 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Contrastive Learning for Spatio-temporal Representation
Jul 12, 2022
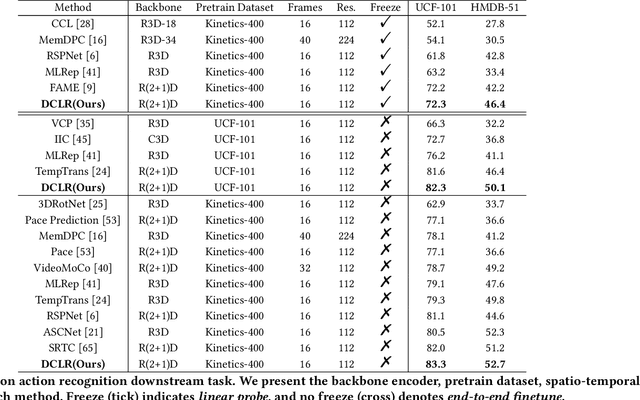
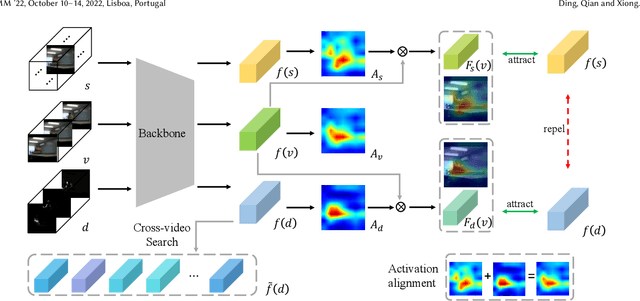
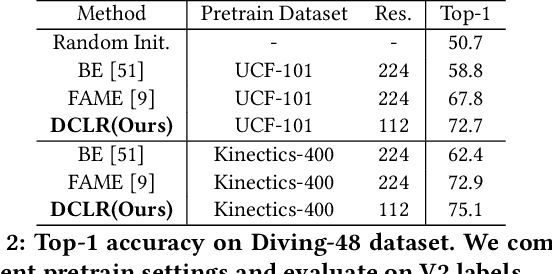
Contrastive learning has shown promising potential in self-supervised spatio-temporal representation learning. Most works naively sample different clips to construct positive and negative pairs. However, we observe that this formulation inclines the model towards the background scene bias. The underlying reasons are twofold. First, the scene difference is usually more noticeable and easier to discriminate than the motion difference. Second, the clips sampled from the same video often share similar backgrounds but have distinct motions. Simply regarding them as positive pairs will draw the model to the static background rather than the motion pattern. To tackle this challenge, this paper presents a novel dual contrastive formulation. Concretely, we decouple the input RGB video sequence into two complementary modes, static scene and dynamic motion. Then, the original RGB features are pulled closer to the static features and the aligned dynamic features, respectively. In this way, the static scene and the dynamic motion are simultaneously encoded into the compact RGB representation. We further conduct the feature space decoupling via activation maps to distill static- and dynamic-related features. We term our method as \textbf{D}ual \textbf{C}ontrastive \textbf{L}earning for spatio-temporal \textbf{R}epresentation (DCLR). Extensive experiments demonstrate that DCLR learns effective spatio-temporal representations and obtains state-of-the-art or comparable performance on UCF-101, HMDB-51, and Diving-48 datasets.
