 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAIR: Learning Sparse Text and Image Representation in Grounded Tokens
Feb 08, 2023Image and text retrieval is one of the foundational tasks in the vision and language domain with multiple real-world applications. State-of-the-art approaches, e.g. CLIP, ALIGN, represent images and texts as dense embeddings and calculate the similarity in the dense embedding space as the matching score. On the other hand, sparse semantic features like bag-of-words models are more interpretable, but believed to suffer from inferior accuracy than dense representations. In this work, we show that it is possible to build a sparse semantic representation that is as powerful as, or even better than, dense presentations. We extend the CLIP model and build a sparse text and image representation (STAIR), where the image and text are mapped to a sparse token space. Each token in the space is a (sub-)word in the vocabulary, which is not only interpretable but also easy to integrate with existing information retrieval systems. STAIR model significantly outperforms a CLIP model with +$4.9\%$ and +$4.3\%$ absolute Recall@1 improvement on COCO-5k text$\rightarrow$image and image$\rightarrow$text retrieval respectively. It also achieved better performance on both of ImageNet zero-shot and linear probing compared to CLIP.
A Language Agnostic Multilingual Streaming On-Device ASR System
Aug 29, 2022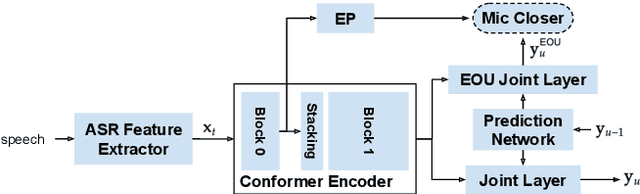
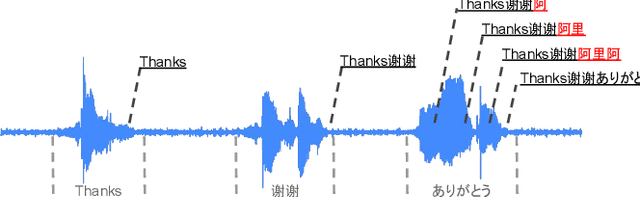
On-device end-to-end (E2E) models have shown improvements over a conventional model on English Voice Search tasks in both quality and latency. E2E models have also shown promising results for multilingual automatic speech recognition (ASR). In this paper, we extend our previous capacity solution to streaming applications and present a streaming multilingual E2E ASR system that runs fully on device with comparable quality and latency to individual monolingual models. To achieve that, we propose an Encoder Endpointer model and an End-of-Utterance (EOU) Joint Layer for a better quality and latency trade-off. Our system is built in a language agnostic manner allowing it to natively support intersentential code switching in real time. To address the feasibility concerns on large models, we conducted on-device profiling and replaced the time consuming LSTM decoder with the recently developed Embedding decoder. With these changes, we managed to run such a system on a mobile device in less than real time.
Pathways: Asynchronous Distributed Dataflow for ML
Mar 23, 2022
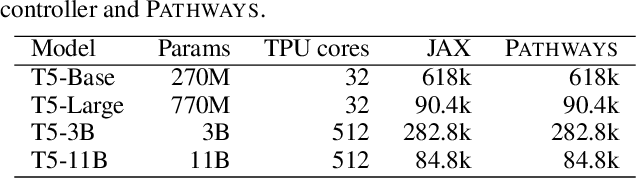
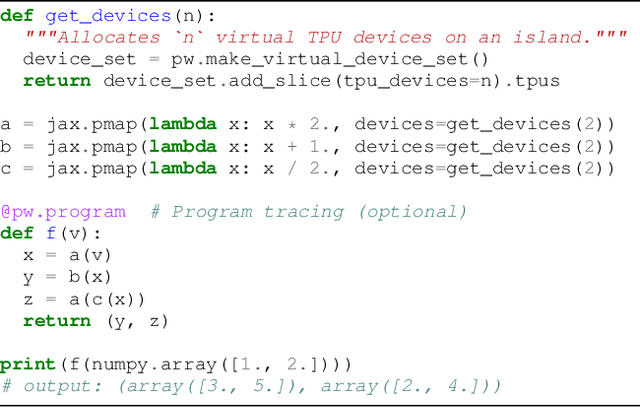
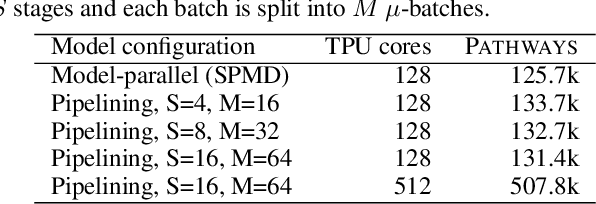
