 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-KAST: Top-K Always Sparse Training
Jun 07, 2021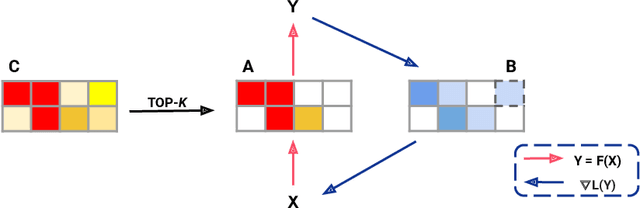
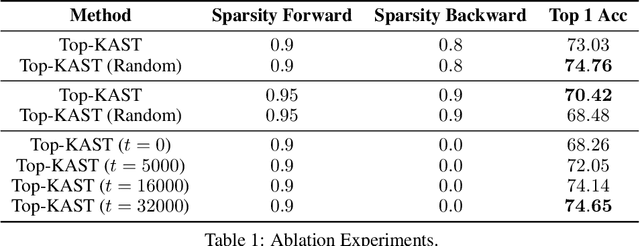
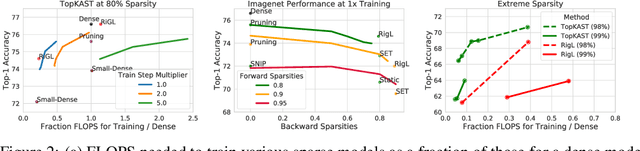
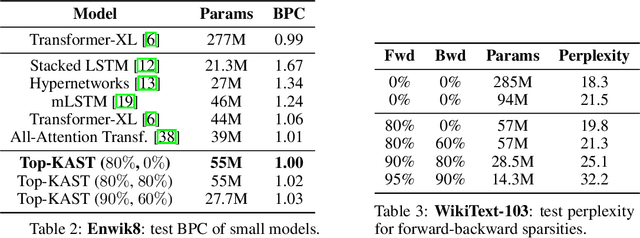
Sparse neural networks are becoming increasingly important as the field seeks to improve the performance of existing models by scaling them up, while simultaneously trying to reduce power consumption and computational footprint. Unfortunately, most existing methods for inducing performant sparse models still entail the instantiation of dense parameters, or dense gradients in the backward-pass, during training. For very large models this requirement can be prohibitive. In this work we propose Top-KAST, a method that preserves constant sparsity throughout training (in both the forward and backward-passes). We demonstrate the efficacy of our approach by showing that it performs comparably to or better than previous works when training models on the established ImageNet benchmark, whilst fully maintaining sparsity. In addition to our ImageNet results, we also demonstrate our approach in the domain of language modeling where the current best performing architectures tend to have tens of billions of parameters and scaling up does not yet seem to have saturated performance. Sparse versions of these architectures can be run with significantly fewer resources, making them more widely accessible and applicable. Furthermore, in addition to being effective, our approach is straightforward and can easily be implemented in a wide range of existing machine learning frameworks with only a few additional lines of code. We therefore hope that our contribution will help enable the broader community to explore the potential held by massive models, without incurring massive computational cost.