Controllable Augmentations for Video Representation Learning
Apr 01, 2022
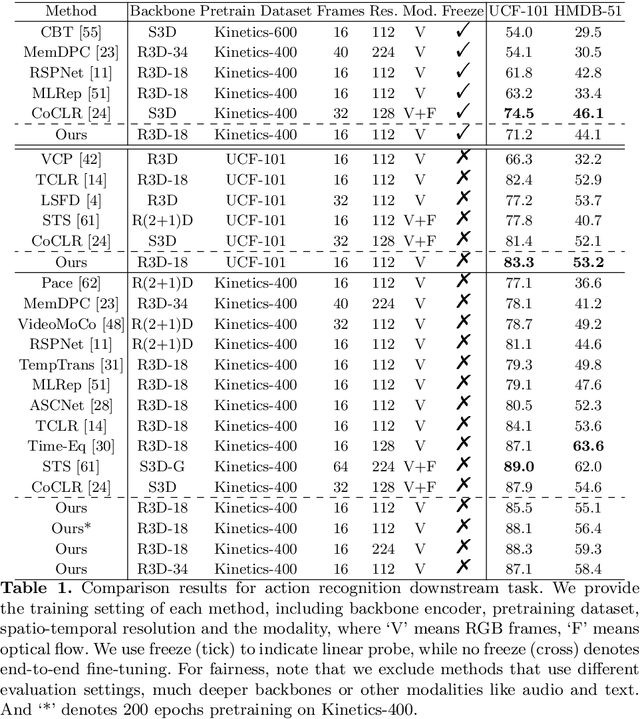
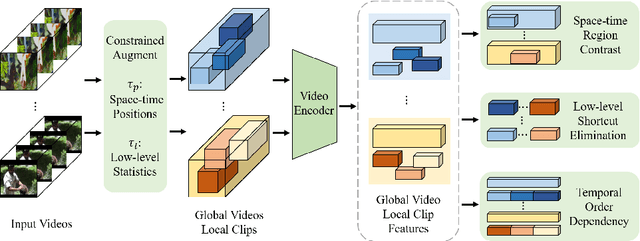
This paper focuses on self-supervised video representation learning. Most existing approaches follow the contrastive learning pipeline to construct positive and negative pairs by sampling different clips. However, this formulation tends to bias to static background and have difficulty establishing global temporal structures. The major reason is that the positive pairs, i.e., different clips sampled from the same video, have limited temporal receptive field, and usually share similar background but differ in motions. To address these problems, we propose a framework to jointly utilize local clips and global videos to learn from detailed region-level correspondence as well as general long-term temporal relations. Based on a set of controllable augmentations, we achieve accurate appearance and motion pattern alignment through soft spatio-temporal region contrast. Our formulation is able to avoid the low-level redundancy shortcut by mutual information minimization to improve the generalization. We also introduce local-global temporal order dependency to further bridge the gap between clip-level and video-level representations for robust temporal modeling. Extensive experiments demonstrate that our framework is superior on three video benchmarks in action recognition and video retrieval, capturing more accurate temporal dynamics.
Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation
Mar 24, 2022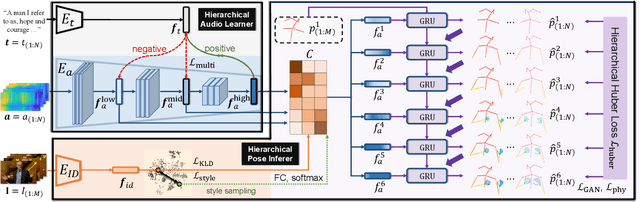
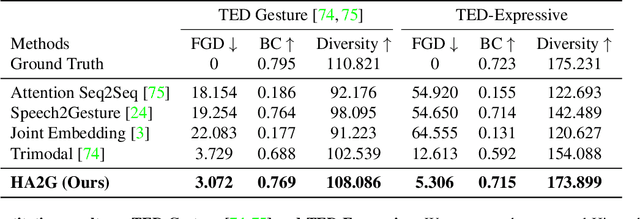
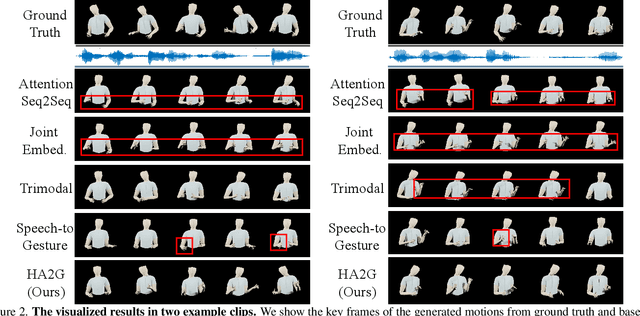

Generating speech-consistent body and gesture movements is a long-standing problem in virtual avatar creation. Previous studies often synthesize pose movement in a holistic manner, where poses of all joints are generated simultaneously. Such a straightforward pipeline fails to generate fine-grained co-speech gestures. One observation is that the hierarchical semantics in speech and the hierarchical structures of human gestures can be naturally described into multiple granularities and associated together. To fully utilize the rich connections between speech audio and human gestures, we