 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Continuous diffusion for categorical data
Dec 15, 2022



Diffusion models have quickly become the go-to paradigm for generative modelling of perceptual signals (such as images and sound) through iterative refinement. Their success hinges on the fact that the underlying physical phenomena are continuous. For inherently discrete and categorical data such as language, various diffusion-inspired alternatives have been proposed. However, the continuous nature of diffusion models conveys many benefits, and in this work we endeavour to preserve it. We propose CDCD, a framework for modelling categorical data with diffusion models that are continuous both in time and input space. We demonstrate its efficacy on several language modelling tasks.
MAD for Robust Reinforcement Learning in Machine Translation
Jul 18, 2022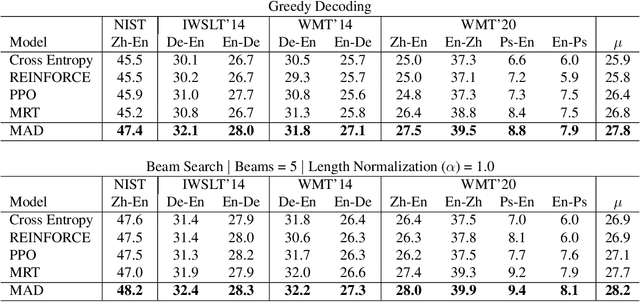
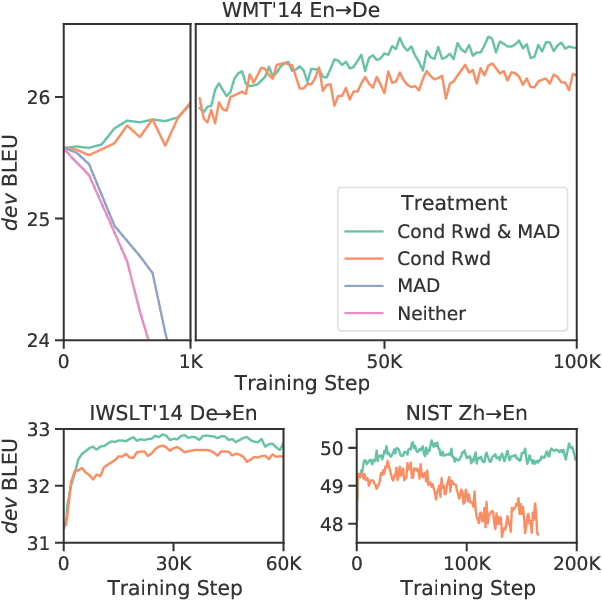
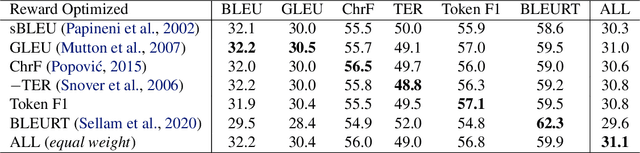
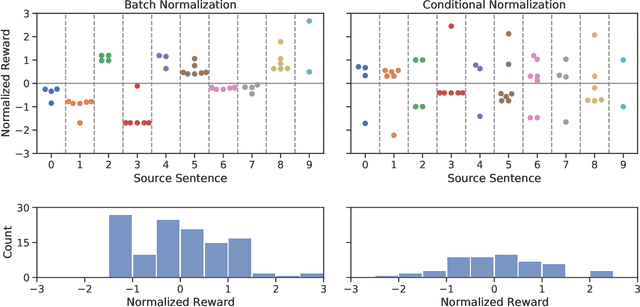
We introduce a new distributed policy gradient algorithm and show that it outperforms existing reward-aware training procedures such as REINFORCE, minimum risk training (MRT) and proximal policy optimization (PPO) in terms of training stability and generalization performance when optimizing machine translation models. Our algorithm, which we call MAD (on account of using the mean absolute deviation in the importance weighting calculation), has distributed data generators sampling multiple candidates per source sentence on worker nodes, while a central learner updates the policy. MAD depends crucially on two variance reduction strategies: (1) a conditional reward normalization method that ensures each source sentence has both positive and negative reward translation examples and (2) a new robust importance weighting scheme that acts as a conditional entropy regularizer. Experiments on a variety of translation tasks show that policies learned using the MAD algorithm perform very well when using both greedy decoding and beam search, and that the learned policies are sensitive to the specific reward used during training.
