 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-parametric Memory for Spatio-Temporal Segmentation of Construction Zones for Self-Driving
Jan 18, 2021
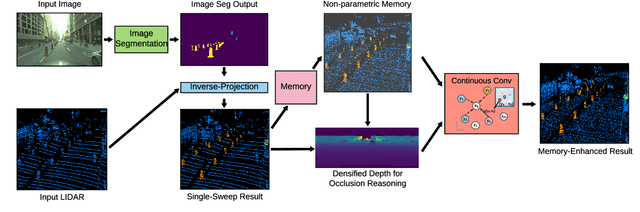
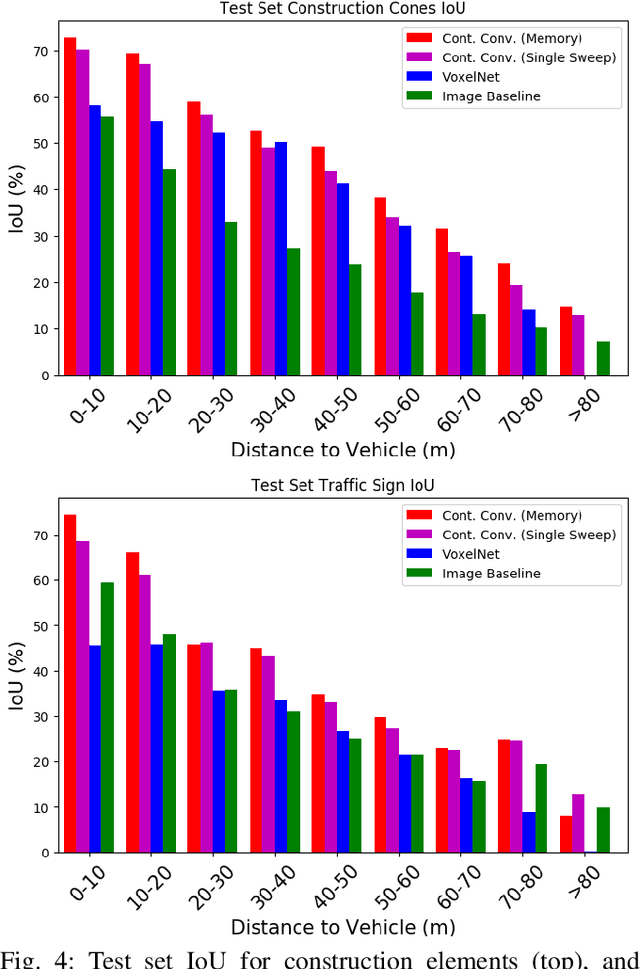

In this paper, we introduce a non-parametric memory representation for spatio-temporal segmentation that captures the local space and time around an autonomous vehicle (AV). Our representation has three important properties: (i) it remembers what it has seen in the past, (ii) it reinforces and (iii) forgets its past beliefs based on new evidence. Reinforcing is important as the first time we see an element we might be uncertain, e.g, if the element is heavily occluded or at range. Forgetting is desirable, as otherwise false positives will make the self driving vehicle behave erratically. Our process is informed by 3D reasoning, as occlusion is key to distinguishing between the desire to forget and to remember. We show how our method can be used as an online component to complement static world representations such as HD maps by detecting and remembering changes that should be superimposed on top of this static view due to such events.