A study on the plasticity of neural networks
May 31, 2021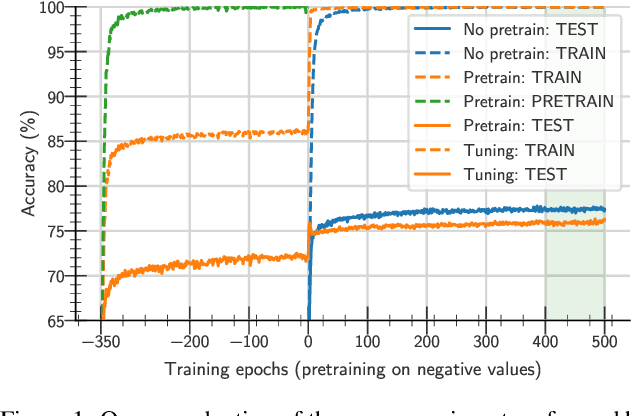
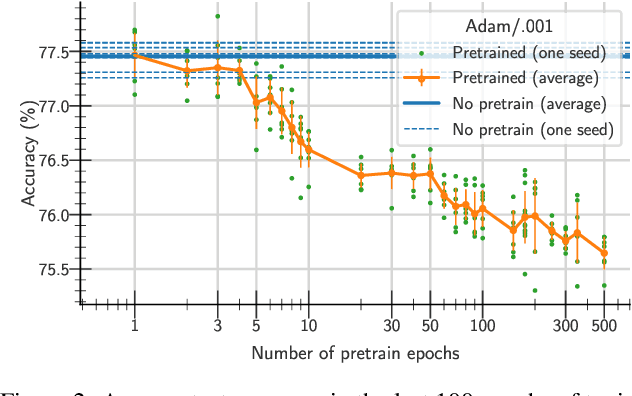
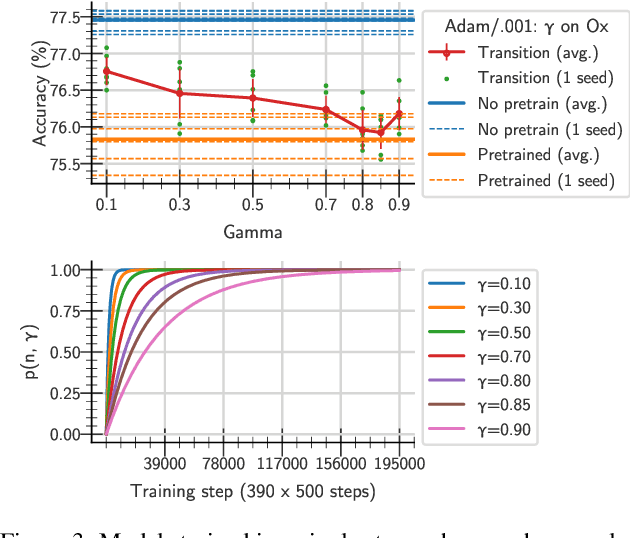
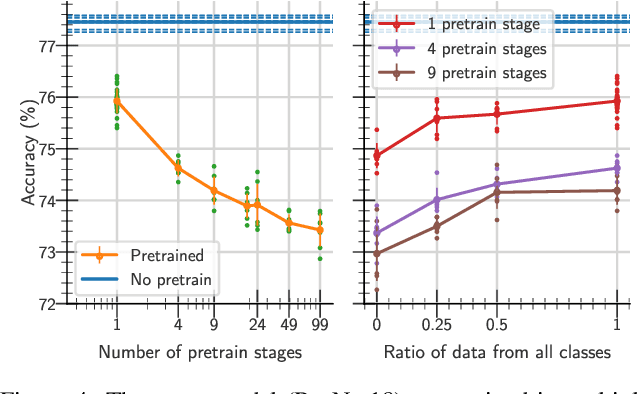
One aim shared by multiple settings, such as continual learning or transfer learning, is to leverage previously acquired knowledge to converge faster on the current task. Usually this is done through fine-tuning, where an implicit assumption is that the network maintains its plasticity, meaning that the performance it can reach on any given task is not affected negatively by previously seen tasks. It has been observed recently that a pretrained model on data from the same distribution as the one it is fine-tuned on might not reach the same generalisation as a freshly initialised one. We build and extend this observation, providing a hypothesis for the mechanics behind it. We discuss the implication of losing plasticity for continual learning which heavily relies on optimising pretrained models.
Drawing Multiple Augmentation Samples Per Image During Training Efficiently Decreases Test Error
May 27, 2021

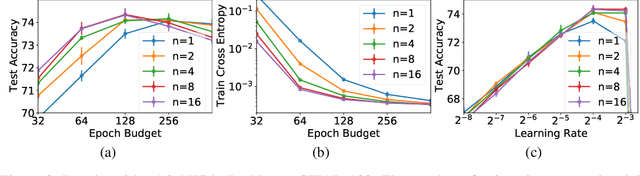

In computer vision, it is standard practice to draw a single sample from the data augmentation procedure for each unique image in the mini-batch, however it is not clear whether this choice is optimal for generalization. In this work, we provide a detailed empirical evaluation of how the number of augmentation samples per unique image influences performance on held out data. Remarkably, we find that drawing multiple samples per image consistently enhances the test accuracy achieved for both small and large batch training, despite reducing the number of unique training examples in each mini-batch. This benefit arises even when different augmentation multiplicities perform the same number of parameter updates and gradient evaluations. Our results suggest that, although the variance in the gradient estimate arising from subsampling the dataset has an implicit regularization benefit, the variance which arises from the data augmentation process harms test accuracy. By applying augmentation multiplicity to the recently proposed NFNet model family, we achieve a new ImageNet state of the art of 86.8$\%$ top-1 w/o extra data.
