 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermodynamic Prediction Enabled by Automatic Dataset Building and Machine Learning
Jul 09, 2025New discoveries in chemistry and materials science, with increasingly expanding volume of requisite knowledge and experimental workload, provide unique opportunities for machine learning (ML) to take critical roles in accelerating research efficiency. Here, we demonstrate (1) the use of large language models (LLMs) for automated literature reviews, and (2) the training of an ML model to predict chemical knowledge (thermodynamic parameters). Our LLM-based literature review tool (LMExt) successfully extracted chemical information and beyond into a machine-readable structure, including stability constants for metal cation-ligand interactions, thermodynamic properties, and other broader data types (medical research papers, and financial reports), effectively overcoming the challenges inherent in each domain. Using the autonomous acquisition of thermodynamic data, an ML model was trained using the CatBoost algorithm for accurately predicting thermodynamic parameters (e.g., enthalpy of formation) of minerals. This work highlights the transformative potential of integrated ML approaches to reshape chemistry and materials science research.
Flying Hand: End-Effector-Centric Framework for Versatile Aerial Manipulation Teleoperation and Policy Learning
Apr 14, 2025Aerial manipulation has recently attracted increasing interest from both industry and academia. Previous approaches have demonstrated success in various specific tasks. However, their hardware design and control frameworks are often tightly coupled with task specifications, limiting the development of cross-task and cross-platform algorithms. Inspired by the success of robot learning in tabletop manipulation, we propose a unified aerial manipulation framework with an end-effector-centric interface that decouples high-level platform-agnostic decision-making from task-agnostic low-level control. Our framework consists of a fully-actuated hexarotor with a 4-DoF robotic arm, an end-effector-centric whole-body model predictive controller, and a high-level policy. The high-precision end-effector controller enables efficient and intuitive aerial teleoperation for versatile tasks and facilitates the development of imitation learning policies. Real-world experiments show that the proposed framework significantly improves end-effector tracking accuracy, and can handle multiple aerial teleoperation and imitation learning tasks, including writing, peg-in-hole, pick and place, changing light bulbs, etc. We believe the proposed framework provides one way to standardize and unify aerial manipulation into the general manipulation community and to advance the field. Project website: https://lecar-lab.github.io/flying_hand/.
Flying Calligrapher: Contact-Aware Motion and Force Planning and Control for Aerial Manipulation
Jul 08, 2024



Aerial manipulation has gained interest in completing high-altitude tasks that are challenging for human workers, such as contact inspection and defect detection, etc. Previous research has focused on maintaining static contact points or forces. This letter addresses a more general and dynamic task: simultaneously tracking time-varying contact force in the surface normal direction and motion trajectories on tangential surfaces. We propose a pipeline that includes a contact-aware trajectory planner to generate dynamically feasible trajectories, and a hybrid motion-force controller to track such trajectories. We demonstrate the approach in an aerial calligraphy task using a novel sponge pen design as the end-effector, whose stroke width is proportional to the contact force. Additionally, we develop a touchscreen interface for flexible user input. Experiments show our method can effectively draw diverse letters, achieving an IoU of 0.59 and an end-effector position (force) tracking RMSE of 2.9 cm (0.7 N). Website: https://xiaofeng-guo.github.io/flying-calligrapher/
Aerial Interaction with Tactile Sensing
Sep 29, 2023While autonomous Uncrewed Aerial Vehicles (UAVs) have grown rapidly, most applications only focus on passive visual tasks. Aerial interaction aims to execute tasks involving physical interactions, which offers a way to assist humans in high-risk, high-altitude operations, thereby reducing cost, time, and potential hazards. The coupled dynamics between the aerial vehicle and manipulator, however, pose challenges for precision control. Previous research has typically employed either position control, which often fails to meet mission accuracy, or force control using expensive, heavy, and cumbersome force/torque sensors that also lack local semantic information. Conversely, tactile sensors, being both cost-effective and lightweight, are capable of sensing contact information including force distribution, as well as recognizing local textures. Existing work on tactile sensing mainly focuses on tabletop manipulation tasks within a quasi-static process. In this paper, we pioneer the use of vision-based tactile sensors on a fully-actuated UAV to improve the accuracy of the more dynamic aerial manipulation tasks. We introduce a pipeline utilizing tactile feedback for real-time force tracking via a hybrid motion-force controller and a method for wall texture detection during aerial interactions. Our experiments demonstrate that our system can effectively replace or complement traditional force/torque sensors, improving flight performance by approximately 16% in position tracking error when using the fused force estimate compared to relying on a single sensor. Our tactile sensor achieves 93.4% accuracy in real-time texture recognition and 100% post-contact. To the best of our knowledge, this is the first work to incorporate a vision-based tactile sensor into aerial interaction tasks.