Secrets of 3D Implicit Object Shape Reconstruction in the Wild
Jan 18, 2021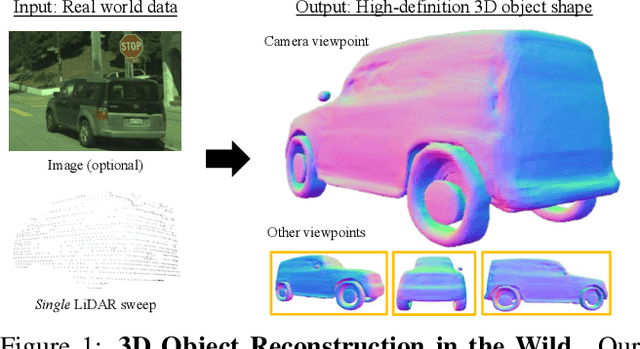
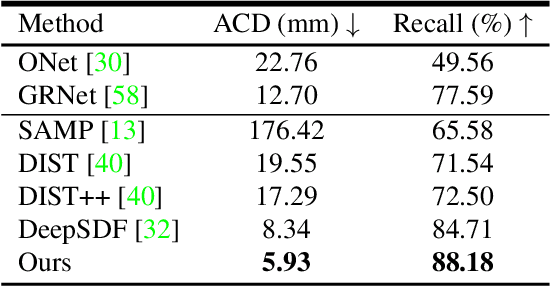

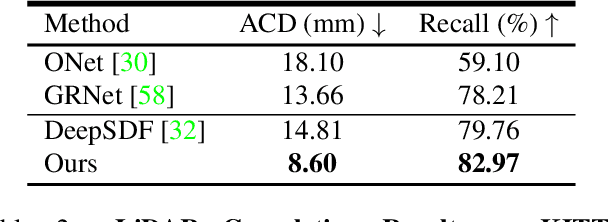
Reconstructing high-fidelity 3D objects from sparse, partial observation is of crucial importance for various applications in computer vision, robotics, and graphics. While recent neural implicit modeling methods show promising results on synthetic or dense datasets, they perform poorly on real-world data that is sparse and noisy. This paper analyzes the root cause of such deficient performance of a popular neural implicit model. We discover that the limitations are due to highly complicated objectives, lack of regularization, and poor initialization. To overcome these issues, we introduce two simple yet effective modifications: (i) a deep encoder that provides a better and more stable initialization for latent code optimization; and (ii) a deep discriminator that serves as a prior model to boost the fidelity of the shape. We evaluate our approach on two real-wold self-driving datasets and show superior performance over state-of-the-art 3D object reconstruction methods.
Deep Structured Reactive Planning
Jan 18, 2021
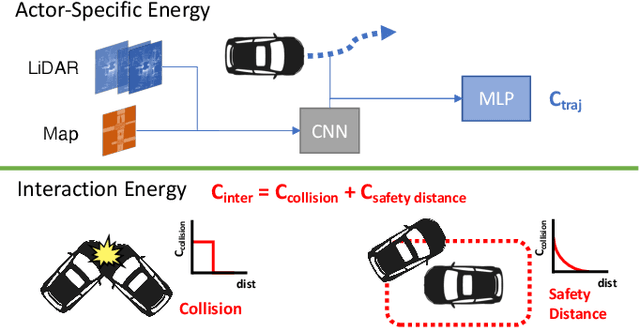

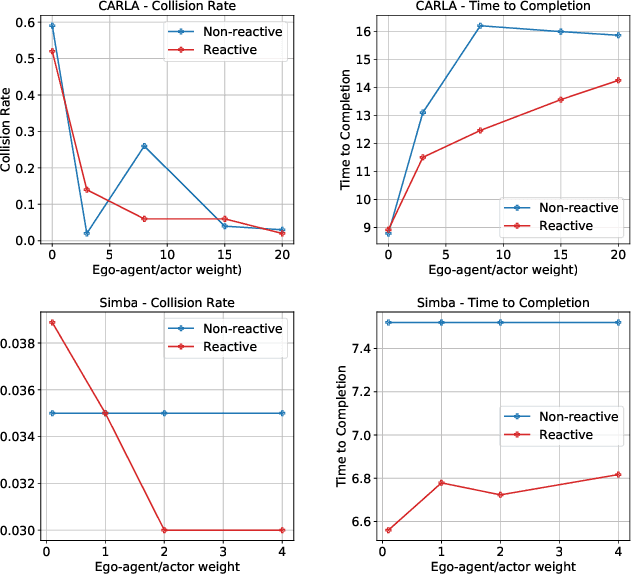
An intelligent agent operating in the real-world must balance achieving its goal with maintaining the safety and comfort of not only itself, but also other participants within the surrounding scene. This requires jointly reasoning about the behavior of other actors while deciding its own actions as these two processes are inherently intertwined - a vehicle will yield to us if we decide to proceed first at the intersection but will proceed first if we decide to yield. However, this is not captured in most self-driving pipelines, where planning follows prediction. In this paper we propose a novel data-driven, reactive planning objective which allows a self-driving vehicle to jointly reason about its own plans as well as how other actors will react to them. We formulate the problem as an energy-based deep structured model that is learned from observational data and encodes both the planning and prediction problems. Through simulations based on both real-world driving and synthetically generated dense traffic, we demonstrate that our reactive model outperforms a non-reactive variant in successfully completing highly complex maneuvers (lane merges/turns in traffic) faster, without trading off collision rate.