Continual World: A Robotic Benchmark For Continual Reinforcement Learning
May 23, 2021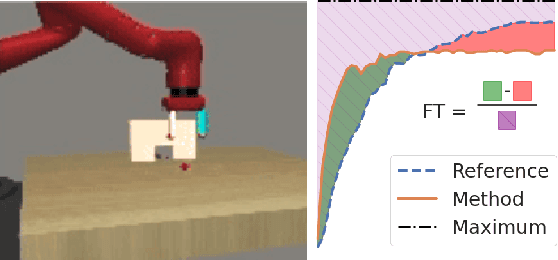
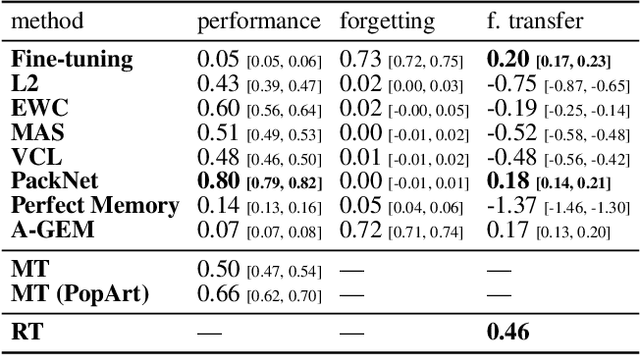
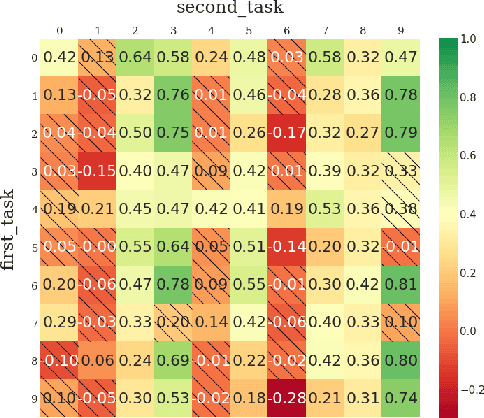

Continual learning (CL) -- the ability to continuously learn, building on previously acquired knowledge -- is a natural requirement for long-lived autonomous reinforcement learning (RL) agents. While building such agents, one needs to balance opposing desiderata, such as constraints on capacity and compute, the ability to not catastrophically forget, and to exhibit positive transfer on new tasks. Understanding the right trade-off is conceptually and computationally challenging, which we argue has led the community to overly focus on catastrophic forgetting. In response to these issues, we advocate for the need to prioritize forward transfer and propose Continual World, a benchmark consisting of realistic and meaningfully diverse robotic tasks built on top of Meta-World as a testbed. Following an in-depth empirical evaluation of existing CL methods, we pinpoint their limitations and highlight unique algorithmic challenges in the RL setting. Our benchmark aims to provide a meaningful and computationally inexpensive challenge for the community and thus help better understand the performance of existing and future solutions.