Estimating Properties of Solid Particles Inside Container Using Touch Sensing
Jul 28, 2023Solid particles, such as rice and coffee beans, are commonly stored in containers and are ubiquitous in our daily lives. Understanding those particles' properties could help us make later decisions or perform later manipulation tasks such as pouring. Humans typically interact with the containers to get an understanding of the particles inside them, but it is still a challenge for robots to achieve that. This work utilizes tactile sensing to estimate multiple properties of solid particles enclosed in the container, specifically, content mass, content volume, particle size, and particle shape. We design a sequence of robot actions to interact with the container. Based on physical understanding, we extract static force/torque value from the F/T sensor, vibration-related features and topple-related features from the newly designed high-speed GelSight tactile sensor to estimate those four particle properties. We test our method on $37$ very different daily particles, including powder, rice, beans, tablets, etc. Experiments show that our approach is able to estimate content mass with an error of $1.8$ g, content volume with an error of $6.1$ ml, particle size with an error of $1.1$ mm, and achieves an accuracy of $75.6$% for particle shape estimation. In addition, our method can generalize to unseen particles with unknown volumes. By estimating these particle properties, our method can help robots to better perceive the granular media and help with different manipulation tasks in daily life and industry.
Machine Learning Automated Approach for Enormous Synchrotron X-Ray Diffraction Data Interpretation
Mar 20, 2023Manual analysis of XRD data is usually laborious and time consuming. The deep neural network (DNN) based models trained by synthetic XRD patterns are proved to be an automatic, accurate, and high throughput method to analysis common XRD data collected from solid sample in ambient environment. However, it remains unknown that whether synthetic XRD based models are capable to solve u-XRD mapping data for in-situ experiments involving liquid phase exhibiting lower quality with significant artifacts. In this study, we collected u-XRD mapping data from an LaCl3-calcite hydrothermal fluid system and trained two categories of models to solve the experimental XRD patterns. The models trained by synthetic XRD patterns show low accuracy (as low as 64%) when solving experimental u-XRD mapping data. The accuracy of the DNN models was significantly improved (90% or above) when training them with the dataset containing both synthetic and small number of labeled experimental u-XRD patterns. This study highlighted the importance of labeled experimental patterns on the training of DNN models to solve u-XRD mapping data from in-situ experiments involving liquid phase.
Deep Reinforcement Learning for Robotic Pushing and Picking in Cluttered Environment
Feb 21, 2023



In this paper, a novel robotic grasping system is established to automatically pick up objects in cluttered scenes. A composite robotic hand composed of a suction cup and a gripper is designed for grasping the object stably. The suction cup is used for lifting the object from the clutter first and the gripper for grasping the object accordingly. We utilize the affordance map to provide pixel-wise lifting point candidates for the suction cup. To obtain a good affordance map, the active exploration mechanism is introduced to the system. An effective metric is designed to calculate the reward for the current affordance map, and a deep Q-Network (DQN) is employed to guide the robotic hand to actively explore the environment until the generated affordance map is suitable for grasping. Experimental results have demonstrated that the proposed robotic grasping system is able to greatly increase the success rate of the robotic grasping in cluttered scenes.
* has been accepted by IEEE/RSJ International Conference on Intelligent Robots and Systems 2019
1st Place Solution for PSG competition with ECCV'22 SenseHuman Workshop
Feb 06, 2023



Panoptic Scene Graph (PSG) generation aims to generate scene graph representations based on panoptic segmentation instead of rigid bounding boxes. Existing PSG methods utilize one-stage paradigm which simultaneously generates scene graphs and predicts semantic segmentation masks or two-stage paradigm that first adopt an off-the-shelf panoptic segmentor, then pairwise relationship prediction between these predicted objects. One-stage approach despite having a simplified training paradigm, its segmentation results are usually under-satisfactory, while two-stage approach lacks global context and leads to low performance on relation prediction. To bridge this gap, in this paper, we propose GRNet, a Global Relation Network in two-stage paradigm, where the pre-extracted local object features and their corresponding masks are fed into a transformer with class embeddings. To handle relation ambiguity and predicate classification bias caused by long-tailed distribution, we formulate relation prediction in the second stage as a multi-class classification task with soft label. We conduct comprehensive experiments on OpenPSG dataset and achieve the state-of-art performance on the leadboard. We also show the effectiveness of our soft label strategy for long-tailed classes in ablation studies. Our code has been released in https://github.com/wangqixun/mfpsg.
