 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel compression via distillation and quantization
Paper and Code
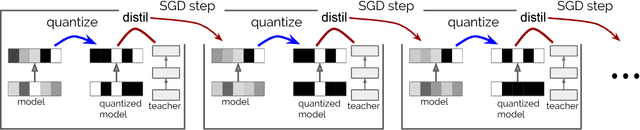
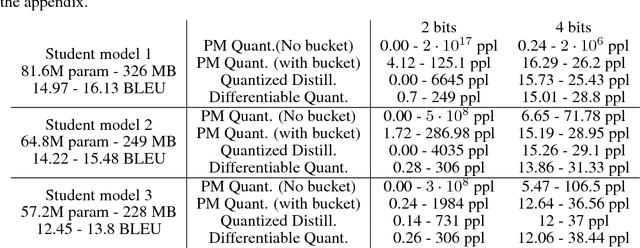
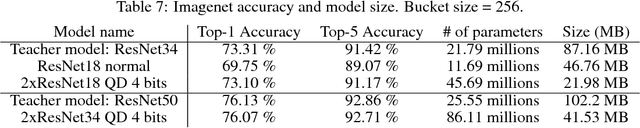
Deep neural networks (DNNs) continue to make significant advances, solving tasks from image classification to translation or reinforcement learning. One aspect of the field receiving considerable attention is efficiently executing deep models in resource-constrained environments, such as mobile or embedded devices. This paper focuses on this problem, and proposes two new compression methods, which jointly leverage weight quantization and distillation of larger teacher networks into smaller student networks. The first method we propose is called quantized distillation and leverages distillation during the training process, by incorporating distillation loss, expressed with respect to the teacher, into the training of a student network whose weights are quantized to a limited set of levels. The second method, differentiable quantization, optimizes the location of quantization points through stochastic gradient descent, to better fit the behavior of the teacher model. We validate both methods through experiments on convolutional and recurrent architectures. We show that quantized shallow students can reach similar accuracy levels to full-precision teacher models, while providing order of magnitude compression, and inference speedup that is linear in the depth reduction. In sum, our results enable DNNs for resource-constrained environments to leverage architecture and accuracy advances developed on more powerful devices.