We present the design of a new large scale orchestration layer for accelerators. Our system, Pathways, is explicitly designed to enable exploration of new systems and ML research ideas, while retaining state of the art performance for current models. Pathways uses a sharded dataflow graph of asynchronous operators that consume and produce futures, and efficiently gang-schedules heterogeneous parallel computations on thousands of accelerators while coordinating data transfers over their dedicated interconnects. Pathways makes use of a novel asynchronous distributed dataflow design that lets the control plane execute in parallel despite dependencies in the data plane. This design, with careful engineering, allows Pathways to adopt a single-controller model that makes it easier to express complex new parallelism patterns. We demonstrate that Pathways can achieve performance parity (~100% accelerator utilization) with state-of-the-art systems when running SPMD computations over 2048 TPUs, while also delivering throughput comparable to the SPMD case for Transformer models that are pipelined across 16 stages, or sharded across two islands of accelerators connected over a data center network.
Sentence-Select: Large-Scale Language Model Data Selection for Rare-Word Speech Recognition
Mar 09, 2022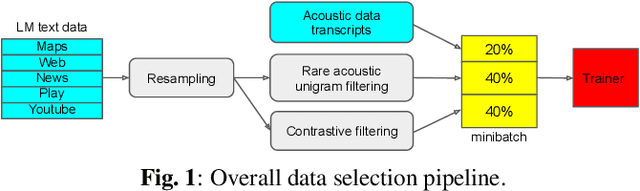
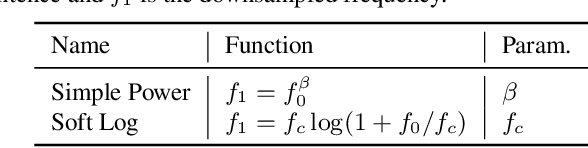
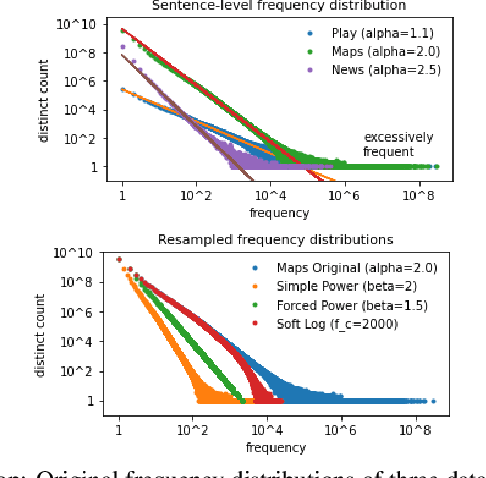
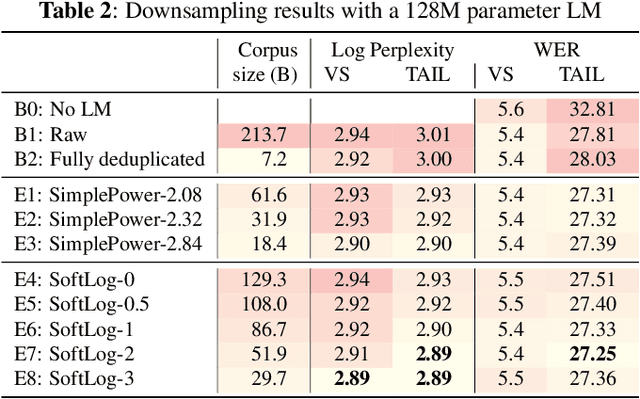
Language model fusion helps smart assistants recognize words which are rare in acoustic data but abundant in text-only corpora (typed search logs). However, such corpora have properties that hinder downstream performance, including being (1) too large, (2) beset with domain-mismatched content, and (3) heavy-headed rather than heavy-tailed (excessively many duplicate search queries such as "weather"). We show that three simple strategies for selecting language modeling data can dramatically improve rare-word recognition without harming overall performance. First, to address the heavy-headedness, we downsample the data according to a soft log function, which tunably reduces high frequency (head) sentences. Second, to encourage rare-word exposure, we explicitly filter for words rare in the acoustic data. Finally, we tackle domain-mismatch via perplexity-based contrastive selection, filtering for examples matched to the target domain. We down-select a large corpus of web search queries by a factor of 53x and achieve better LM perplexities than without down-selection. When shallow-fused with a state-of-the-art, production speech engine, our LM achieves WER reductions of up to 24% relative on rare-word sentences (without changing overall WER) compared to a baseline LM trained on the raw corpus. These gains are further validated through favorable side-by-side evaluations on live voice search traffic.