LaT: Latent Translation with Cycle-Consistency for Video-Text Retrieval
Jul 11, 2022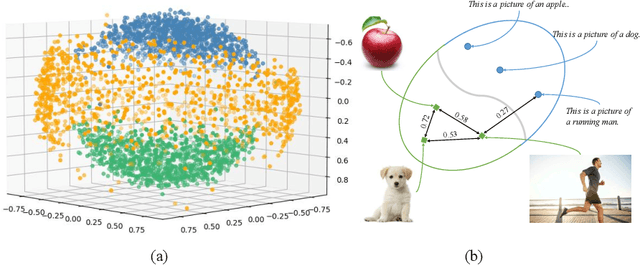
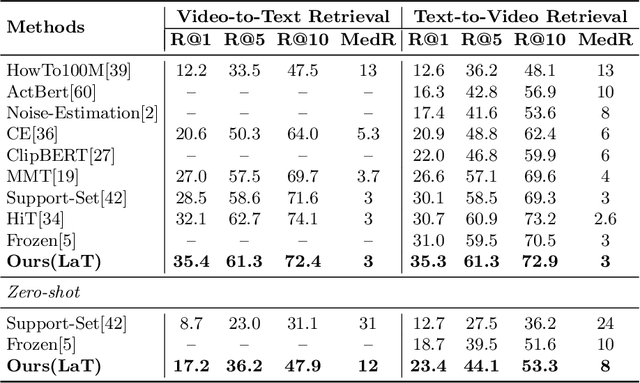
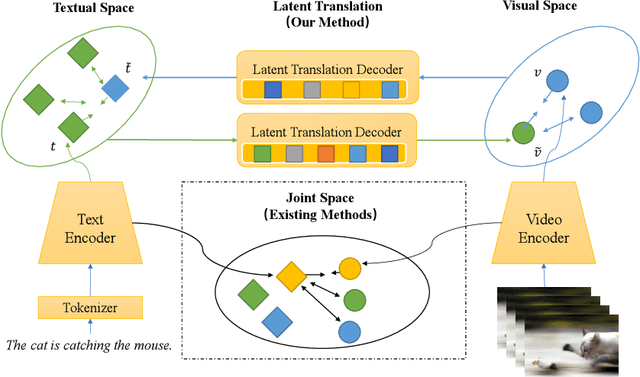
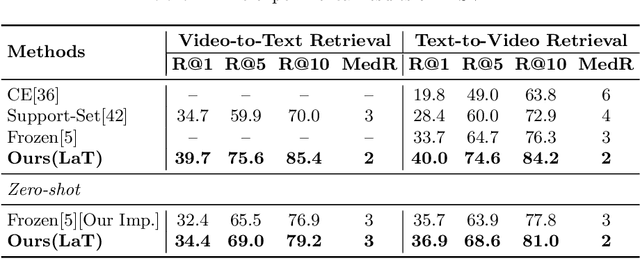
Video-text retrieval is a class of cross-modal representation learning problems, where the goal is to select the video which corresponds to the text query between a given text query and a pool of candidate videos. The contrastive paradigm of vision-language pretraining has shown promising success with large-scale datasets and unified transformer architecture, and demonstrated the power of a joint latent space. Despite this, the intrinsic divergence between the visual domain and textual domain is still far from being eliminated, and projecting different modalities into a joint latent space might result in the distorting of the information inside the single modality. To overcome the above issue, we present a novel mechanism for learning the translation relationship from a source modality space $\mathcal{S}$ to a target modality space $\mathcal{T}$ without the need for a joint latent space, which bridges the gap between visual and textual domains. Furthermore, to keep cycle consistency between translations, we adopt a cycle loss involving both forward translations from $\mathcal{S}$ to the predicted target space $\mathcal{T'}$, and backward translations from $\mathcal{T'}$ back to $\mathcal{S}$. Extensive experiments conducted on MSR-VTT, MSVD, and DiDeMo datasets demonstrate the superiority and effectiveness of our LaT approach compared with vanilla state-of-the-art methods.
