 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Supervised Contrastive Learning for Long-Tailed Recognition
Nov 27, 2021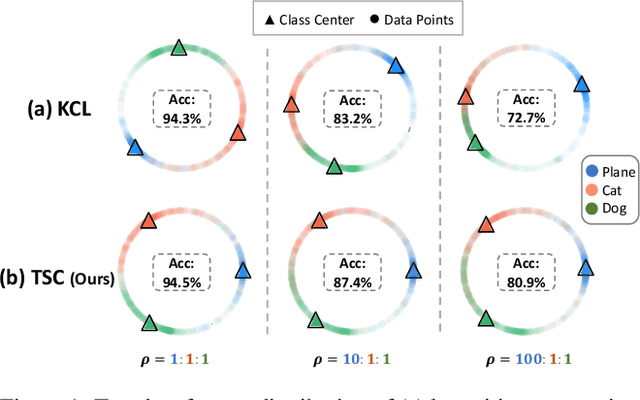
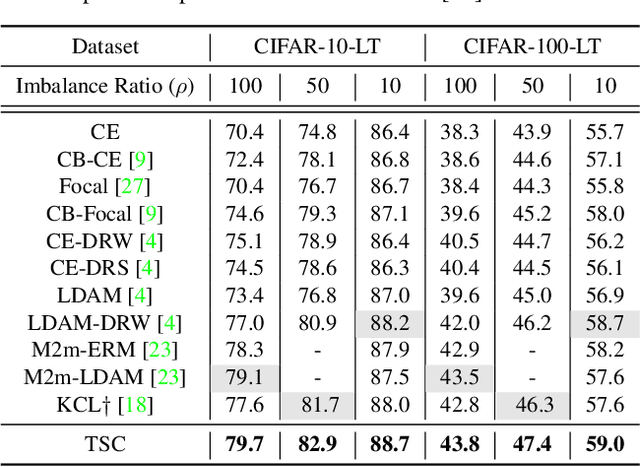
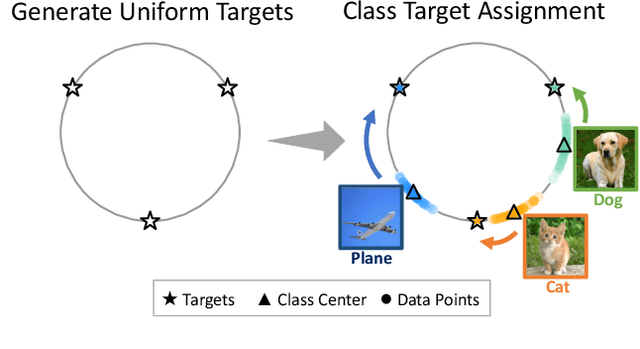
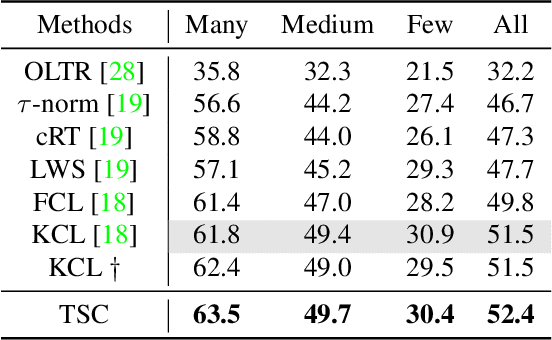
Real-world data often exhibits long tail distributions with heavy class imbalance, where the majority classes can dominate the training process and alter the decision boundaries of the minority classes. Recently, researchers have investigated the potential of supervised contrastive learning for long-tailed recognition, and demonstrated that it provides a strong performance gain. In this paper, we show that while supervised contrastive learning can help improve performance, past baselines suffer from poor uniformity brought in by imbalanced data distribution. This poor uniformity manifests in samples from the minority class having poor separability in the feature space. To address this problem, we propose targeted supervised contrastive learning (TSC), which improves the uniformity of the feature distribution on the hypersphere. TSC first generates a set of targets uniformly distributed on a hypersphere. It then makes the features of different classes converge to these distinct and uniformly distributed targets during training. This forces all classes, including minority classes, to maintain a uniform distribution in the feature space, improves class boundaries, and provides better generalization even in the presence of long-tail data. Experiments on multiple datasets show that TSC achieves state-of-the-art performance on long-tailed recognition tasks.