Transformer Grammars: Augmenting Transformer Language Models with Syntactic Inductive Biases at Scale
Mar 01, 2022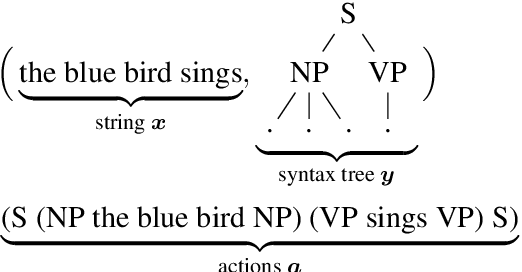
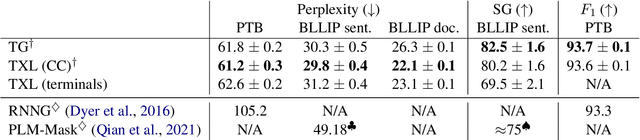
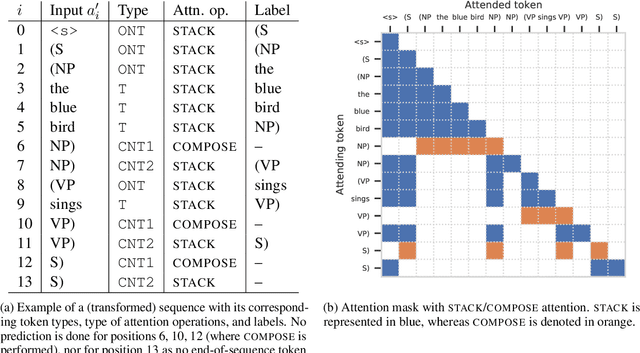
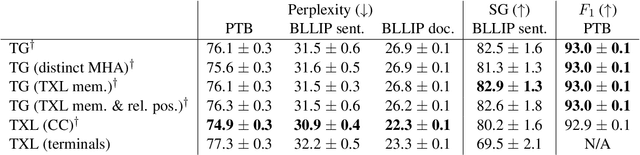
Transformer language models that are trained on vast amounts of data have achieved remarkable success at various NLP benchmarks. Intriguingly, this success is achieved by models that lack an explicit modeling of hierarchical syntactic structures, which were hypothesized by decades of linguistic research to be necessary for good generalization. This naturally leaves a question: to what extent can we further improve the performance of Transformer language models, through an inductive bias that encourages the model to explain the data through the lens of recursive syntactic compositions? Although the benefits of modeling recursive syntax have been shown at the small data and model scales, it remains an open question whether -- and to what extent -- a similar design principle is still beneficial in the case of powerful Transformer language models that work well at scale. To answer these questions, we introduce Transformer Grammars -- a novel class of Transformer language models that combine: (i) the expressive power, scalability, and strong performance of Transformers, and (ii) recursive syntactic compositions, which here are implemented through a special attention mask. We find that Transformer Grammars outperform various strong baselines on multiple syntax-sensitive language modeling evaluation metrics, in addition to sentence-level language modeling perplexity. Nevertheless, we find that the recursive syntactic composition bottleneck harms perplexity on document-level modeling, providing evidence that a different kind of memory mechanism -- that works independently of syntactic structures -- plays an important role in the processing of long-form text.
Enabling arbitrary translation objectives with Adaptive Tree Search
Feb 23, 2022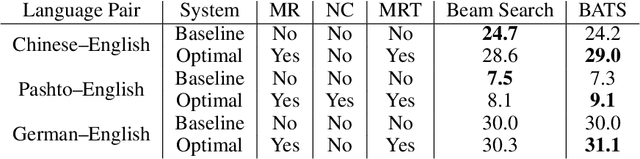
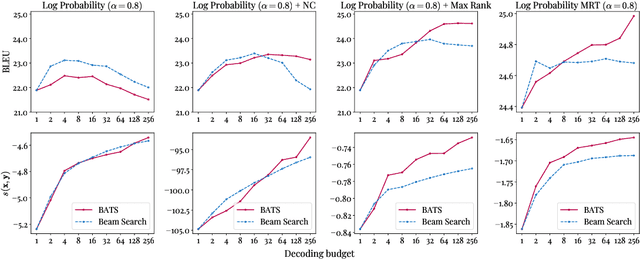
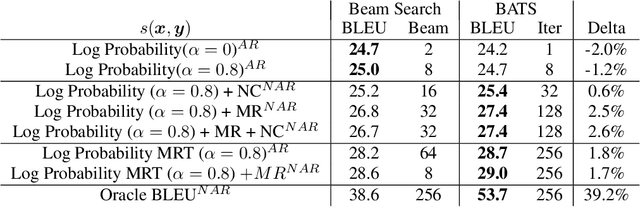
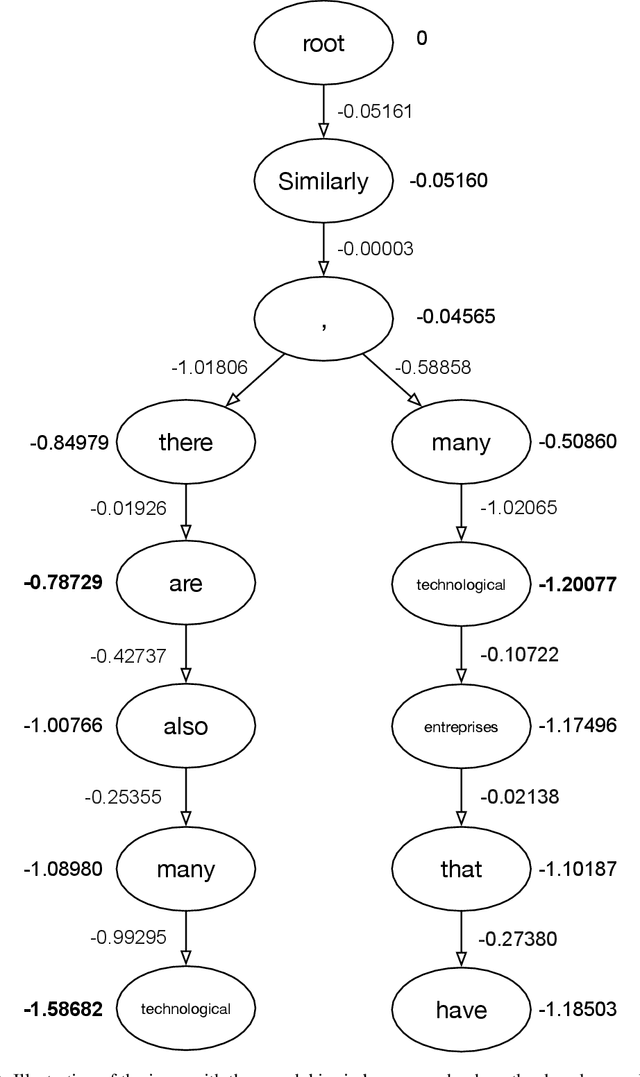
We introduce an adaptive tree search algorithm, that can find high-scoring outputs under translation models that make no assumptions about the form or structure of the search objective. This algorithm -- a deterministic variant of Monte Carlo tree search -- enables the exploration of new kinds of models that are unencumbered by constraints imposed to make decoding tractable, such as autoregressivity or conditional