Co-training Transformer with Videos and Images Improves Action Recognition
Dec 14, 2021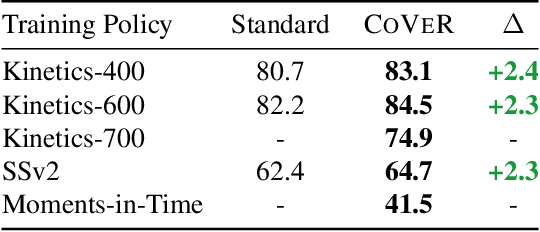
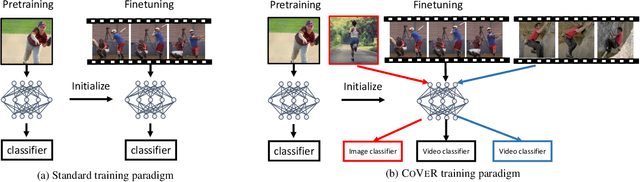

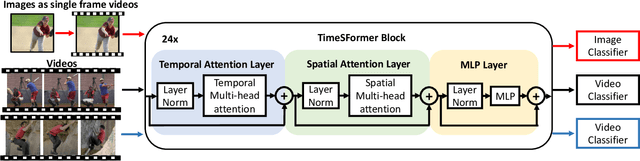
In learning action recognition, models are typically pre-trained on object recognition with images, such as ImageNet, and later fine-tuned on target action recognition with videos. This approach has achieved good empirical performance especially with recent transformer-based video architectures. While recently many works aim to design more advanced transformer architectures for action recognition, less effort has been made on how to train video transformers. In this work, we explore several training paradigms and present two findings. First, video transformers benefit from joint training on diverse video datasets and label spaces (e.g., Kinetics is appearance-focused while SomethingSomething is motion-focused). Second, by further co-training with images (as single-frame videos), the video transformers learn even better video representations. We term this approach as Co-training Videos and Images for Action Recognition (CoVeR). In particular, when pretrained on ImageNet-21K based on the TimeSFormer architecture, CoVeR improves Kinetics-400 Top-1 Accuracy by 2.4%, Kinetics-600 by 2.3%, and SomethingSomething-v2 by 2.3%. When pretrained on larger-scale image datasets following previous state-of-the-art, CoVeR achieves best results on Kinetics-400 (87.2%), Kinetics-600 (87.9%), Kinetics-700 (79.8%), SomethingSomething-v2 (70.9%), and Moments-in-Time (46.1%), with a simple spatio-temporal video transformer.
