 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDARsim: Realistic LiDAR Simulation by Leveraging the Real World
Jun 16, 2020
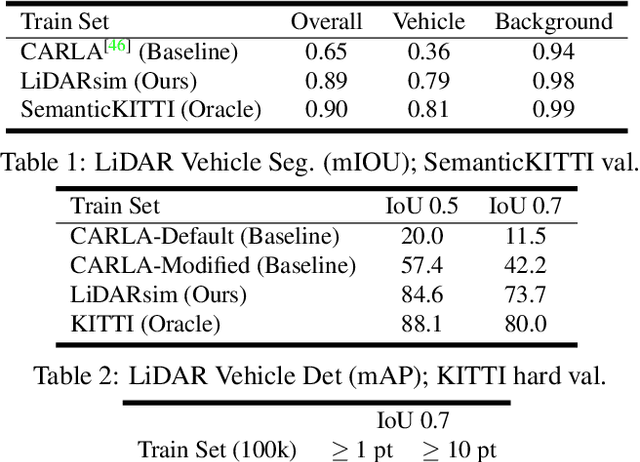
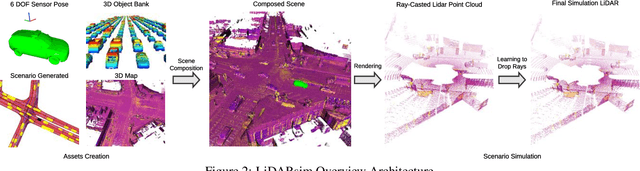
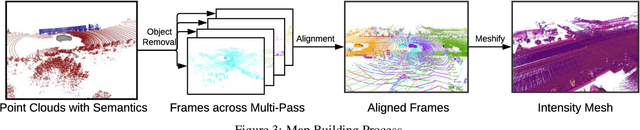
We tackle the problem of producing realistic simulations of LiDAR point clouds, the sensor of preference for most self-driving vehicles. We argue that, by leveraging real data, we can simulate the complex world more realistically compared to employing virtual worlds built from CAD/procedural models. Towards this goal, we first build a large catalog of 3D static maps and 3D dynamic objects by driving around several cities with our self-driving fleet. We can then generate scenarios by selecting a scene from our catalog and "virtually" placing the self-driving vehicle (SDV) and a set of dynamic objects from the catalog in plausible locations in the scene. To produce realistic simulations, we develop a novel simulator that captures both the power of physics-based and learning-based simulation. We first utilize ray casting over the 3D scene and then use a deep neural network to produce deviations from the physics-based simulation, producing realistic LiDAR point clouds. We showcase LiDARsim's usefulness for perception algorithms-testing on long-tail events and end-to-end closed-loop evaluation on safety-critical scenarios.
The Importance of Prior Knowledge in Precise Multimodal Prediction
Jun 04, 2020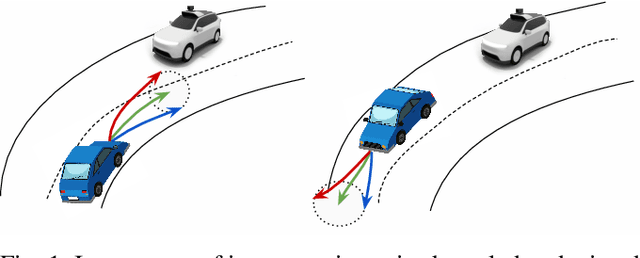
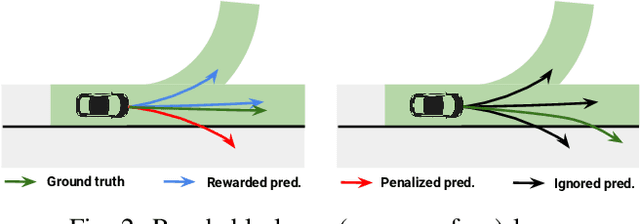
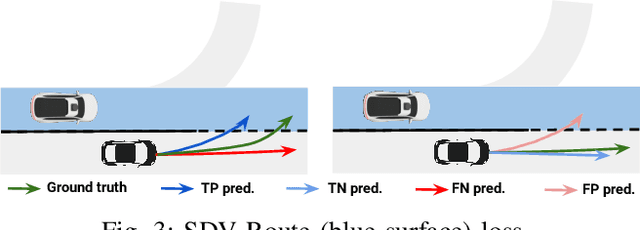

Roads have well defined geometries, topologies, and traffic rules. While this has been widely exploited in motion planning methods to produce maneuvers that obey the law, little work has been devoted to utilize these priors in perception and motion forecasting methods. In this paper we propose to incorporate these structured priors as a loss function. In contrast to imposing hard constraints, this approach allows the model to handle non-compliant maneuvers when those happen in the real world. Safe motion planning is the end goal, and thus a probabilistic characterization of the possible future developments of the scene is key to choose the plan with the lowest expected cost. Towards this goal, we design a framework that leverages REINFORCE to incorporate non-differentiable priors over sample trajectories from a probabilistic model, thus optimizing the whole distribution. We demonstrate the effectiveness of our approach on real-world self-driving datasets containing complex road topologies and multi-agent interactions. Our motion forecasts not only exhibit better precision and map understanding, but most importantly result in safer motion plans taken by our self-driving vehicle. We emphasize that despite the importance of this evaluation, it has been often overlooked by previous perception and motion forecasting works.