independence assumptions. When applied to autoregressive models, our algorithm has different biases than beam search has, which enables a new analysis of the role of decoding bias in autoregressive models. Empirically, we show that our adaptive tree search algorithm finds outputs with substantially better model scores compared to beam search in autoregressive models, and compared to reranking techniques in models whose scores do not decompose additively with respect to the words in the output. We also characterise the correlation of several translation model objectives with respect to BLEU. We find that while some standard models are poorly calibrated and benefit from the beam search bias, other often more robust models (autoregressive models tuned to maximize expected automatic metric scores, the noisy channel model and a newly proposed objective) benefit from increasing amounts of search using our proposed decoder, whereas the beam search bias limits the improvements obtained from such objectives. Thus, we argue that as models improve, the improvements may be masked by over-reliance on beam search or reranking based methods.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering
Jun 09, 2021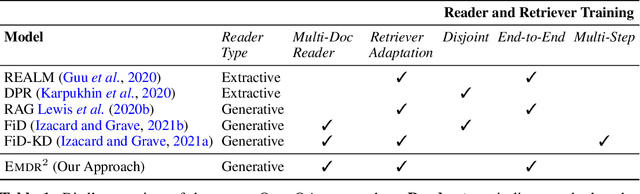
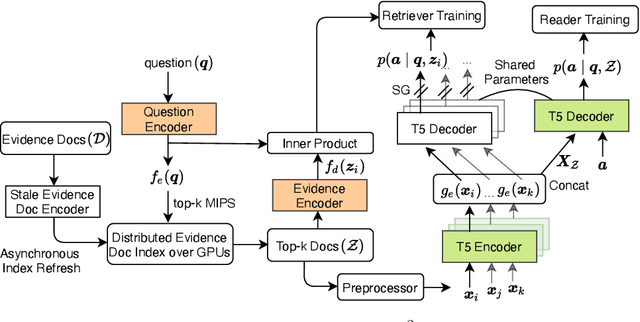
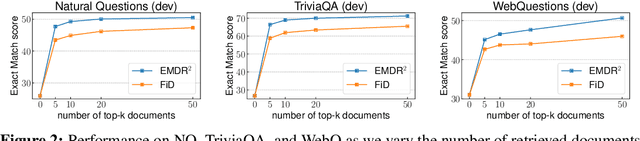
We present an end-to-end differentiable training method for retrieval-augmented open-domain question answering systems that combine information from multiple retrieved documents when generating answers. We model retrieval decisions as latent variables over sets of relevant documents. Since marginalizing over sets of retrieved documents is computationally hard, we approximate this using an expectation-maximization algorithm. We iteratively estimate the value of our latent variable (the set of relevant documents for a given question) and then use this estimate to update the retriever and reader parameters. We hypothesize that such end-to-end training allows training signals to flow to the reader and then to the retriever better than staged-wise training. This results in a retriever that is able to select more relevant documents for a question and a reader that is trained on more accurate documents to generate an answer. Experiments on three benchmark datasets demonstrate that our proposed method outperforms all existing approaches of comparable size by 2-3% absolute exact match points, achieving new state-of-the-art results. Our results also demonstrate the feasibility of learning to retrieve to improve answer generation without explicit supervision of retrieval decisions.
