 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Relationship from 1-to-N into N 1-to-1 for Text-Video Retrieval
Oct 09, 2024



Text-video retrieval (TVR) has seen substantial advancements in recent years, fueled by the utilization of pre-trained models and large language models (LLMs). Despite these advancements, achieving accurate matching in TVR remains challenging due to inherent disparities between video and textual modalities and irregularities in data representation. In this paper, we propose Text-Video-ProxyNet (TV-ProxyNet), a novel framework designed to decompose the conventional 1-to-N relationship of TVR into N distinct 1-to-1 relationships. By replacing a single text query with a series of text proxies, TV-ProxyNet not only broadens the query scope but also achieves a more precise expansion. Each text proxy is crafted through a refined iterative process, controlled by mechanisms we term as the director and dash, which regulate the proxy's direction and distance relative to the original text query. This setup not only facilitates more precise semantic alignment but also effectively manages the disparities and noise inherent in multimodal data. Our experiments on three representative video-text retrieval benchmarks, MSRVTT, DiDeMo, and ActivityNet Captions, demonstrate the effectiveness of TV-ProxyNet. The results show an improvement of 2.0% to 3.3% in R@1 over the baseline. TV-ProxyNet achieved state-of-the-art performance on MSRVTT and ActivityNet Captions, and a 2.0% improvement on DiDeMo compared to existing methods, validating our approach's ability to enhance semantic mapping and reduce error propensity.
Towards Unified Multimodal Editing with Enhanced Knowledge Collaboration
Sep 30, 2024



The swift advancement in Multimodal LLMs (MLLMs) also presents significant challenges for effective knowledge editing. Current methods, including intrinsic knowledge editing and external knowledge resorting, each possess strengths and weaknesses, struggling to balance the desired properties of reliability, generality, and locality when applied to MLLMs. In this paper, we propose UniKE, a novel multimodal editing method that establishes a unified perspective and paradigm for intrinsic knowledge editing and external knowledge resorting. Both types of knowledge are conceptualized as vectorized key-value memories, with the corresponding editing processes resembling the assimilation and accommodation phases of human cognition, conducted at the same semantic levels. Within such a unified framework, we further promote knowledge collaboration by disentangling the knowledge representations into the semantic and truthfulness spaces. Extensive experiments validate the effectiveness of our method, which ensures that the post-edit MLLM simultaneously maintains excellent reliability, generality, and locality. The code for UniKE will be available at \url{https://github.com/beepkh/UniKE}.
UniLearn: Enhancing Dynamic Facial Expression Recognition through Unified Pre-Training and Fine-Tuning on Images and Videos
Sep 10, 2024



Dynamic facial expression recognition (DFER) is essential for understanding human emotions and behavior. However, conventional DFER methods, which primarily use dynamic facial data, often underutilize static expression images and their labels, limiting their performance and robustness. To overcome this, we introduce UniLearn, a novel unified learning paradigm that integrates static facial expression recognition (SFER) data to enhance DFER task. UniLearn employs a dual-modal self-supervised pre-training method, leveraging both facial expression images and videos to enhance a ViT model's spatiotemporal representation capability. Then, the pre-trained model is fine-tuned on both static and dynamic expression datasets using a joint fine-tuning strategy. To prevent negative transfer during joint fine-tuning, we introduce an innovative Mixture of Adapter Experts (MoAE) module that enables task-specific knowledge acquisition and effectively integrates information from both static and dynamic expression data. Extensive experiments demonstrate UniLearn's effectiveness in leveraging complementary information from static and dynamic facial data, leading to more accurate and robust DFER. UniLearn consistently achieves state-of-the-art performance on FERV39K, MAFW, and DFEW benchmarks, with weighted average recall (WAR) of 53.65\%, 58.44\%, and 76.68\%, respectively. The source code and model weights will be publicly available at \url{https://github.com/MSA-LMC/UniLearn}.
Seeing is Believing? Enhancing Vision-Language Navigation using Visual Perturbations
Sep 09, 2024