MP3: A Unified Model to Map, Perceive, Predict and Plan
Jan 18, 2021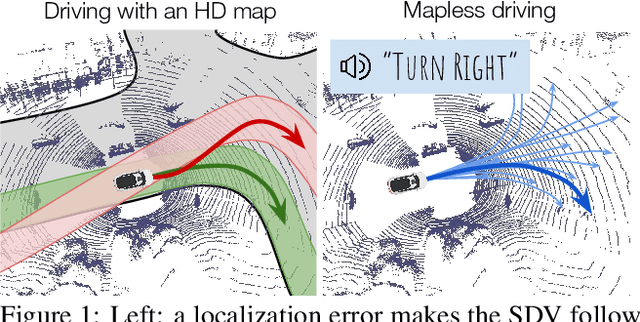
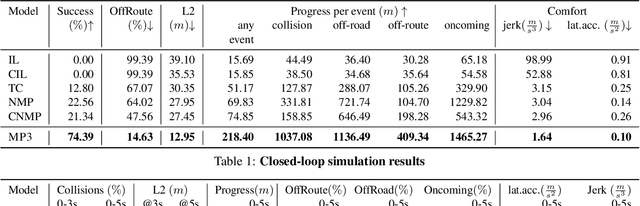
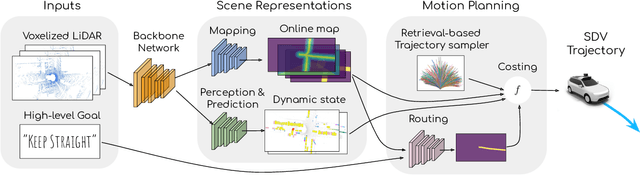
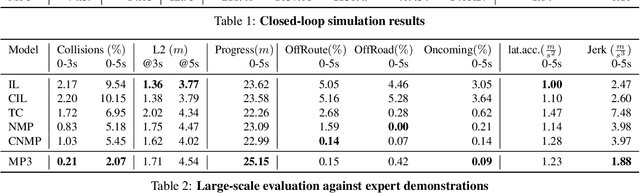
High-definition maps (HD maps) are a key component of most modern self-driving systems due to their valuable semantic and geometric information. Unfortunately, building HD maps has proven hard to scale due to their cost as well as the requirements they impose in the localization system that has to work everywhere with centimeter-level accuracy. Being able to drive without an HD map would be very beneficial to scale self-driving solutions as well as to increase the failure tolerance of existing ones (e.g., if localization fails or the map is not up-to-date). Towards this goal, we propose MP3, an end-to-end approach to mapless driving where the input is raw sensor data and a high-level command (e.g., turn left at the intersection). MP3 predicts intermediate representations in the form of an online map and the current and future state of dynamic agents, and exploits them in a novel neural motion planner to make interpretable decisions taking into account uncertainty. We show that our approach is significantly safer, more comfortable, and can follow commands better than the baselines in challenging long-term closed-loop simulations, as well as when compared to an expert driver in a large-scale real-world dataset.