Spectral Normalisation for Deep Reinforcement Learning: an Optimisation Perspective
May 11, 2021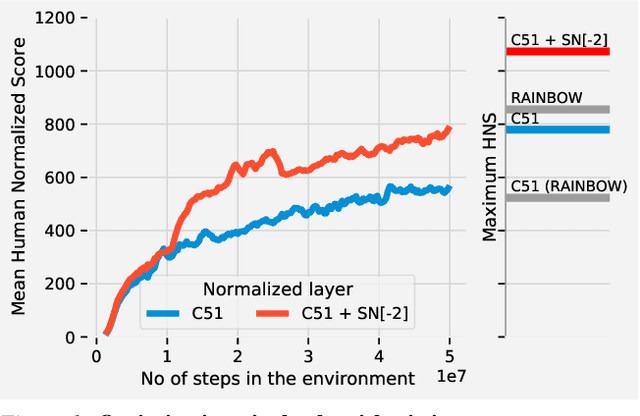
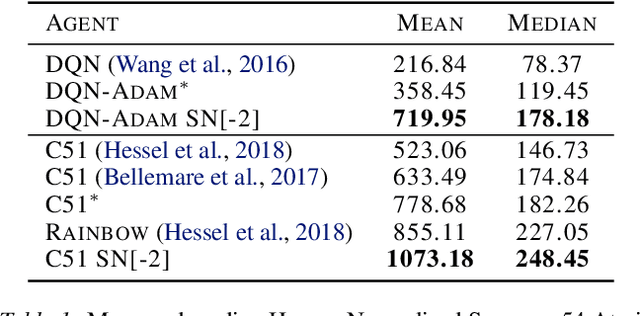
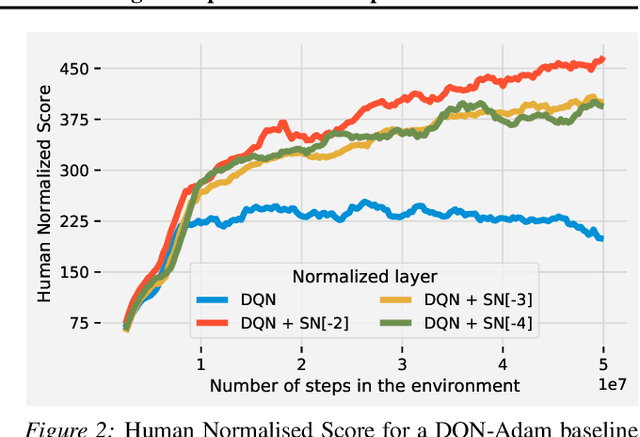

Most of the recent deep reinforcement learning advances take an RL-centric perspective and focus on refinements of the training objective. We diverge from this view and show we can recover the performance of these developments not by changing the objective, but by regularising the value-function estimator. Constraining the Lipschitz constant of a single layer using spectral normalisation is sufficient to elevate the performance of a Categorical-DQN agent to that of a more elaborated \rainbow{} agent on the challenging Atari domain. We conduct ablation studies to disentangle the various effects normalisation has on the learning dynamics and show that is sufficient to modulate the parameter updates to recover most of the performance of spectral normalisation. These findings hint towards the need to also focus on the neural component and its learning dynamics to tackle the peculiarities of Deep Reinforcement Learning.
Regularized Behavior Value Estimation
Mar 17, 2021
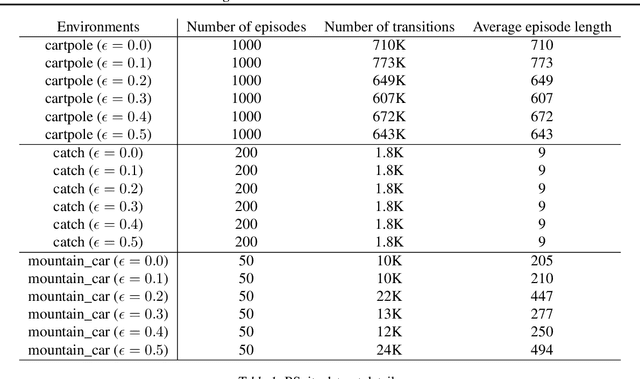
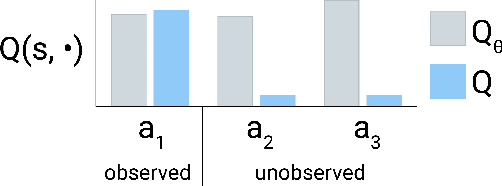
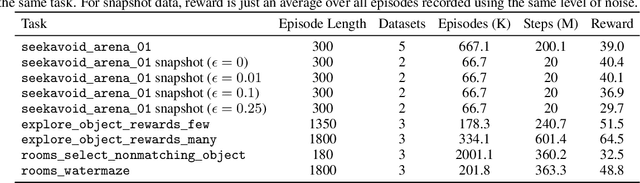
Offline reinforcement learning restricts the learning process to rely only on logged-data without access to an environment. While this enables real-world applications, it also poses unique challenges. One important challenge is dealing with errors caused by the overestimation of values for state-action pairs not well-covered by the training data. Due to bootstrapping, these errors get amplified during training and can lead to divergence, thereby crippling learning. To overcome this challenge, we introduce Regularized Behavior Value Estimation (R-BVE). Unlike most approaches, which use policy improvement during training, R-BVE estimates the value of the behavior policy during training and only performs policy improvement at deployment time. Further, R-BVE uses a ranking regularisation term that favours actions in the dataset that lead to successful outcomes. We provide ample empirical evidence of R-BVE's effectiveness, including state-of-the-art performance on the RL Unplugged ATARI dataset. We also test R-BVE on new datasets, from bsuite and a challenging DeepMind Lab task, and show that R-BVE outperforms other state-of-the-art discrete control offline RL methods.