Cascaded Multilingual Audio-Visual Learning from Videos
Nov 08, 2021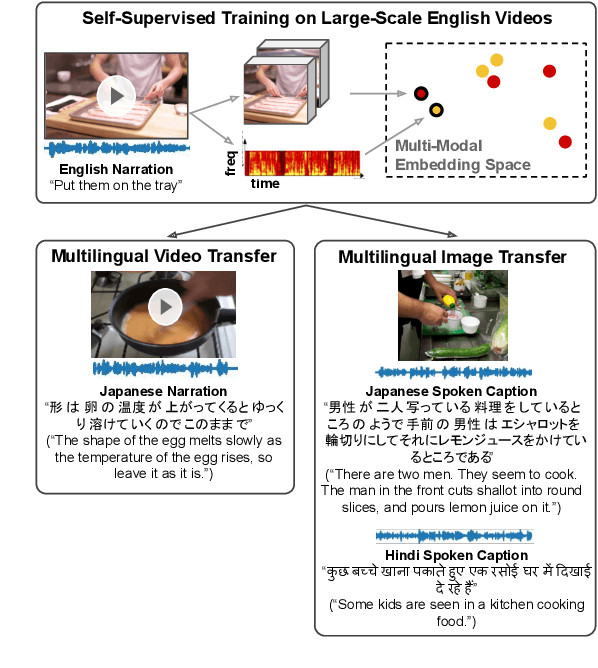
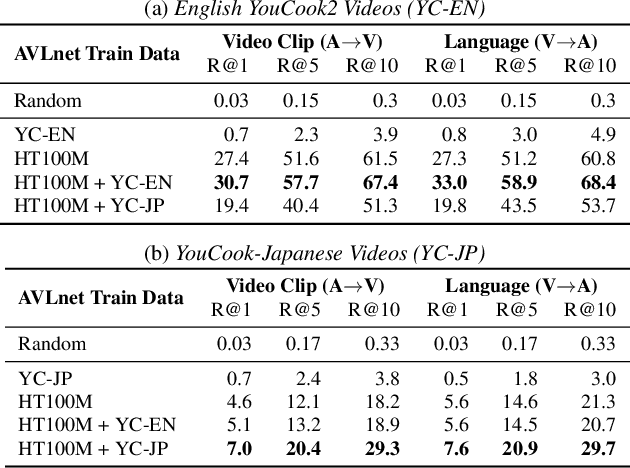

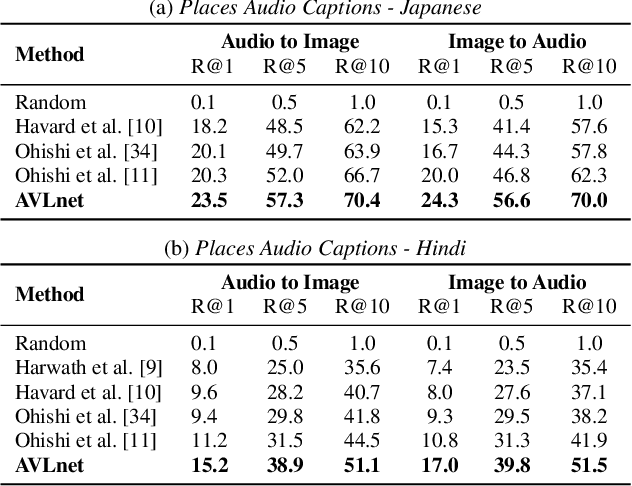
In this paper, we explore self-supervised audio-visual models that learn from instructional videos. Prior work has shown that these models can relate spoken words and sounds to visual content after training on a large-scale dataset of videos, but they were only trained and evaluated on videos in English. To learn multilingual audio-visual representations, we propose a cascaded approach that leverages a model trained on English videos and applies it to audio-visual data in other languages, such as Japanese videos. With our cascaded approach, we show an improvement in retrieval performance of nearly 10x compared to training on the Japanese videos solely. We also apply the model trained on English videos to Japanese and Hindi spoken captions of images, achieving state-of-the-art performance.