propose a novel framework named Hierarchical Audio-to-Gesture (HA2G) for co-speech gesture generation. In HA2G, a Hierarchical Audio Learner extracts audio representations across semantic granularities. A Hierarchical Pose Inferer subsequently renders the entire human pose gradually in a hierarchical manner. To enhance the quality of synthesized gestures, we develop a contrastive learning strategy based on audio-text alignment for better audio representations. Extensive experiments and human evaluation demonstrate that the proposed method renders realistic co-speech gestures and outperforms previous methods in a clear margin. Project page: https://alvinliu0.github.io/projects/HA2G
Visual Sound Localization in the Wild by Cross-Modal Interference Erasing
Feb 13, 2022
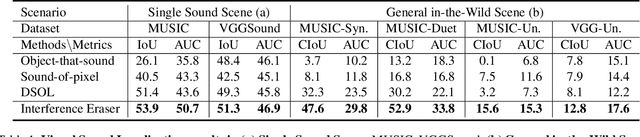
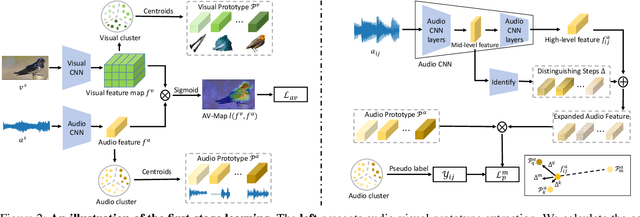

The task of audio-visual sound source localization has been well studied under constrained scenes, where the audio recordings are clean. However, in real-world scenarios, audios are usually contaminated by off-screen sound and background noise. They will interfere with the procedure of identifying desired sources and building visual-sound connections, making previous studies non-applicable. In this work, we propose the Interference Eraser (IEr) framework, which tackles the problem of audio-visual sound source localization in the wild. The key idea is to eliminate the interference by redefining and carving discriminative audio representations. Specifically, we observe that the previous practice of learning only a single audio representation is insufficient due to the additive nature of audio signals. We thus extend the audio representation with our Audio-Instance-Identifier module, which clearly distinguishes sounding instances when audio signals of different volumes are unevenly mixed. Then we erase the influence of the audible but off-screen sounds and the silent but visible objects by a Cross-modal Referrer module with cross-modality distillation. Quantitative and qualitative evaluations demonstrate that our proposed framework achieves superior results on sound localization tasks, especially under real-world scenarios. Code is available at https://github.com/alvinliu0/Visual-Sound-Localization-in-the-Wild.