Behavior Priors for Efficient Reinforcement Learning
Oct 27, 2020
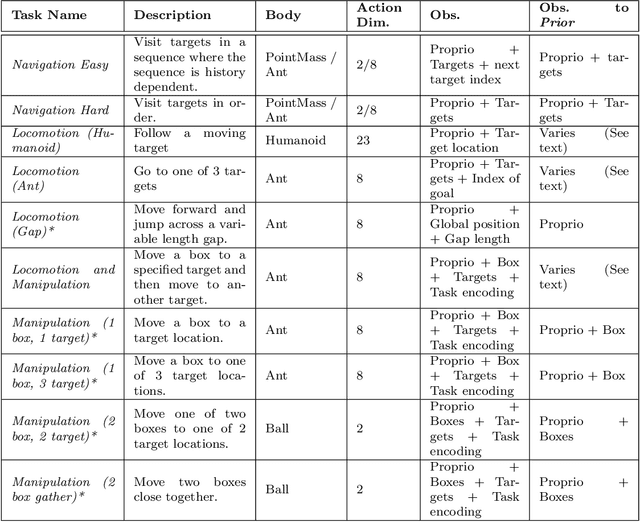
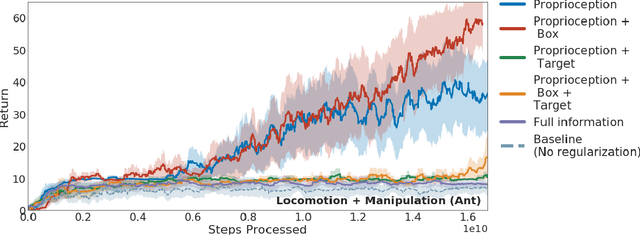

As we deploy reinforcement learning agents to solve increasingly challenging problems, methods that allow us to inject prior knowledge about the structure of the world and effective solution strategies becomes increasingly important. In this work we consider how information and architectural constraints can be combined with ideas from the probabilistic modeling literature to learn behavior priors that capture the common movement and interaction patterns that are shared across a set of related tasks or contexts. For example the day-to day behavior of humans comprises distinctive locomotion and manipulation patterns that recur across many different situations and goals. We discuss how such behavior patterns can be captured using probabilistic trajectory models and how these can be integrated effectively into reinforcement learning schemes, e.g.\ to facilitate multi-task and transfer learning. We then extend these ideas to latent variable models and consider a formulation to learn hierarchical priors that capture different aspects of the behavior in reusable modules. We discuss how such latent variable formulations connect to related work on hierarchical reinforcement learning (HRL) and mutual information and curiosity based objectives, thereby offering an alternative perspective on existing ideas. We demonstrate the effectiveness of our framework by applying it to a range of simulated continuous control domains.
BYOL works even without batch statistics
Oct 20, 2020

Bootstrap Your Own Latent (BYOL) is a self-supervised learning approach for image representation. From an augmented view of an image, BYOL trains an online network to predict a target network representation of a different augmented view of the same image. Unlike contrastive methods, BYOL does not explicitly use a repulsion term built from negative pairs in its training objective. Yet, it avoids collapse to a trivial, constant representation. Thus, it has recently been hypothesized that batch normalization (BN) is critical to prevent collapse in BYOL. Indeed, BN flows gradients across batch elements, and could leak information about negative views in the batch, which could act as an implicit negative (contrastive) term. However, we experimentally show that replacing BN with a batch-independent normalization scheme (namely, a combination of group normalization and weight standardization) achieves performance comparable to vanilla BYOL ($73.9\%$ vs. $74.3\%$ top-1 accuracy under the linear evaluation protocol on ImageNet with ResNet-$50$). Our finding disproves the hypothesis that the use of batch statistics is a crucial ingredient for BYOL to learn useful representations.