Dynamic Network Quantization for Efficient Video Inference
Aug 23, 2021
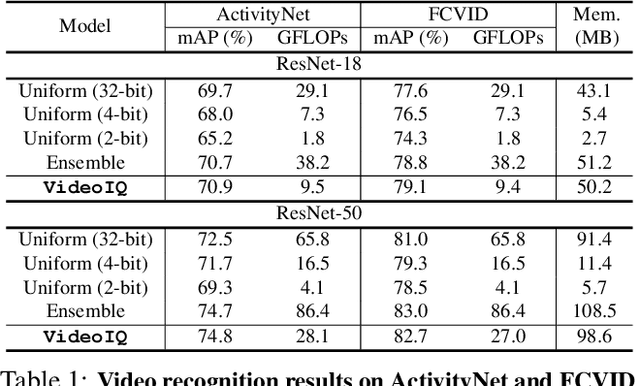
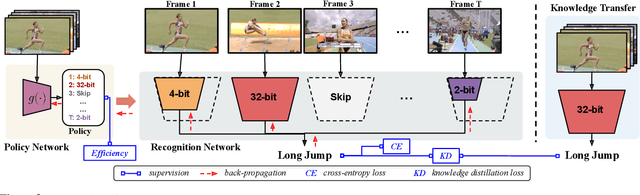
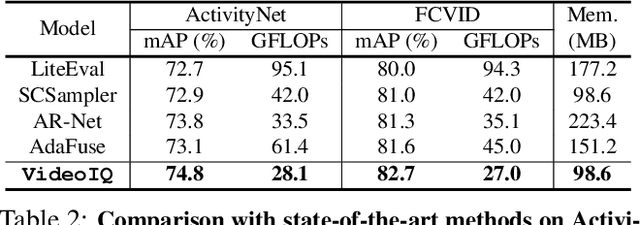
Deep convolutional networks have recently achieved great success in video recognition, yet their practical realization remains a challenge due to the large amount of computational resources required to achieve robust recognition. Motivated by the effectiveness of quantization for boosting efficiency, in this paper, we propose a dynamic network quantization framework, that selects optimal precision for each frame conditioned on the input for efficient video recognition. Specifically, given a video clip, we train a very lightweight network in parallel with the recognition network, to produce a dynamic policy indicating which numerical precision to be used per frame in recognizing videos. We train both networks effectively using standard backpropagation with a loss to achieve both competitive performance and resource efficiency required for video recognition. Extensive experiments on four challenging diverse benchmark datasets demonstrate that our proposed approach provides significant savings in computation and memory usage while outperforming the existing state-of-the-art methods.
Separating Skills and Concepts for Novel Visual Question Answering
Jul 19, 2021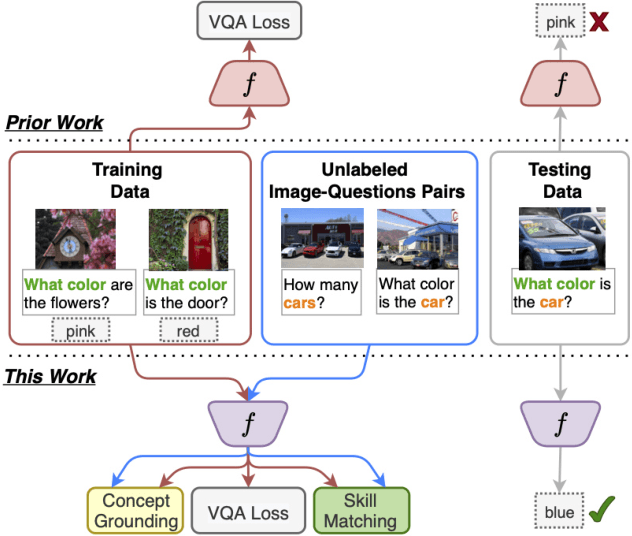
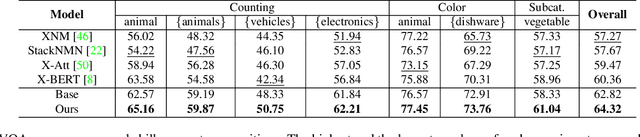
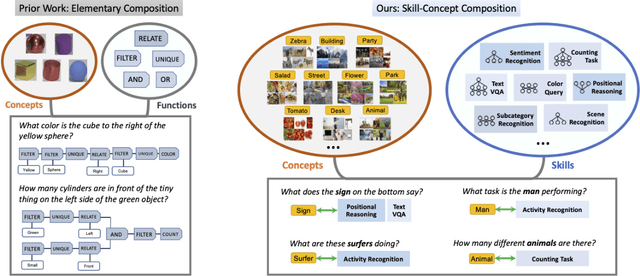
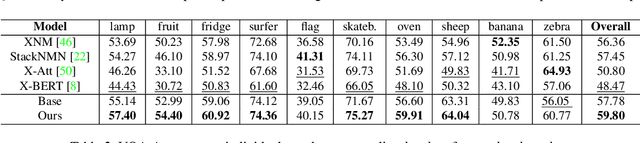
Generalization to out-of-distribution data has been a problem for Visual Question Answering (VQA) models. To measure generalization to novel questions, we propose to separate them into "skills" and "concepts". "Skills" are visual tasks, such as counting or attribute recognition, and are applied to "concepts" mentioned in the question, such as objects and people. VQA methods should be able to compose skills and concepts in novel ways, regardless of whether the specific composition has been seen in training, yet we demonstrate that existing models have much to improve upon towards handling new compositions. We present a novel method for learning to compose skills and concepts that separates these two factors implicitly within a model by learning grounded concept representations and disentangling the encoding of skills from that of concepts. We enforce these properties with a novel contrastive learning procedure that does not rely on external annotations and can be learned from unlabeled image-question pairs. Experiments demonstrate the effectiveness of our approach for improving compositional and grounding performance.