Class-aware Sounding Objects Localization via Audiovisual Correspondence
Dec 22, 2021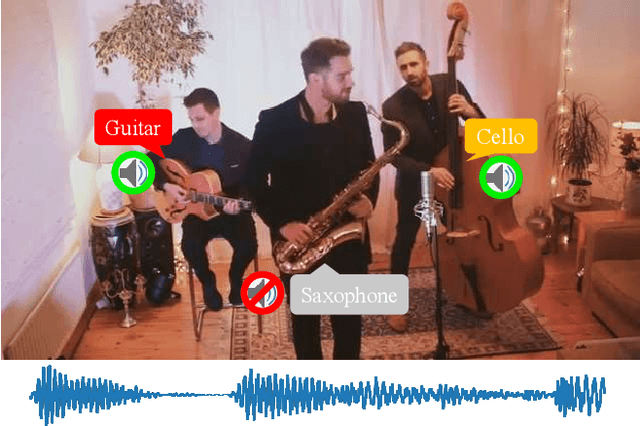

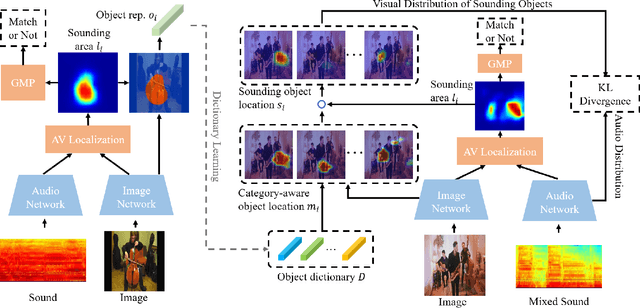
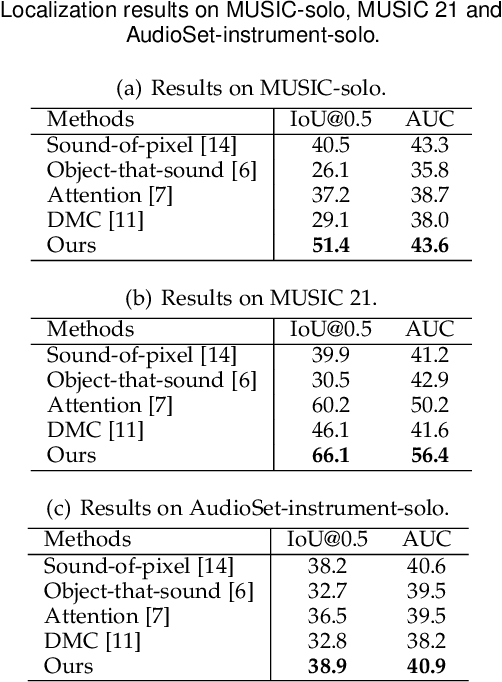
Audiovisual scenes are pervasive in our daily life. It is commonplace for humans to discriminatively localize different sounding objects but quite challenging for machines to achieve class-aware sounding objects localization without category annotations, i.e., localizing the sounding object and recognizing its category. To address this problem, we propose a two-stage step-by-step learning framework to localize and recognize sounding objects in complex audiovisual scenarios using only the correspondence between audio and vision. First, we propose to determine the sounding area via coarse-grained audiovisual correspondence in the single source cases. Then visual features in the sounding area are leveraged as candidate object representations to establish a category-representation object dictionary for expressive visual character extraction. We generate class-aware object localization maps in cocktail-party scenarios and use audiovisual correspondence to suppress silent areas by referring to this dictionary. Finally, we employ category-level audiovisual consistency as the supervision to achieve fine-grained audio and sounding object distribution alignment. Experiments on both realistic and synthesized videos show that our model is superior in localizing and recognizing objects as well as filtering out silent ones. We also transfer the learned audiovisual network into the unsupervised object detection task, obtaining reasonable performance.
Contextualized Spatio-Temporal Contrastive Learning with Self-Supervision
Dec 09, 2021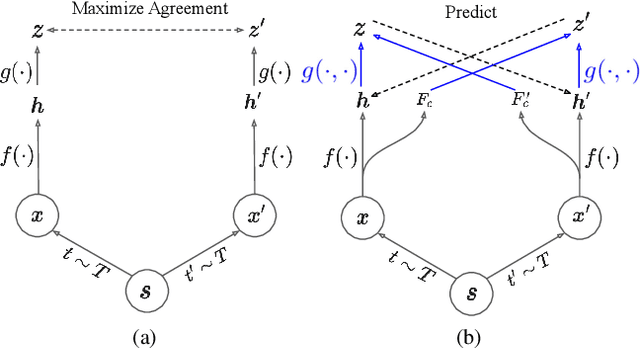
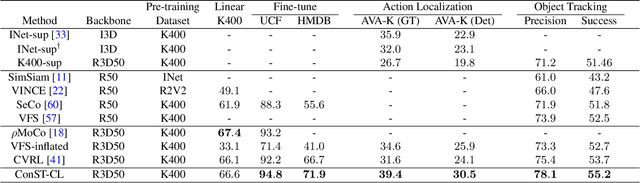
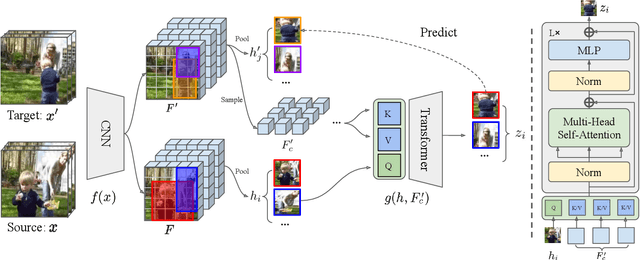
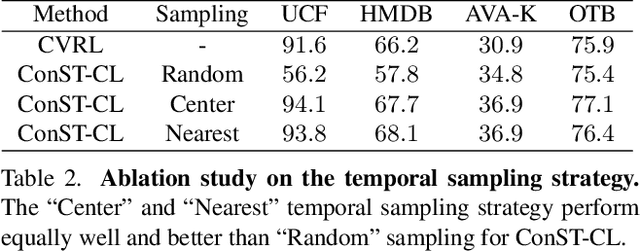
A modern self-supervised learning algorithm typically enforces persistency of the representations of an instance across views. While being very effective on learning holistic image and video representations, such an approach becomes sub-optimal for learning spatio-temporally fine-grained features in videos, where scenes and instances evolve through space and time. In this paper, we present the Contextualized Spatio-Temporal Contrastive Learning (ConST-CL) framework to effectively learn spatio-temporally fine-grained representations using self-supervision. We first design a region-based self-supervised pretext task which requires the model to learn to transform instance representations from one view to another guided by context features. Further, we introduce a simple network design that effectively reconciles the simultaneous learning process of both holistic and local representations. We evaluate our learned representations on a variety of downstream tasks and ConST-CL achieves state-of-the-art results on four datasets. For spatio-temporal action localization, ConST-CL achieves 39.4% mAP with ground-truth boxes and 30.5% mAP with detected boxes on the AVA-Kinetics validation set. For object tracking, ConST-CL achieves 78.1% precision and 55.2% success scores on OTB2015. Furthermore, ConST-CL achieves 94.8% and 71.9% top-1 fine-tuning accuracy on video action recognition datasets, UCF101 and HMDB51 respectively. We plan to release our code and models to the public.
