Vehicles (UAVs) is an essential capability to achieve autonomous, long-range flights. Current methods either rely heavily on GNSS, face limitations in visual-based localization due to appearance variances and stylistic dissimilarities between camera and reference imagery, or operate under the assumption of a known initial pose. In this paper, we developed a GNSS-denied localization approach for UAVs that harnesses both Visual-Inertial Odometry (VIO) and Visual Place Recognition (VPR) using a foundation model. This paper presents a novel vision-based pipeline that works exclusively with a nadir-facing camera, an Inertial Measurement Unit (IMU), and pre-existing satellite imagery for robust, accurate localization in varied environments and conditions. Our system demonstrated average localization accuracy within a $20$-meter range, with a minimum error below $1$ meter, under real-world conditions marked by drastic changes in environmental appearance and with no assumption of the vehicle's initial pose. The method is proven to be effective and robust, addressing the crucial need for reliable UAV localization in GNSS-denied environments, while also being computationally efficient enough to be deployed on resource-constrained platforms.
Enhancing Multi-Drone Coordination for Filming Group Behaviours in Dynamic Environments
Oct 19, 2023



Multi-Agent Path Finding (MAPF) is a fundamental problem in robotics and AI, with numerous applications in real-world scenarios. One such scenario is filming scenes with multiple actors, where the goal is to capture the scene from multiple angles simultaneously. Here, we present a formation-based filming directive of task assignment followed by a Conflict-Based MAPF algorithm for efficient path planning of multiple agents to achieve filming objectives while avoiding collisions. We propose an extension to the standard MAPF formulation to accommodate actor-specific requirements and constraints. Our approach incorporates Conflict-Based Search, a widely used heuristic search technique for solving MAPF problems. We demonstrate the effectiveness of our approach through experiments on various MAPF scenarios in a simulated environment. The proposed algorithm enables the efficient online task assignment of formation-based filming to capture dynamic scenes, making it suitable for various filming and coverage applications.