IA-RED$^2$: Interpretability-Aware Redundancy Reduction for Vision Transformers
Jun 23, 2021
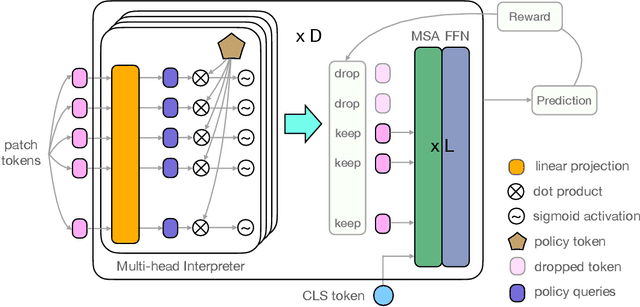
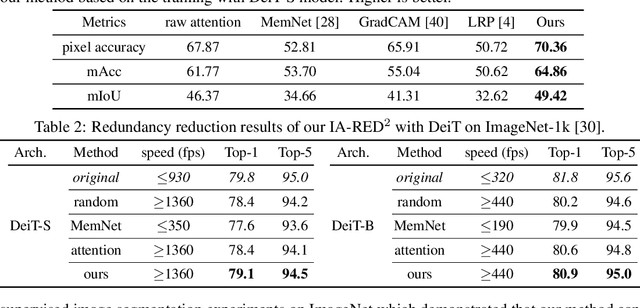
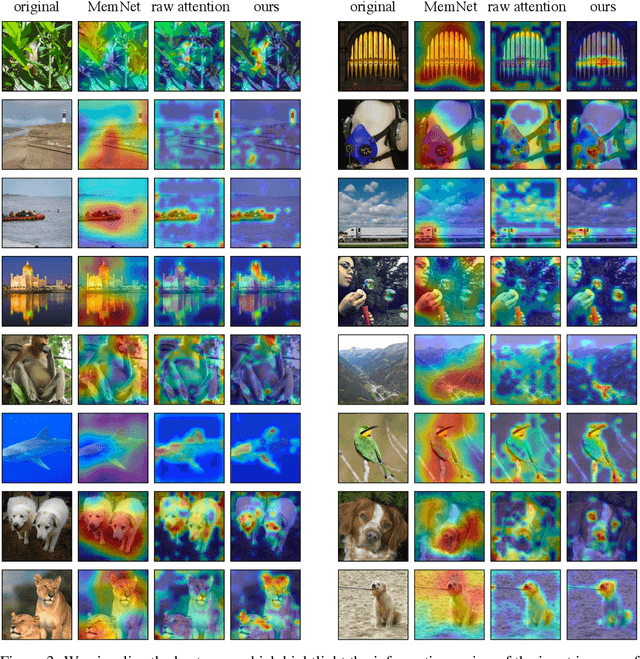
The self-attention-based model, transformer, is recently becoming the leading backbone in the field of computer vision. In spite of the impressive success made by transformers in a variety of vision tasks, it still suffers from heavy computation and intensive memory cost. To address this limitation, this paper presents an Interpretability-Aware REDundancy REDuction framework (IA-RED$^2$). We start by observing a large amount of redundant computation, mainly spent on uncorrelated input patches, and then introduce an interpretable module to dynamically and gracefully drop these redundant patches. This novel framework is then extended to a hierarchical structure, where uncorrelated tokens at different stages are gradually removed, resulting in a considerable shrinkage of computational cost. We include extensive experiments on both image and video tasks, where our method could deliver up to 1.4X speed-up for state-of-the-art models like DeiT and TimeSformer, by only sacrificing less than 0.7% accuracy. More importantly, contrary to other acceleration approaches, our method is inherently interpretable with substantial visual evidence, making vision transformer closer to a more human-understandable architecture while being lighter. We demonstrate that the interpretability that naturally emerged in our framework can outperform the raw attention learned by the original visual transformer, as well as those generated by off-the-shelf interpretation methods, with both qualitative and quantitative results. Project Page: http://people.csail.mit.edu/bpan/ia-red/.