Exploring Temporal Granularity in Self-Supervised Video Representation Learning
Dec 08, 2021



This work presents a self-supervised learning framework named TeG to explore Temporal Granularity in learning video representations. In TeG, we sample a long clip from a video and a short clip that lies inside the long clip. We then extract their dense temporal embeddings. The training objective consists of two parts: a fine-grained temporal learning objective to maximize the similarity between corresponding temporal embeddings in the short clip and the long clip, and a persistent temporal learning objective to pull together global embeddings of the two clips. Our study reveals the impact of temporal granularity with three major findings. 1) Different video tasks may require features of different temporal granularities. 2) Intriguingly, some tasks that are widely considered to require temporal awareness can actually be well addressed by temporally persistent features. 3) The flexibility of TeG gives rise to state-of-the-art results on 8 video benchmarks, outperforming supervised pre-training in most cases.
Motion-aware Self-supervised Video Representation Learning via Foreground-background Merging
Sep 30, 2021



In light of the success of contrastive learning in the image domain, current self-supervised video representation learning methods usually employ contrastive loss to facilitate video representation learning. When naively pulling two augmented views of a video closer, the model however tends to learn the common static background as a shortcut but fails to capture the motion information, a phenomenon dubbed as background bias. This bias makes the model suffer from weak generalization ability, leading to worse performance on downstream tasks such as action recognition. To alleviate such bias, we propose Foreground-background Merging (FAME) to deliberately compose the foreground region of the selected video onto the background of others. Specifically, without any off-the-shelf detector, we extract the foreground and background regions via the frame difference and color statistics, and shuffle the background regions among the videos. By leveraging the semantic consistency between the original clips and the fused ones, the model focuses more on the foreground motion pattern and is thus more robust to the background context. Extensive experiments demonstrate that FAME can significantly boost the performance in different downstream tasks with various backbones. When integrated with MoCo, FAME reaches 84.8% and 53.5% accuracy on UCF101 and HMDB51, respectively, achieving the state-of-the-art performance.