Autonomous navigation for an embodied agent guided by natural language instructions remains a formidable challenge in vision-and-language navigation (VLN). Despite remarkable recent progress in learning fine-grained and multifarious visual representations, the tendency to overfit to the training environments leads to unsatisfactory generalization performance. In this work, we present a versatile Multi-Branch Architecture (MBA) aimed at exploring and exploiting diverse visual inputs. Specifically, we introduce three distinct visual variants: ground-truth depth images, visual inputs integrated with incongruent views, and those infused with random noise to enrich the diversity of visual input representation and prevent overfitting to the original RGB observations. To adaptively fuse these varied inputs, the proposed MBA extend a base agent model into a multi-branch variant, where each branch processes a different visual input. Surprisingly, even random noise can further enhance navigation performance in unseen environments. Extensive experiments conducted on three VLN benchmarks (R2R, REVERIE, SOON) demonstrate that our proposed method equals or even surpasses state-of-the-art results. The source code will be publicly available.
SDI-Net: Toward Sufficient Dual-View Interaction for Low-light Stereo Image Enhancement
Aug 20, 2024



Currently, most low-light image enhancement methods only consider information from a single view, neglecting the correlation between cross-view information. Therefore, the enhancement results produced by these methods are often unsatisfactory. In this context, there have been efforts to develop methods specifically for low-light stereo image enhancement. These methods take into account the cross-view disparities and enable interaction between the left and right views, leading to improved performance. However, these methods still do not fully exploit the interaction between left and right view information. To address this issue, we propose a model called Toward Sufficient Dual-View Interaction for Low-light Stereo Image Enhancement (SDI-Net). The backbone structure of SDI-Net is two encoder-decoder pairs, which are used to learn the mapping function from low-light images to normal-light images. Among the encoders and the decoders, we design a module named Cross-View Sufficient Interaction Module (CSIM), aiming to fully exploit the correlations between the binocular views via the attention mechanism. The quantitative and visual results on public datasets validate the superiority of our method over other related methods. Ablation studies also demonstrate the effectiveness of the key elements in our model.
Exploring Robust Face-Voice Matching in Multilingual Environments
Jul 29, 2024
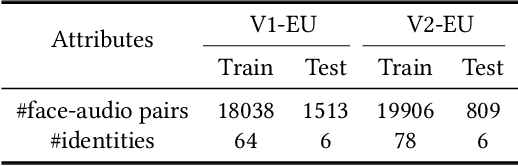
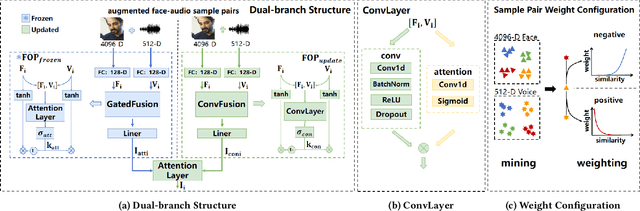

This paper presents Team Xaiofei's innovative approach to exploring Face-Voice Association in Multilingual Environments (FAME) at ACM Multimedia 2024. We focus on the impact of different languages in face-voice matching by building upon Fusion and Orthogonal Projection (FOP), introducing four key components: a dual-branch structure, dynamic sample pair weighting, robust data augmentation, and score polarization strategy. Our dual-branch structure serves as an auxiliary mechanism to better integrate and provide more comprehensive information. We also introduce a dynamic weighting mechanism for various sample pairs to optimize learning. Data augmentation techniques are employed to enhance the model's generalization across diverse conditions. Additionally, score polarization strategy based on age and gender matching confidence clarifies and accentuates the final results. Our methods demonstrate significant effectiveness, achieving an equal error rate (EER) of 20.07 on the V2-EH dataset and 21.76 on the V1-EU dataset.
Graph Bottlenecked Social Recommendation
Jun 12, 2024



With the emergence of social networks, social recommendation has become an essential technique for personalized services. Recently, graph-based social recommendations have shown promising results by capturing the high-order social influence. Most empirical studies of graph-based social recommendations directly take the observed social networks into formulation, and produce user preferences based on social homogeneity. Despite the effectiveness, we argue that social networks in the real-world are inevitably noisy~(existing redundant social relations), which may obstruct precise user preference characterization. Nevertheless, identifying and removing redundant social relations is challenging due to a lack of labels. In this paper, we focus on learning the denoised social structure to facilitate recommendation tasks from an information bottleneck perspective. Specifically, we propose a novel Graph Bottlenecked Social Recommendation (GBSR) framework to tackle the social noise issue.GBSR is a model-agnostic social denoising framework, that aims to maximize the mutual information between the denoised social graph and recommendation labels, meanwhile minimizing it between the denoised social graph and the original one. This enables GBSR to learn the minimal yet sufficient social structure, effectively reducing redundant social relations and enhancing social recommendations. Technically, GBSR consists of two elaborate components, preference-guided social graph refinement, and HSIC-based bottleneck learning. Extensive experimental results demonstrate the superiority of the proposed GBSR, including high performances and good generality combined with various backbones. Our code is available at: https://github.com/yimutianyang/KDD24-GBSR.
Path-Specific Causal Reasoning for Fairness-aware Cognitive Diagnosis
Jun 05, 2024