Dynamic Distillation Network for Cross-Domain Few-Shot Recognition with Unlabeled Data
Jun 14, 2021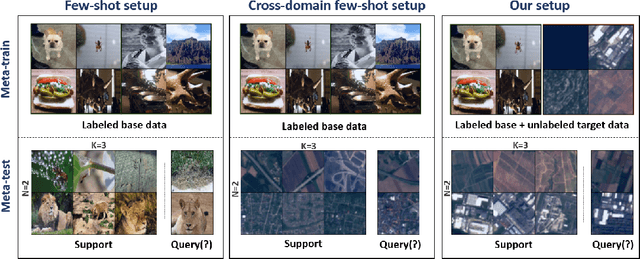
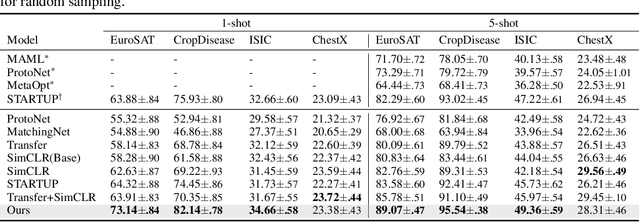
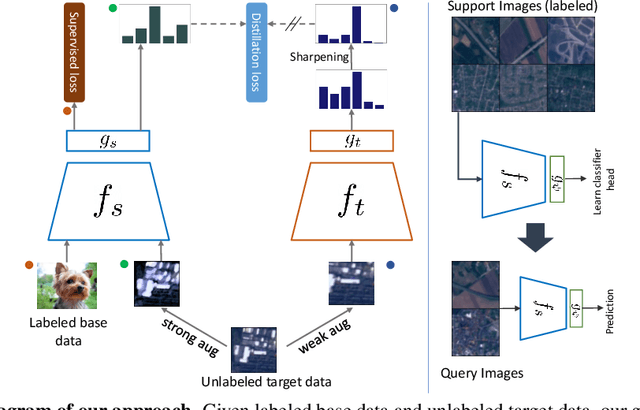

Most existing works in few-shot learning rely on meta-learning the network on a large base dataset which is typically from the same domain as the target dataset. We tackle the problem of cross-domain few-shot learning where there is a large shift between the base and target domain. The problem of cross-domain few-shot recognition with unlabeled target data is largely unaddressed in the literature. STARTUP was the first method that tackles this problem using self-training. However, it uses a fixed teacher pretrained on a labeled base dataset to create soft labels for the unlabeled target samples. As the base dataset and unlabeled dataset are from different domains, projecting the target images in the class-domain of the base dataset with a fixed pretrained model might be sub-optimal. We propose a simple dynamic distillation-based approach to facilitate unlabeled images from the novel/base dataset. We impose consistency regularization by calculating predictions from the weakly-augmented versions of the unlabeled images from a teacher network and matching it with the strongly augmented versions of the same images from a student network. The parameters of the teacher network are updated as exponential moving average of the parameters of the student network. We show that the proposed network learns representation that can be easily adapted to the target domain even though it has not been trained with target-specific classes during the pretraining phase. Our model outperforms the current state-of-the art method by 4.4% for 1-shot and 3.6% for 5-shot classification in the BSCD-FSL benchmark, and also shows competitive performance on traditional in-domain few-shot learning task. Our code will be available at: https://github.com/asrafulashiq/dynamic-cdfsl.