Diverse Pretrained Context Encodings Improve Document Translation
Jun 07, 2021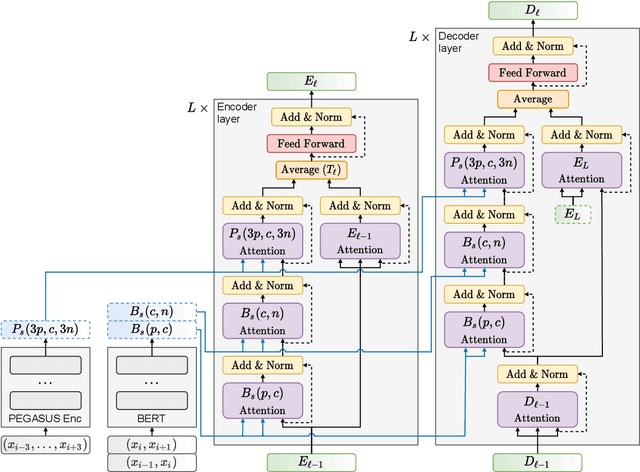
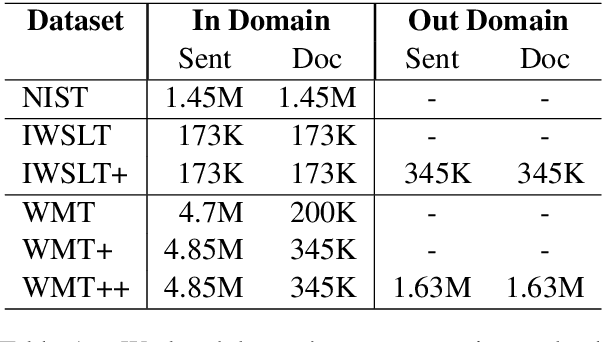

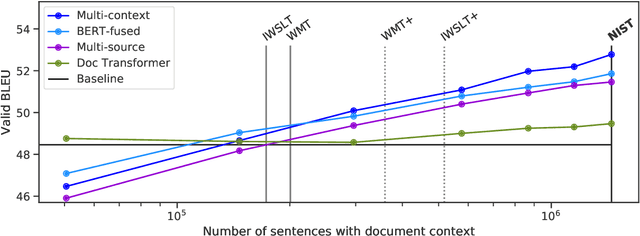
We propose a new architecture for adapting a sentence-level sequence-to-sequence transformer by incorporating multiple pretrained document context signals and assess the impact on translation performance of (1) different pretraining approaches for generating these signals, (2) the quantity of parallel data for which document context is available, and (3) conditioning on source, target, or source and target contexts. Experiments on the NIST Chinese-English, and IWSLT and WMT English-German tasks support four general conclusions: that using pretrained context representations markedly improves sample efficiency, that adequate parallel data resources are crucial for learning to use document context, that jointly conditioning on multiple context representations outperforms any single representation, and that source context is more valuable for translation performance than target side context. Our best multi-context model consistently outperforms the best existing context-aware transformers.