Deep Parametric Continuous Convolutional Neural Networks
Jan 17, 2021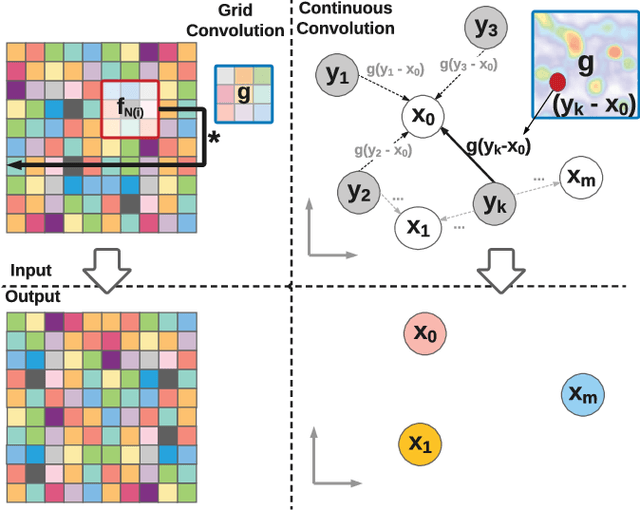

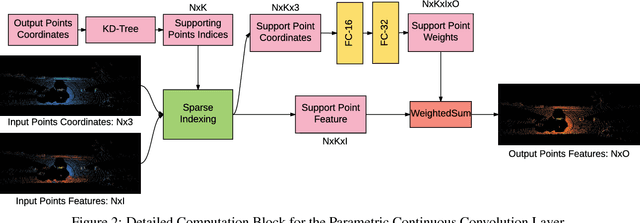
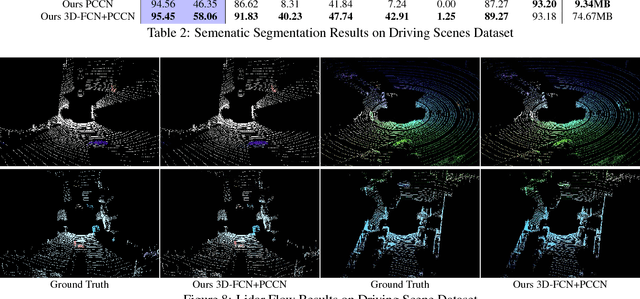
Standard convolutional neural networks assume a grid structured input is available and exploit discrete convolutions as their fundamental building blocks. This limits their applicability to many real-world applications. In this paper we propose Parametric Continuous Convolution, a new learnable operator that operates over non-grid structured data. The key idea is to exploit parameterized kernel functions that span the full continuous vector space. This generalization allows us to learn over arbitrary data structures as long as their support relationship is computable. Our experiments show significant improvement over the state-of-the-art in point cloud segmentation of indoor and outdoor scenes, and lidar motion estimation of driving scenes.
End-to-end Interpretable Neural Motion Planner
Jan 17, 2021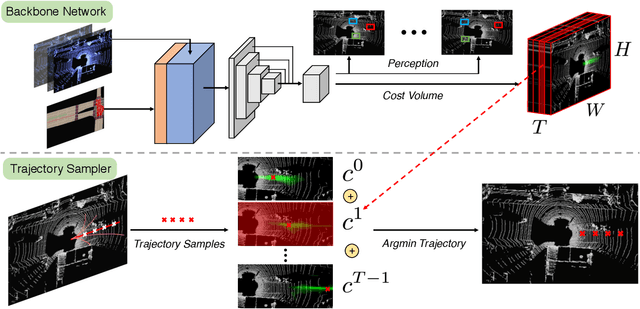
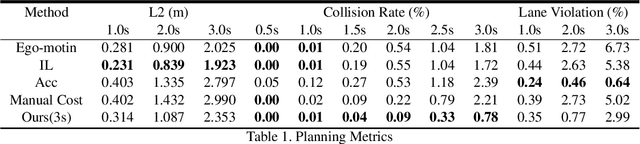

In this paper, we propose a neural motion planner (NMP) for learning to drive autonomously in complex urban scenarios that include traffic-light handling, yielding, and interactions with multiple road-users. Towards this goal, we design a holistic model that takes as input raw LIDAR data and a HD map and produces interpretable intermediate representations in the form of 3D detections and their future trajectories, as well as a cost volume defining the goodness of each position that the self-driving car can take within the planning horizon. We then sample a set of diverse physically possible trajectories and choose the one with the minimum learned cost. Importantly, our cost volume is able to naturally capture multi-modality. We demonstrate the effectiveness of our approach in real-world driving data captured in several cities in North America. Our experiments show that the learned cost volume can generate safer planning than all the baselines.