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition
May 12, 2021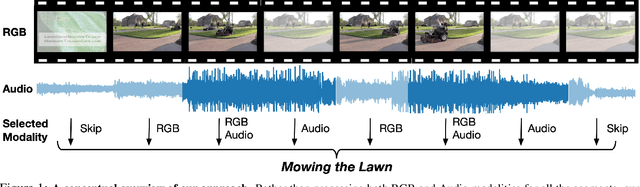
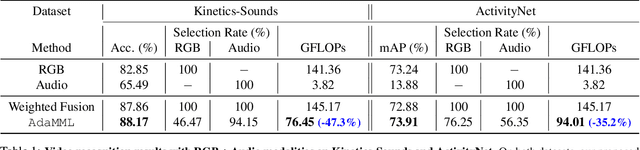
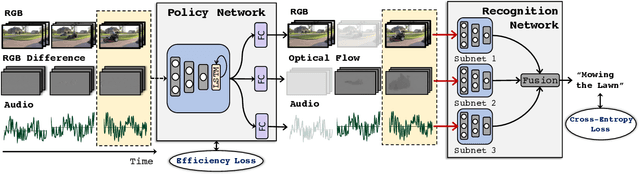
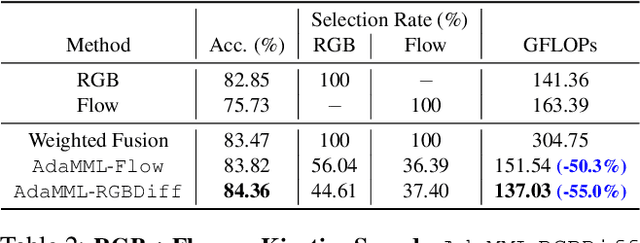
Multi-modal learning, which focuses on utilizing various modalities to improve the performance of a model, is widely used in video recognition. While traditional multi-modal learning offers excellent recognition results, its computational expense limits its impact for many real-world applications. In this paper, we propose an adaptive multi-modal learning framework, called AdaMML, that selects on-the-fly the optimal modalities for each segment conditioned on the input for efficient video recognition. Specifically, given a video segment, a multi-modal policy network is used to decide what modalities should be used for processing by the recognition model, with the goal of improving both accuracy and efficiency. We efficiently train the policy network jointly with the recognition model using standard back-propagation. Extensive experiments on four challenging diverse datasets demonstrate that our proposed adaptive approach yields 35%-55% reduction in computation when compared to the traditional baseline that simply uses all the modalities irrespective of the input, while also achieving consistent improvements in accuracy over the state-of-the-art methods.
Spoken Moments: Learning Joint Audio-Visual Representations from Video Descriptions
May 10, 2021

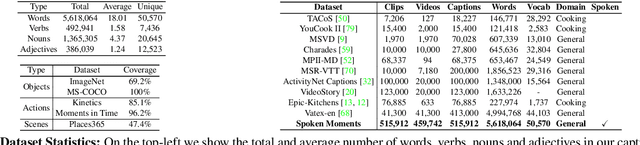
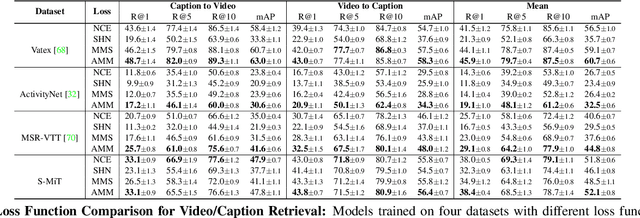
When people observe events, they are able to abstract key information and build concise summaries of what is happening. These summaries include contextual and semantic information describing the important high-level details (what, where, who and how) of the observed event and exclude background information that is deemed unimportant to the observer. With this in mind, the descriptions people generate for videos of different dynamic events can greatly improve our understanding of the key information of interest in each video. These descriptions can be captured in captions that provide expanded attributes for video labeling (e.g. actions/objects/scenes/sentiment/etc.) while allowing us to gain new insight into what people find important or necessary to summarize specific events. Existing caption datasets for video understanding are either small in scale or restricted to a specific domain. To address this, we present the Spoken Moments (S-MiT) dataset of 500k spoken captions each attributed to a unique short video depicting a broad range of different events. We collect our descriptions using audio recordings to ensure that they remain as natural and concise as possible while allowing us to scale the size of a large classification dataset. In order to utilize our proposed dataset, we present a novel Adaptive Mean Margin (AMM) approach to contrastive learning and evaluate our models on video/caption retrieval on multiple datasets. We show that our AMM approach consistently improves our results and that models trained on our Spoken Moments dataset generalize better than those trained on other video-caption datasets.