Vector-quantized Image Modeling with Improved VQGAN
Oct 09, 2021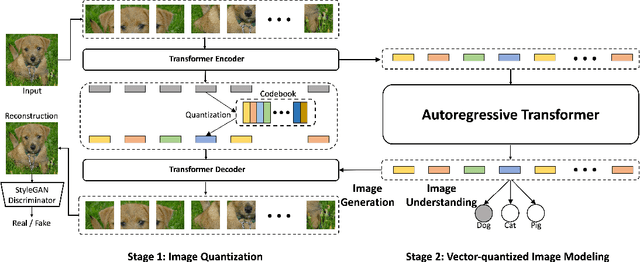



Pretraining language models with next-token prediction on massive text corpora has delivered phenomenal zero-shot, few-shot, transfer learning and multi-tasking capabilities on both generative and discriminative language tasks. Motivated by this success, we explore a Vector-quantized Image Modeling (VIM) approach that involves pretraining a Transformer to predict rasterized image tokens autoregressively. The discrete image tokens are encoded from a learned Vision-Transformer-based VQGAN (ViT-VQGAN). We first propose multiple improvements over vanilla VQGAN from architecture to codebook learning, yielding better efficiency and reconstruction fidelity. The improved ViT-VQGAN further improves vector-quantized image modeling tasks, including unconditional, class-conditioned image generation and unsupervised representation learning. When trained on ImageNet at 256x256 resolution, we achieve Inception Score (IS) of 175.1 and Fr'echet Inception Distance (FID) of 4.17, a dramatic improvement over the vanilla VQGAN, which obtains 70.6 and 17.04 for IS and FID, respectively. Based on ViT-VQGAN and unsupervised pretraining, we further evaluate the pretrained Transformer by averaging intermediate features, similar to Image GPT (iGPT). This ImageNet-pretrained VIM-L significantly beats iGPT-L on linear-probe accuracy from 60.3% to 72.2% for a similar model size. ViM-L also outperforms iGPT-XL which is trained with extra web image data and larger model size.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021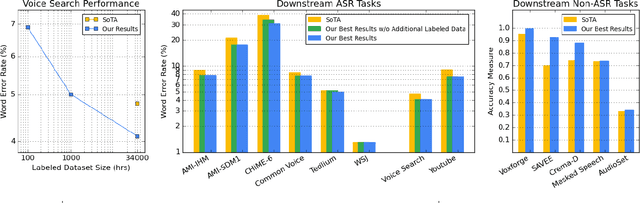
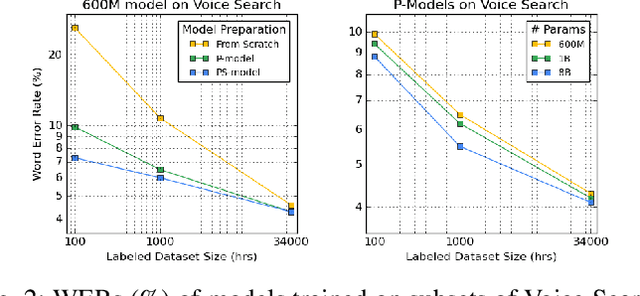
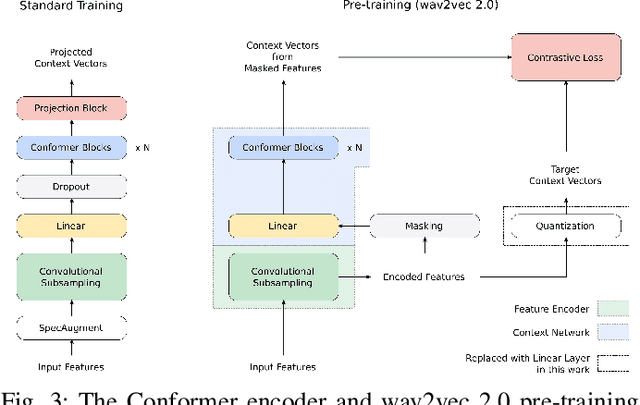
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
W2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training
Aug 07, 2021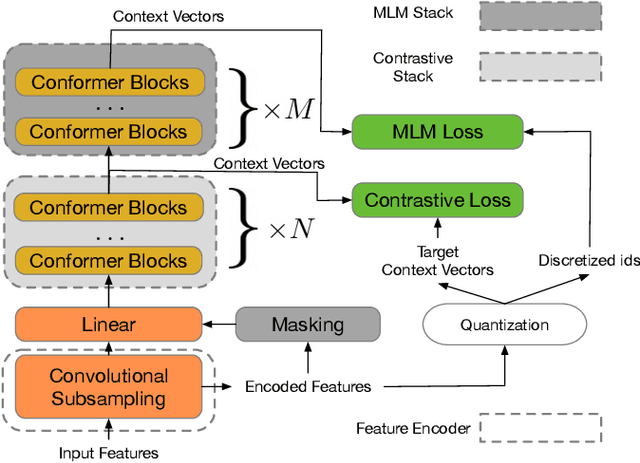

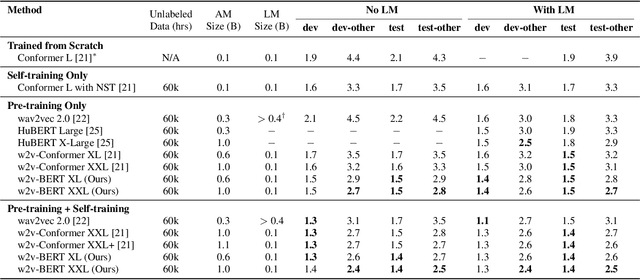
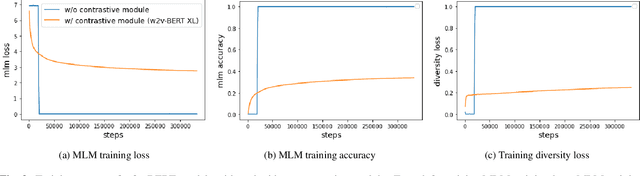
Motivated by the success of masked language modeling~(MLM) in pre-training natural language processing models, we propose w2v-BERT that explores MLM for self-supervised speech representation learning. w2v-BERT is a framework that combines contrastive learning and MLM, where the former trains the model to discretize input continuous speech signals into a finite set of discriminative speech tokens, and the latter trains the model to