Understanding Dynamic Tactile Sensing for Liquid Property Estimation
May 18, 2022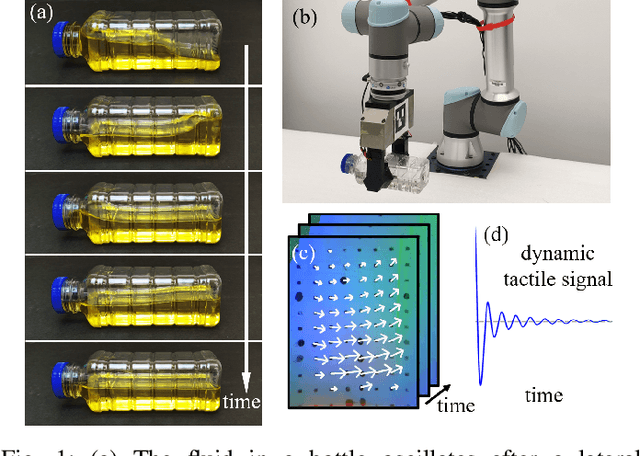
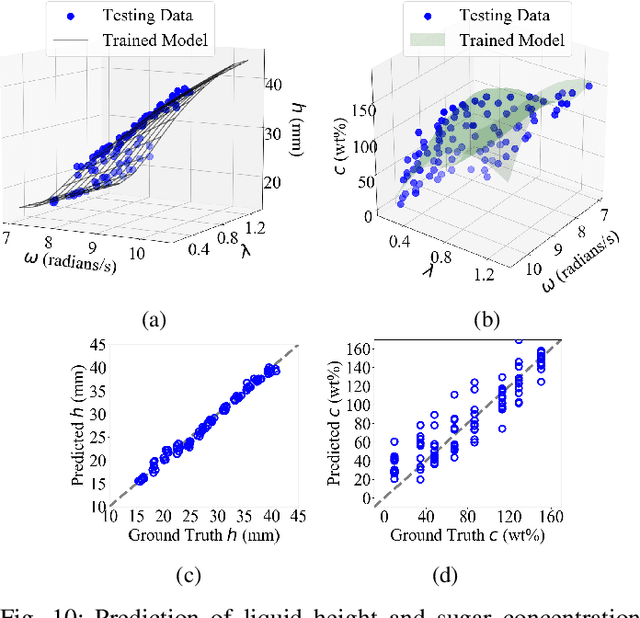
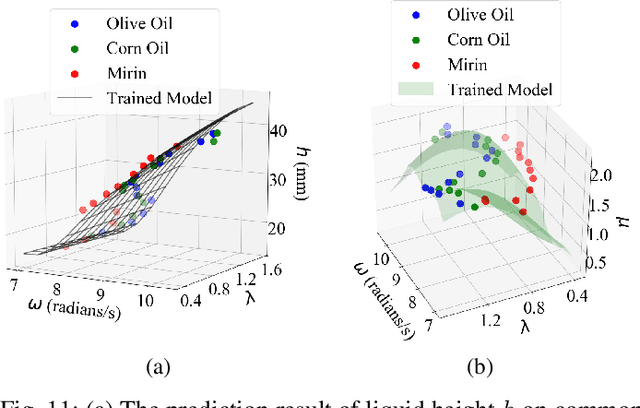
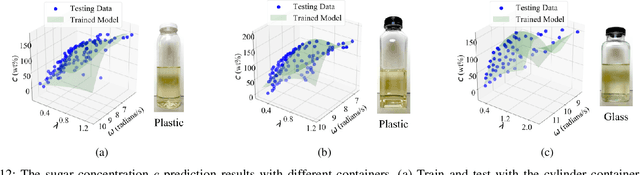
Humans perceive the world by interacting with objects, which often happens in a dynamic way. For example, a human would shake a bottle to guess its content. However, it remains a challenge for robots to understand many dynamic signals during contact well. This paper investigates dynamic tactile sensing by tackling the task of estimating liquid properties. We propose a new way of thinking about dynamic tactile sensing: by building a light-weighted data-driven model based on the simplified physical principle. The liquid in a bottle will oscillate after a perturbation. We propose a simple physics-inspired model to explain this oscillation and use a high-resolution tactile sensor GelSight to sense it. Specifically, the viscosity and the height of the liquid determine the decay rate and frequency of the oscillation. We then train a Gaussian Process Regression model on a small amount of the real data to estimate the liquid properties. Experiments show that our model can classify three different liquids with 100% accuracy. The model can estimate volume with high precision and even estimate the concentration of sugar-water solution. It is data-efficient and can easily generalize to other liquids and bottles. Our work posed a physically-inspired understanding of the correlation between dynamic tactile signals and the dynamic performance of the liquid. Our approach creates a good balance between simplicity, accuracy, and generality. It will help robots to better perceive liquids in different environments such as kitchens, food factories, and pharmaceutical factories.