LaneRCNN: Distributed Representations for Graph-Centric Motion Forecasting
Jan 17, 2021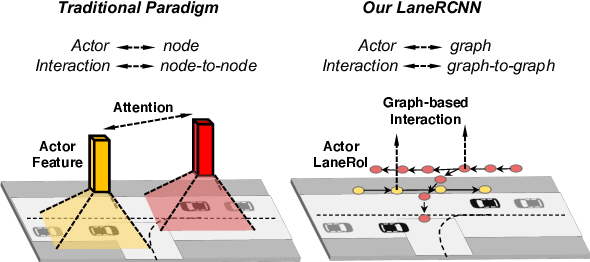
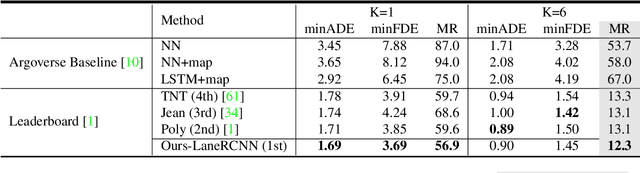
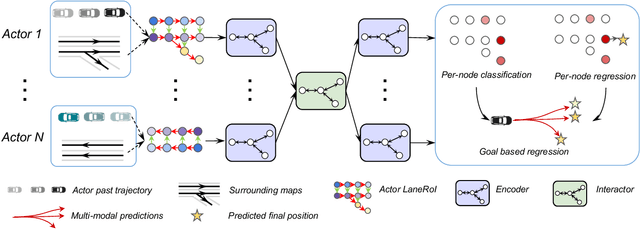
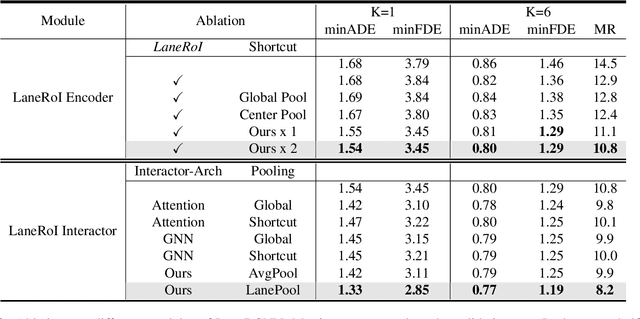
Forecasting the future behaviors of dynamic actors is an important task in many robotics applications such as self-driving. It is extremely challenging as actors have latent intentions and their trajectories are governed by complex interactions between the other actors, themselves, and the maps. In this paper, we propose LaneRCNN, a graph-centric motion forecasting model. Importantly, relying on a specially designed graph encoder, we learn a local lane graph representation per actor (LaneRoI) to encode its past motions and the local map topology. We further develop an interaction module which permits efficient message passing among local graph representations within a shared global lane graph. Moreover, we parameterize the output trajectories based on lane graphs, a more amenable prediction parameterization. Our LaneRCNN captures the actor-to-actor and the actor-to-map relations in a distributed and map-aware manner. We demonstrate the effectiveness of our approach on the large-scale Argoverse Motion Forecasting Benchmark. We achieve the 1st place on the leaderboard and significantly outperform previous best results.