learn contextualized speech representations via solving a masked prediction task consuming the discretized tokens. In contrast to existing MLM-based speech pre-training frameworks such as HuBERT, which relies on an iterative re-clustering and re-training process, or vq-wav2vec, which concatenates two separately trained modules, w2v-BERT can be optimized in an end-to-end fashion by solving the two self-supervised tasks~(the contrastive task and MLM) simultaneously. Our experiments show that w2v-BERT achieves competitive results compared to current state-of-the-art pre-trained models on the LibriSpeech benchmarks when using the Libri-Light~60k corpus as the unsupervised data. In particular, when compared to published models such as conformer-based wav2vec~2.0 and HuBERT, our model shows~5\% to~10\% relative WER reduction on the test-clean and test-other subsets. When applied to the Google's Voice Search traffic dataset, w2v-BERT outperforms our internal conformer-based wav2vec~2.0 by more than~30\% relatively.
GSPMD: General and Scalable Parallelization for ML Computation Graphs
May 10, 2021

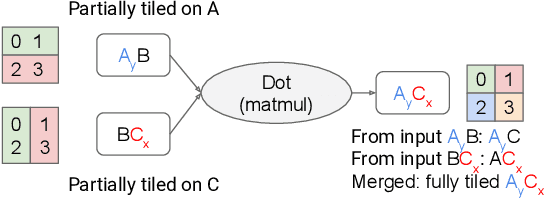
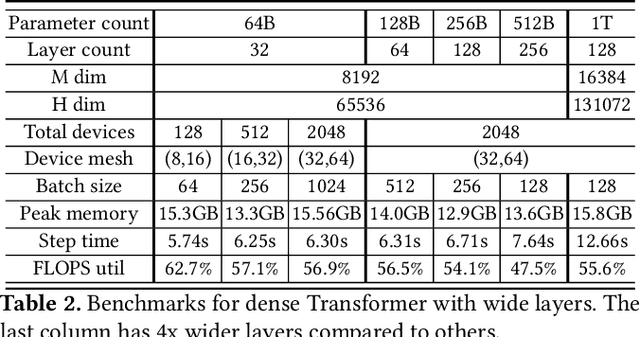
We present GSPMD, an automatic, compiler-based parallelization system for common machine learning computation graphs. It allows users to write programs in the same way as for a single device, then give hints through a few annotations on how to distribute tensors, based on which GSPMD will parallelize the computation. Its representation of partitioning is simple yet general, allowing it to express different or mixed paradigms of parallelism on a wide variety of models. GSPMD infers the partitioning for every operator in the graph based on limited user annotations, making it convenient to scale up existing single-device programs. It solves several technical challenges for production usage, such as static shape constraints, uneven partitioning, exchange of halo data, and nested operator partitioning. These techniques allow GSPMD to achieve 50% to 62% compute utilization on 128 to 2048 Cloud TPUv3 cores for models with up to one trillion parameters. GSPMD produces a single program for all devices, which adjusts its behavior based on a run-time partition ID, and uses collective operators for cross-device communication. This property allows the system itself to be scalable: the compilation time stays constant with increasing number of devices.
