 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-pass Recurrent Neural Networks - A memory architecture for longer-term correlation discovery
Paper and Code
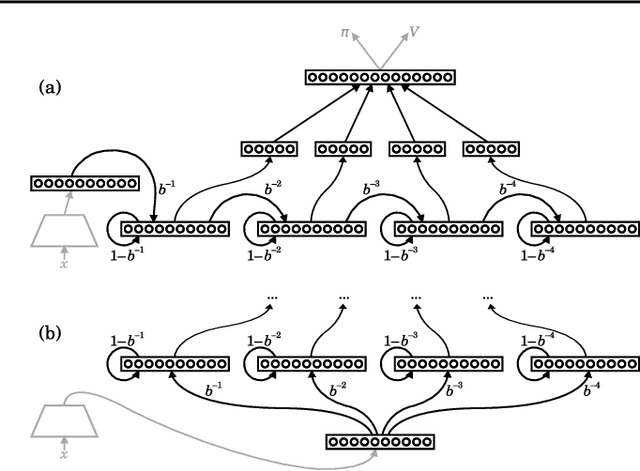
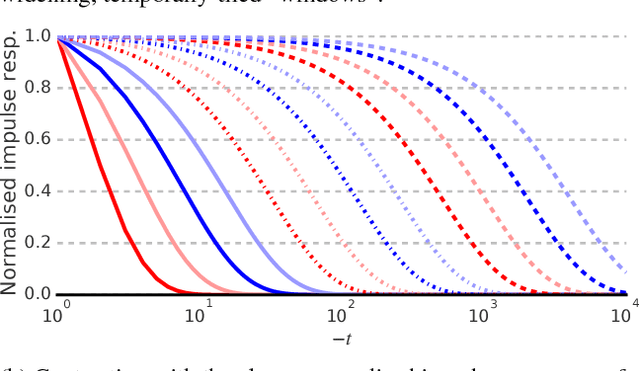

Reinforcement learning (RL) agents performing complex tasks must be able to remember observations and actions across sizable time intervals. This is especially true during the initial learning stages, when exploratory behaviour can increase the delay between specific actions and their effects. Many new or popular approaches for learning these distant correlations employ backpropagation through time (BPTT), but this technique requires storing observation traces long enough to span the interval between cause and effect. Besides memory demands, learning dynamics like vanishing gradients and slow convergence due to infrequent weight updates can reduce BPTT's practicality; meanwhile, although online recurrent network learning is a developing topic, most approaches are not efficient enough to use as replacements. We propose a simple, effective memory strategy that can extend the window over which BPTT can learn without requiring longer traces. We explore this approach empirically on a few tasks and discuss its implications.