Linear Mode Connectivity in Multitask and Continual Learning
Oct 09, 2020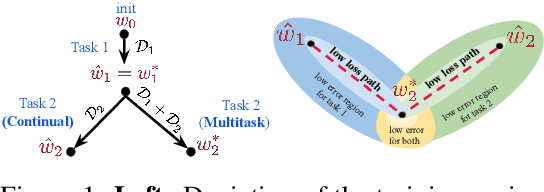
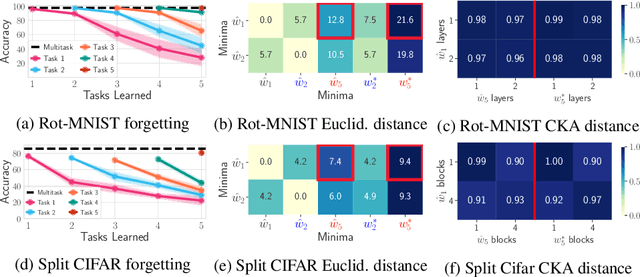


Continual (sequential) training and multitask (simultaneous) training are often attempting to solve the same overall objective: to find a solution that performs well on all considered tasks. The main difference is in the training regimes, where continual learning can only have access to one task at a time, which for neural networks typically leads to catastrophic forgetting. That is, the solution found for a subsequent task does not perform well on the previous ones anymore. However, the relationship between the different minima that the two training regimes arrive at is not well understood. What sets them apart? Is there a local structure that could explain the difference in performance achieved by the two different schemes? Motivated by recent work showing that different minima of the same task are typically connected by very simple curves of low error, we investigate whether multitask and continual solutions are similarly connected. We empirically find that indeed such connectivity can be reliably achieved and, more interestingly, it can be done by a linear path, conditioned on having the same initialization for both. We thoroughly analyze this observation and discuss its significance for the continual learning process. Furthermore, we exploit this finding to propose an effective algorithm that constrains the sequentially learned minima to behave as the multitask solution. We show that our method outperforms several state of the art continual learning algorithms on various vision benchmarks.
Temporal Difference Uncertainties as a Signal for Exploration
Oct 05, 2020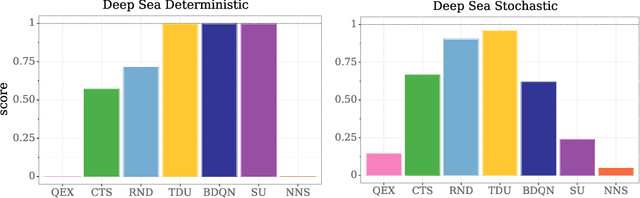
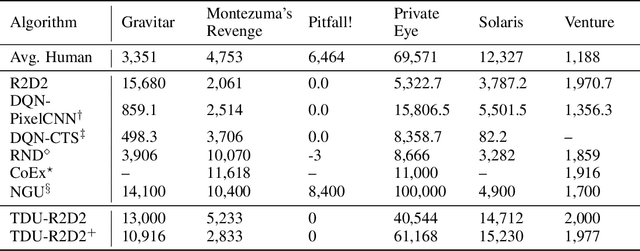
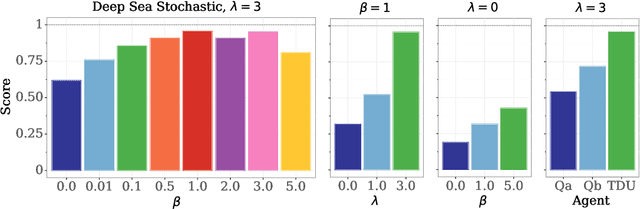

An effective approach to exploration in reinforcement learning is to rely on an agent's uncertainty over the optimal policy, which can yield near-optimal exploration strategies in tabular settings. However, in non-tabular settings that involve function approximators, obtaining accurate uncertainty estimates is almost as challenging a problem. In this paper, we highlight that value estimates are easily biased and temporally inconsistent. In light of this, we propose a novel method for estimating uncertainty over the value function that relies on inducing a distribution over temporal difference errors. This exploration signal controls for state-action transitions so as to isolate uncertainty in value that is due to uncertainty over the agent's parameters. Because our measure of uncertainty conditions on state-action transitions, we cannot act on this measure directly. Instead, we incorporate it as an intrinsic reward and treat exploration as a separate learning problem, induced by the agent's temporal difference uncertainties. We introduce a distinct exploration policy that learns to collect data with high estimated uncertainty, which gives rise to a curriculum that smoothly changes throughout learning and vanishes in the limit of perfect value estimates. We evaluate our method on hard exploration tasks, including Deep Sea and Atari 2600 environments and find that our proposed form of exploration facilitates both diverse and deep exploration.