Scaling End-to-End Models for Large-Scale Multilingual ASR
Apr 30, 2021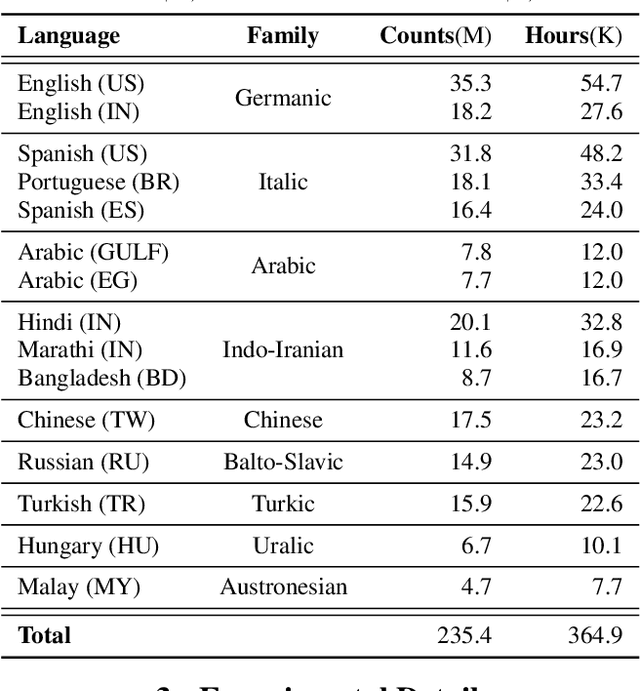
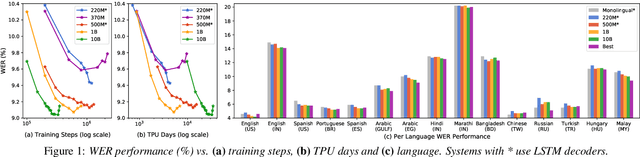
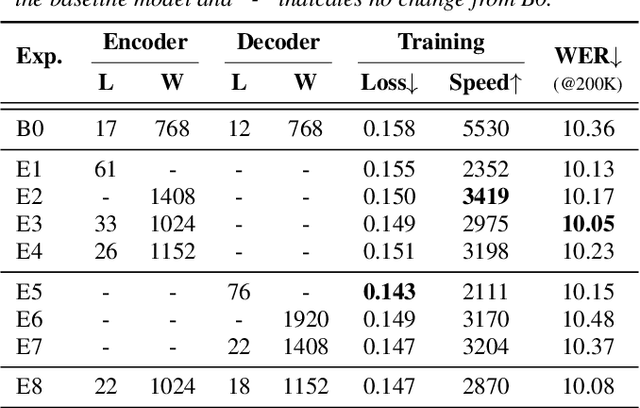
Building ASR models across many language families is a challenging multi-task learning problem due to large language variations and heavily unbalanced data. Existing work has shown positive transfer from high resource to low resource languages. However, degradations on high resource languages are commonly observed due to interference from the heterogeneous multilingual data and reduction in per-language capacity. We conduct a capacity study on a 15-language task, with the amount of data per language varying from 7.7K to 54.7K hours. We adopt GShard [1] to efficiently scale up to 10B parameters. Empirically, we find that (1) scaling the number of model parameters is an effective way to solve the capacity bottleneck - our 500M-param model is already better than monolingual baselines and scaling it to 1B and 10B brought further quality gains; (2) larger models are not only more data efficient, but also more efficient in terms of training cost as measured in TPU days - the 1B-param model reaches the same accuracy at 34% of training time as the 500M-param model; (3) given a fixed capacity budget, adding depth usually works better than width and large encoders tend to do better than large decoders.