Exposing the Implicit Energy Networks behind Masked Language Models via Metropolis--Hastings
Jun 04, 2021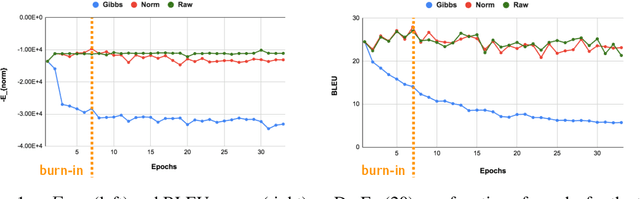

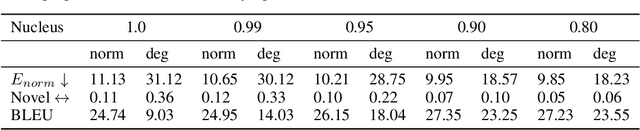
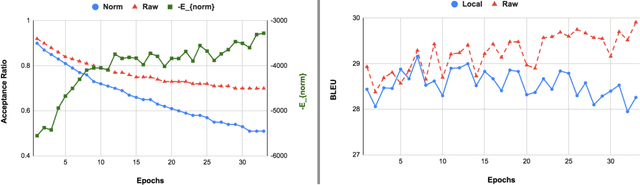
While recent work has shown that scores from models trained by the ubiquitous masked language modeling (MLM) objective effectively discriminate probable and improbable sequences, it is still an open question if these MLMs specify a principled probability distribution over the space of possible sequences. In this paper, we interpret MLMs as energy-based sequence models and propose two energy parametrizations derivable from the trained MLMs. In order to draw samples correctly from these models, we develop a tractable \emph{sampling} scheme based on the Metropolis--Hastings Monte Carlo algorithm. In our approach, samples are proposed from the same masked conditionals used for training the masked language models, and they are accepted or rejected based on their energy values according to the target distribution. We validate the effectiveness of the proposed parametrizations by exploring the quality of samples drawn from these energy-based models on the conditional generation task of machine translation. We theoretically and empirically justify our sampling algorithm by showing that the masked conditionals on their own do not yield a Markov chain whose stationary distribution is that of our target distribution, and our approach generates higher quality samples than other recently proposed undirected generation approaches (Wang et al., 2019, Ghazvininejad et al., 2019).
Syntactic Structure Distillation Pretraining For Bidirectional Encoders
May 27, 2020
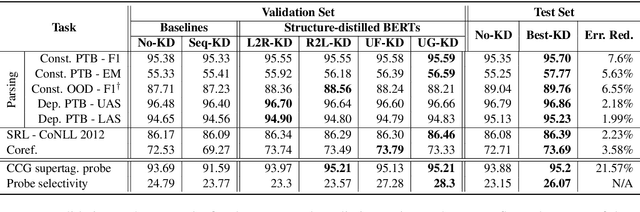
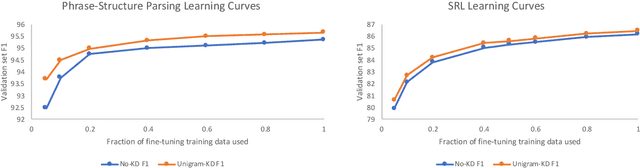
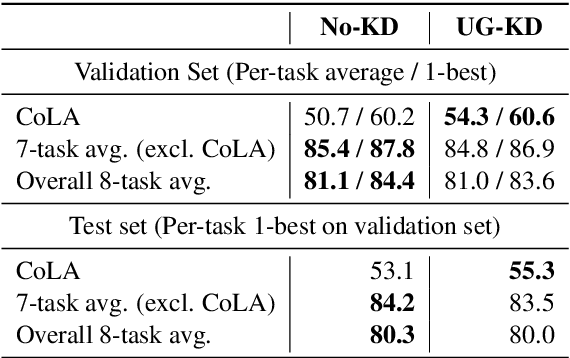
Textual representation learners trained on large amounts of data have achieved notable success on downstream tasks; intriguingly, they have also performed well on challenging tests of syntactic competence. Given this success, it remains an open question whether scalable learners like BERT can become fully proficient in the syntax of natural language by virtue of data scale alone, or whether they still benefit from more explicit syntactic biases. To answer this question, we introduce a knowledge distillation strategy for injecting syntactic biases into BERT pretraining, by distilling the syntactically informative predictions of a hierarchical---albeit harder to scale---syntactic language model. Since BERT models masked words in bidirectional context, we propose to distill the approximate marginal distribution over words in context from the syntactic LM. Our approach reduces relative error by 2-21% on a diverse set of structured prediction tasks, although we obtain mixed results on the GLUE benchmark. Our findings demonstrate the benefits of syntactic biases, even in representation learners that exploit large amounts of data, and contribute to a better understanding of where syntactic biases are most helpful in benchmarks of natural language understanding.