Cognitive Diagnosis~(CD), which leverages students and exercise data to predict students' proficiency levels on different knowledge concepts, is one of fundamental components in Intelligent Education. Due to the scarcity of student-exercise interaction data, most existing methods focus on making the best use of available data, such as exercise content and student information~(e.g., educational context). Despite the great progress, the abuse of student sensitive information has not been paid enough attention. Due to the important position of CD in Intelligent Education, employing sensitive information when making diagnosis predictions will cause serious social issues. Moreover, data-driven neural networks are easily misled by the shortcut between input data and output prediction, exacerbating this problem. Therefore, it is crucial to eliminate the negative impact of sensitive information in CD models. In response, we argue that sensitive attributes of students can also provide useful information, and only the shortcuts directly related to the sensitive information should be eliminated from the diagnosis process. Thus, we employ causal reasoning and design a novel Path-Specific Causal Reasoning Framework (PSCRF) to achieve this goal. Specifically, we first leverage an encoder to extract features and generate embeddings for general information and sensitive information of students. Then, we design a novel attribute-oriented predictor to decouple the sensitive attributes, in which fairness-related sensitive features will be eliminated and other useful information will be retained. Finally, we designed a multi-factor constraint to ensure the performance of fairness and diagnosis performance simultaneously. Extensive experiments over real-world datasets (e.g., PISA dataset) demonstrate the effectiveness of our proposed PSCRF.
Double Correction Framework for Denoising Recommendation
May 18, 2024



As its availability and generality in online services, implicit feedback is more commonly used in recommender systems. However, implicit feedback usually presents noisy samples in real-world recommendation scenarios (such as misclicks or non-preferential behaviors), which will affect precise user preference learning. To overcome the noisy samples problem, a popular solution is based on dropping noisy samples in the model training phase, which follows the observation that noisy samples have higher training losses than clean samples. Despite the effectiveness, we argue that this solution still has limits. (1) High training losses can result from model optimization instability or hard samples, not just noisy samples. (2) Completely dropping of noisy samples will aggravate the data sparsity, which lacks full data exploitation. To tackle the above limitations, we propose a Double Correction Framework for Denoising Recommendation (DCF), which contains two correction components from views of more precise sample dropping and avoiding more sparse data. In the sample dropping correction component, we use the loss value of the samples over time to determine whether it is noise or not, increasing dropping stability. Instead of averaging directly, we use the damping function to reduce the bias effect of outliers. Furthermore, due to the higher variance exhibited by hard samples, we derive a lower bound for the loss through concentration inequality to identify and reuse hard samples. In progressive label correction, we iteratively re-label highly deterministic noisy samples and retrain them to further improve performance. Finally, extensive experimental results on three datasets and four backbones demonstrate the effectiveness and generalization of our proposed framework.
Controllable Relation Disentanglement for Few-Shot Class-Incremental Learning
Mar 17, 2024



In this paper, we propose to tackle Few-Shot Class-Incremental Learning (FSCIL) from a new perspective, i.e., relation disentanglement, which means enhancing FSCIL via disentangling spurious relation between categories. The challenge of disentangling spurious correlations lies in the poor controllability of FSCIL. On one hand, an FSCIL model is required to be trained in an incremental manner and thus it is very hard to directly control relationships between categories of different sessions. On the other hand, training samples per novel category are only in the few-shot setting, which increases the difficulty of alleviating spurious relation issues as well. To overcome this challenge, in this paper, we propose a new simple-yet-effective method, called ConTrollable Relation-disentangLed Few-Shot Class-Incremental Learning (CTRL-FSCIL). Specifically, during the base session, we propose to anchor base category embeddings in feature space and construct disentanglement proxies to bridge gaps between the learning for category representations in different sessions, thereby making category relation controllable. During incremental learning, the parameters of the backbone network are frozen in order to relieve the negative impact of data scarcity. Moreover, a disentanglement loss is designed to effectively guide a relation disentanglement controller to disentangle spurious correlations between the embeddings encoded by the backbone. In this way, the spurious correlation issue in FSCIL can be suppressed. Extensive experiments on CIFAR-100, mini-ImageNet, and CUB-200 datasets demonstrate the effectiveness of our CTRL-FSCIL method.