Network Automatic Pruning: Start NAP and Take a Nap
Jan 17, 2021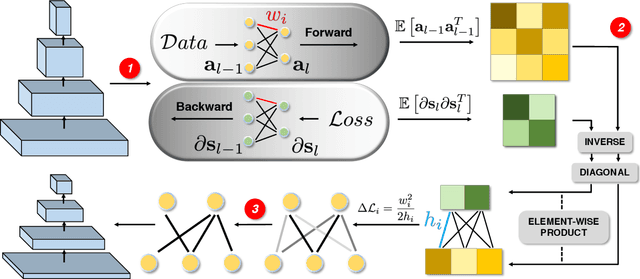
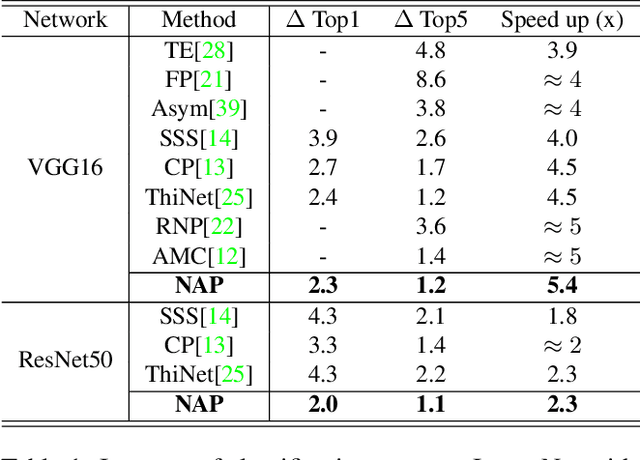
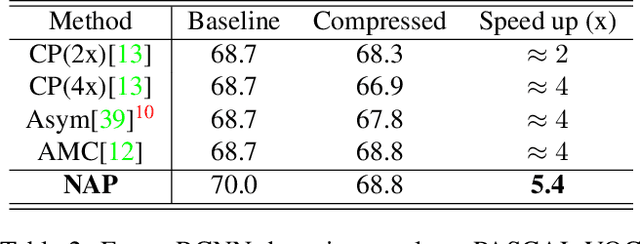
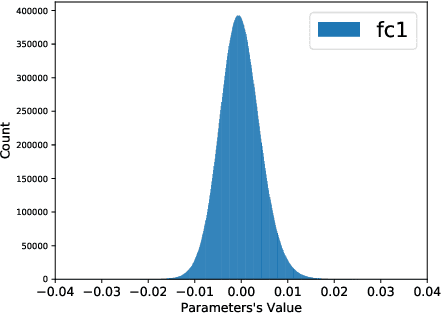
Network pruning can significantly reduce the computation and memory footprint of large neural networks. To achieve a good trade-off between model size and performance, popular pruning techniques usually rely on hand-crafted heuristics and require manually setting the compression ratio for each layer. This process is typically time-consuming and requires expert knowledge to achieve good results. In this paper, we propose NAP, a unified and automatic pruning framework for both fine-grained and structured pruning. It can find out unimportant components of a network and automatically decide appropriate compression ratios for different layers, based on a theoretically sound criterion. Towards this goal, NAP uses an efficient approximation of the Hessian for evaluating the importances of components, based on a Kronecker-factored Approximate Curvature method. Despite its simpleness to use, NAP outperforms previous pruning methods by large margins. For fine-grained pruning, NAP can compress AlexNet and VGG16 by 25x, and ResNet-50 by 6.7x without loss in accuracy on ImageNet. For structured pruning (e.g. channel pruning), it can reduce flops of VGG16 by 5.4x and ResNet-50 by 2.3x with only 1% accuracy drop. More importantly, this method is almost free from hyper-parameter tuning and requires no expert knowledge. You can start NAP and then take a nap!