Revisiting 3D ResNets for Video Recognition
Sep 03, 2021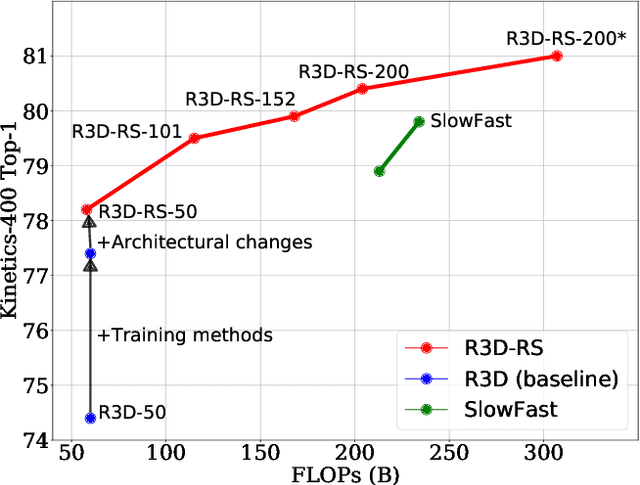
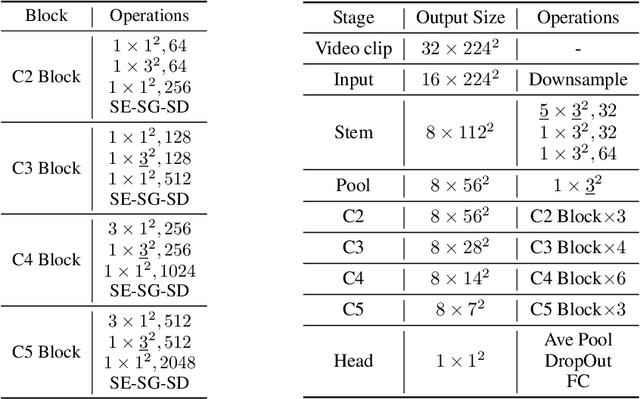
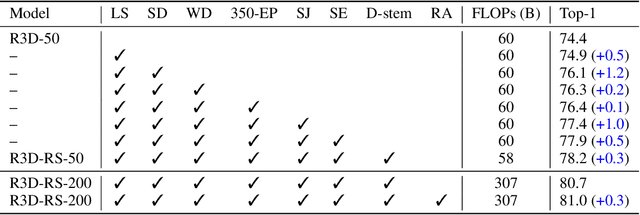
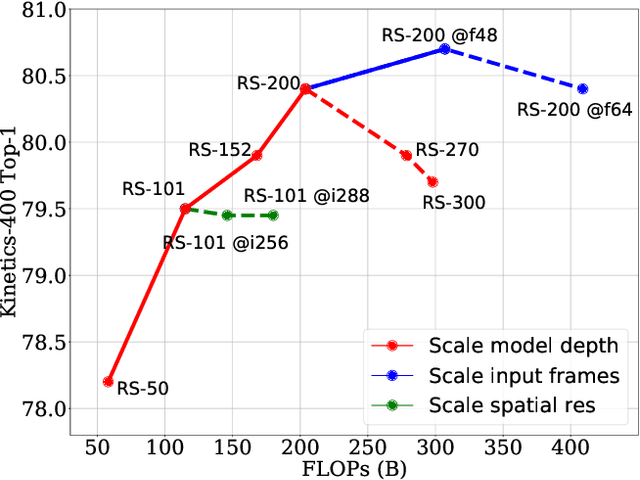
A recent work from Bello shows that training and scaling strategies may be more significant than model architectures for visual recognition. This short note studies effective training and scaling strategies for video recognition models. We propose a simple scaling strategy for 3D ResNets, in combination with improved training strategies and minor architectural changes. The resulting models, termed 3D ResNet-RS, attain competitive performance of 81.0 on Kinetics-400 and 83.8 on Kinetics-600 without pre-training. When pre-trained on a large Web Video Text dataset, our best model achieves 83.5 and 84.3 on Kinetics-400 and Kinetics-600. The proposed scaling rule is further evaluated in a self-supervised setup using contrastive learning, demonstrating improved performance. Code is available at: https://github.com/tensorflow/models/tree/master/official.