Multimodal Clustering Networks for Self-supervised Learning from Unlabeled Videos
May 05, 2021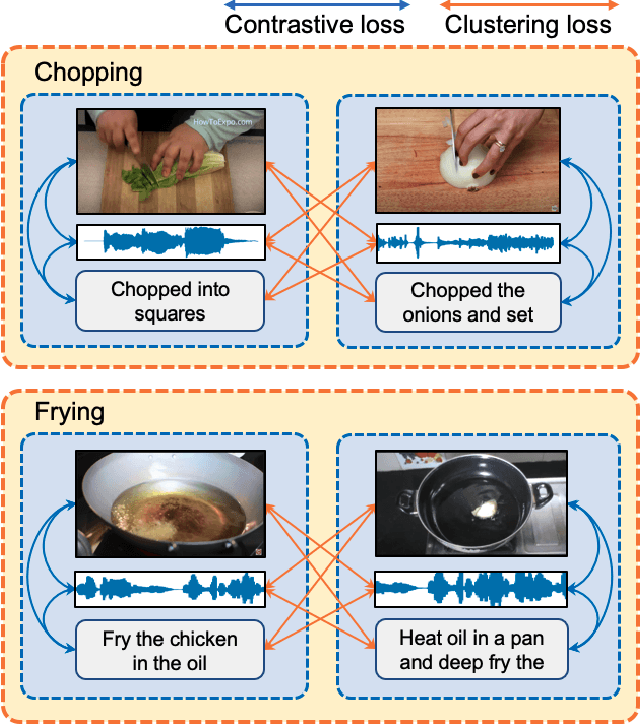
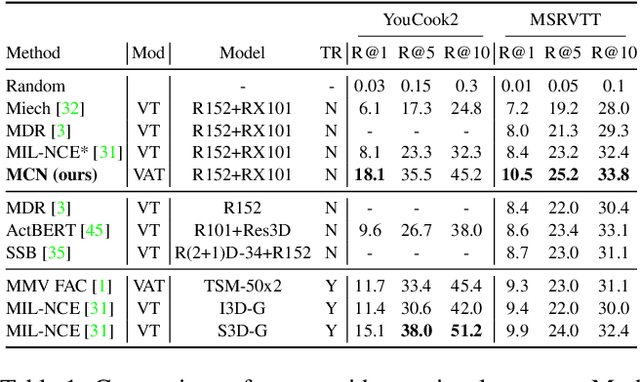
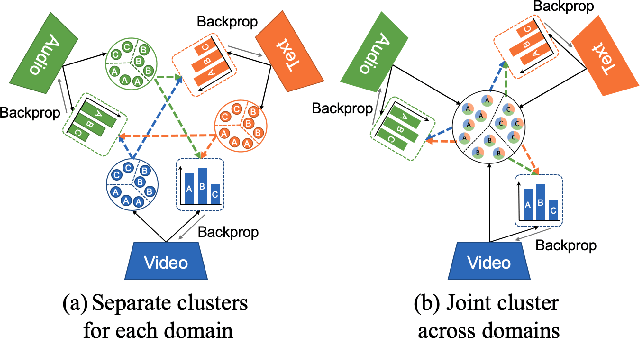
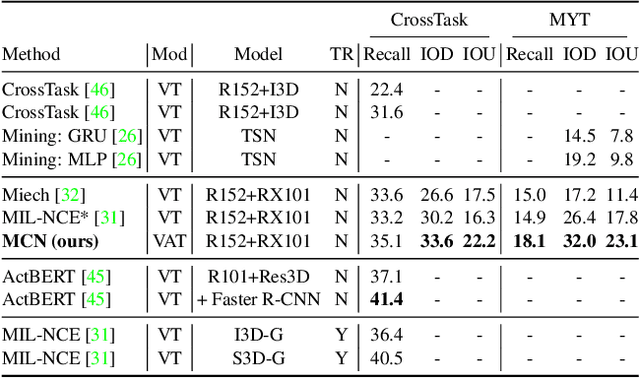
Multimodal self-supervised learning is getting more and more attention as it allows not only to train large networks without human supervision but also to search and retrieve data across various modalities. In this context, this paper proposes a self-supervised training framework that learns a common multimodal embedding space that, in addition to sharing representations across different modalities, enforces a grouping of semantically similar instances. To this end, we extend the concept of instance-level contrastive learning with a multimodal clustering step in the training pipeline to capture semantic similarities across modalities. The resulting embedding space enables retrieval of samples across all modalities, even from unseen datasets and different domains. To evaluate our approach, we train our model on the HowTo100M dataset and evaluate its zero-shot retrieval capabilities in two challenging domains, namely text-to-video retrieval, and temporal action localization, showing state-of-the-art results on four different datasets.