PLUME: Efficient 3D Object Detection from Stereo Images
Jan 17, 2021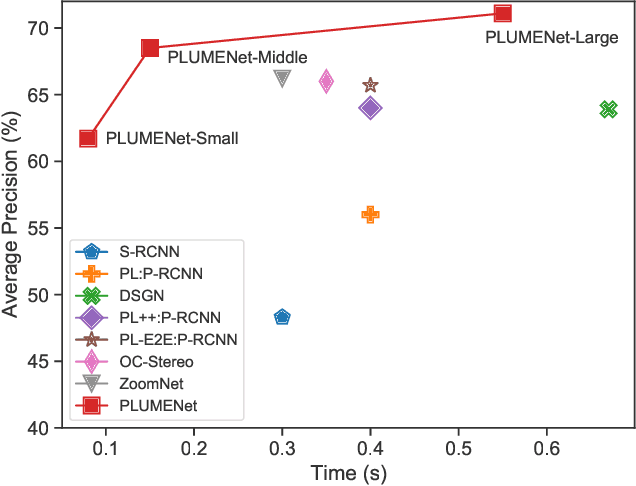


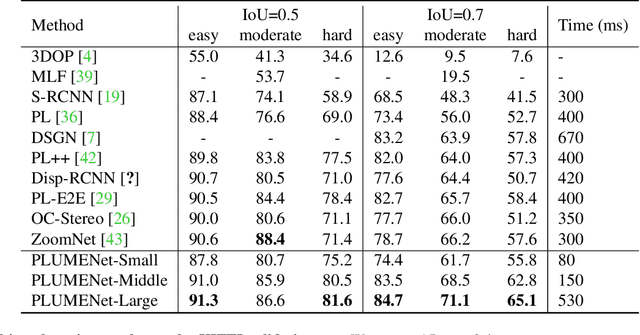
3D object detection plays a significant role in various robotic applications including self-driving. While many approaches rely on expensive 3D sensors like LiDAR to produce accurate 3D estimates, stereo-based methods have recently shown promising results at a lower cost. Existing methods tackle the problem in two steps: first depth estimation is performed, a pseudo LiDAR point cloud representation is computed from the depth estimates, and then object detection is performed in 3D space. However, because the two separate tasks are optimized in different metric spaces, the depth estimation is biased towards big objects and may cause sub-optimal performance of 3D detection. In this paper we propose a model that unifies these two tasks in the same metric space for the first time. Specifically, our model directly constructs a pseudo LiDAR feature volume (PLUME) in 3D space, which is used to solve both occupancy estimation and object detection tasks. PLUME achieves state-of-the-art performance on the challenging KITTI benchmark, with significantly reduced inference time compared with existing methods.
Cost-Efficient Online Hyperparameter Optimization
Jan 17, 2021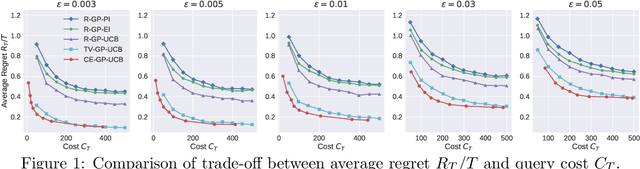
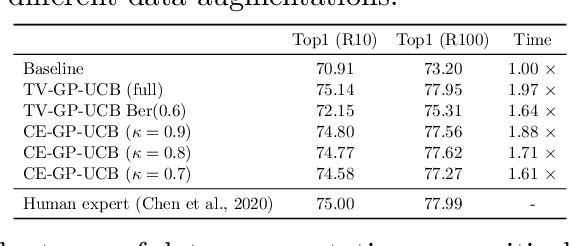
Recent work on hyperparameters optimization (HPO) has shown the possibility of training certain hyperparameters together with regular parameters. However, these online HPO algorithms still require running evaluation on a set of validation examples at each training step, steeply increasing the training cost. To decide when to query the validation loss, we model online HPO as a time-varying Bayesian optimization problem, on top of which we propose a novel \textit{costly feedback} setting to capture the concept of the query cost. Under this setting, standard algorithms are cost-inefficient as they evaluate on the validation set at every round. In contrast, the cost-efficient GP-UCB algorithm proposed in this paper queries the unknown function only when the model is less confident about current decisions. We evaluate our proposed algorithm by tuning hyperparameters online for VGG and ResNet on CIFAR-10 and ImageNet100. Our proposed online HPO algorithm reaches human expert-level performance within a single run of the experiment, while incurring only modest computational overhead compared to regular training.