Enhancing Self-supervised Video Representation Learning via Multi-level Feature Optimization
Aug 17, 2021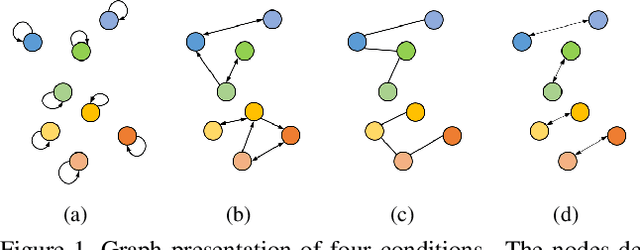
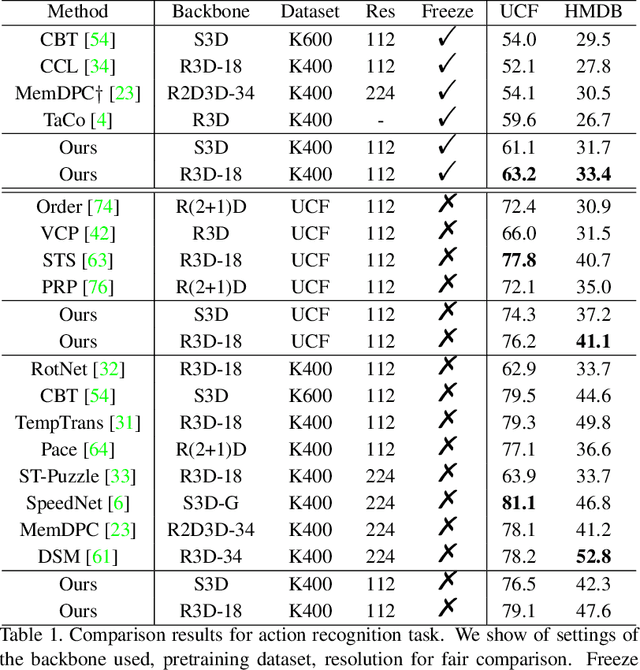
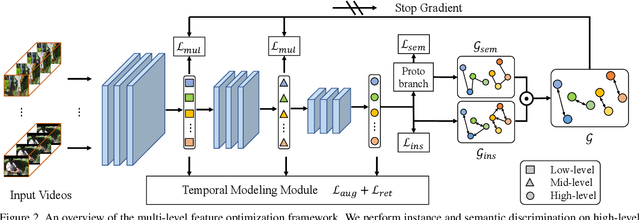
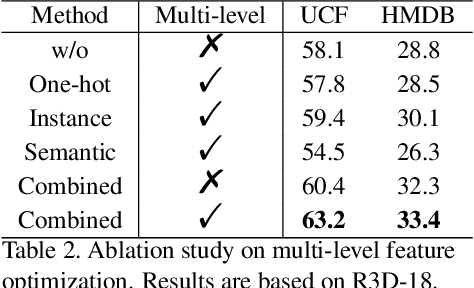
The crux of self-supervised video representation learning is to build general features from unlabeled videos. However, most recent works have mainly focused on high-level semantics and neglected lower-level representations and their temporal relationship which are crucial for general video understanding. To address these challenges, this paper proposes a multi-level feature optimization framework to improve the generalization and temporal modeling ability of learned video representations. Concretely, high-level features obtained from naive and prototypical contrastive learning are utilized to build distribution graphs, guiding the process of low-level and mid-level feature learning. We also devise a simple temporal modeling module from multi-level features to enhance motion pattern learning. Experiments demonstrate that multi-level feature optimization with the graph constraint and temporal modeling can greatly improve the representation ability in video understanding. Code is available at https://github.com/shvdiwnkozbw/Video-Representation-via-Multi-level-Optimization.