Pseudo-IoU: Improving Label Assignment in Anchor-Free Object Detection
Apr 29, 2021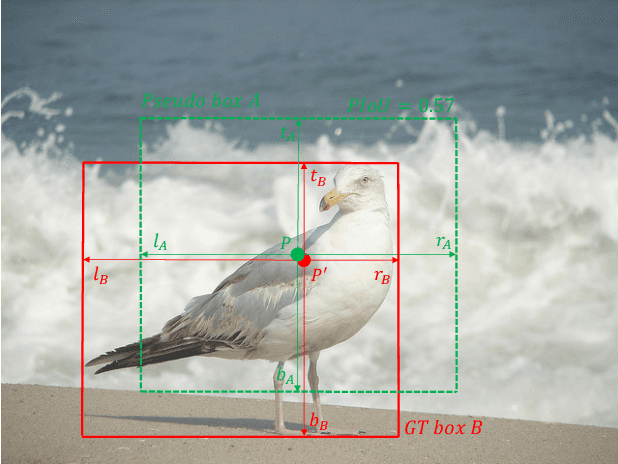
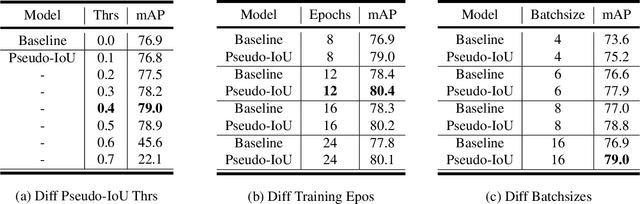
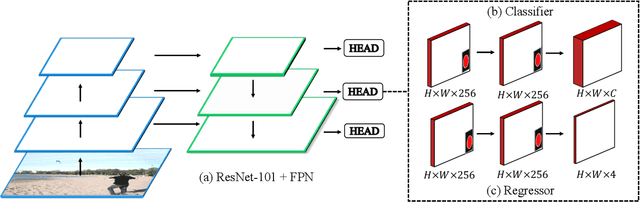
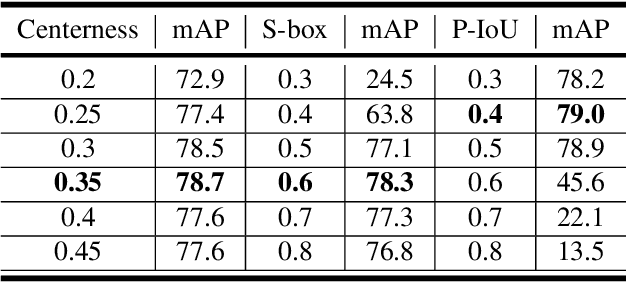
Current anchor-free object detectors are quite simple and effective yet lack accurate label assignment methods, which limits their potential in competing with classic anchor-based models that are supported by well-designed assignment methods based on the Intersection-over-Union~(IoU) metric. In this paper, we present \textbf{Pseudo-Intersection-over-Union~(Pseudo-IoU)}: a simple metric that brings more standardized and accurate assignment rule into anchor-free object detection frameworks without any additional computational cost or extra parameters for training and testing, making it possible to further improve anchor-free object detection by utilizing training samples of good quality under effective assignment rules that have been previously applied in anchor-based methods. By incorporating Pseudo-IoU metric into an end-to-end single-stage anchor-free object detection framework, we observe consistent improvements in their performance on general object detection benchmarks such as PASCAL VOC and MSCOCO. Our method (single-model and single-scale) also achieves comparable performance to other recent state-of-the-art anchor-free methods without bells and whistles. Our code is based on mmdetection toolbox and will be made publicly available at https://github.com/SHI-Labs/Pseudo-IoU-for-Anchor-Free-Object-Detection.