ShapeAdv: Generating Shape-Aware Adversarial 3D Point Clouds
May 24, 2020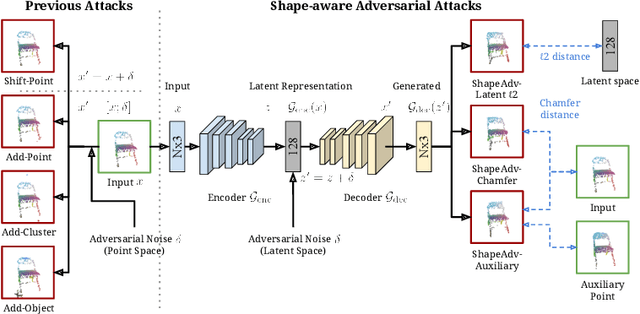
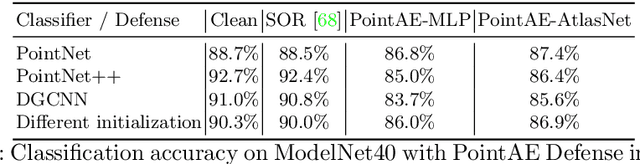
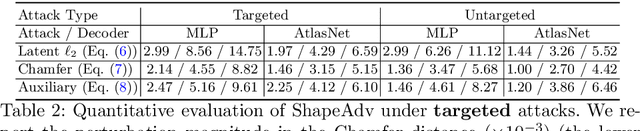
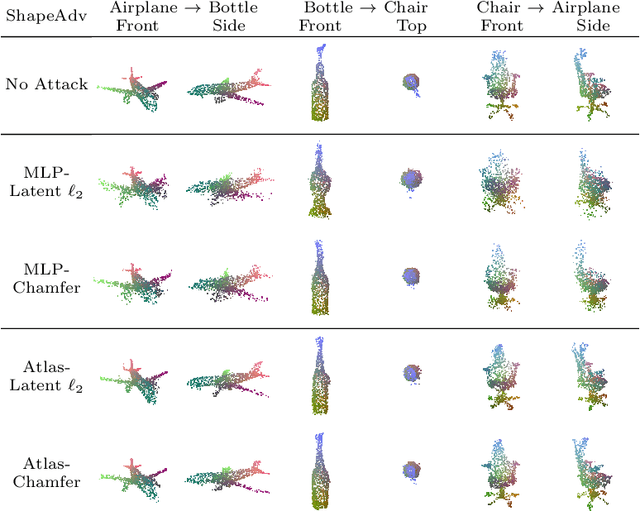
We introduce ShapeAdv, a novel framework to study shape-aware adversarial perturbations that reflect the underlying shape variations (e.g., geometric deformations and structural differences) in the 3D point cloud space. We develop shape-aware adversarial 3D point cloud attacks by leveraging the learned latent space of a point cloud auto-encoder where the adversarial noise is applied in the latent space. Specifically, we propose three different variants including an exemplar-based one by guiding the shape deformation with auxiliary data, such that the generated point cloud resembles the shape morphing between objects in the same category. Different from prior works, the resulting adversarial 3D point clouds reflect the shape variations in the 3D point cloud space while still being close to the original one. In addition, experimental evaluations on the ModelNet40 benchmark demonstrate that our adversaries are more difficult to defend with existing point cloud defense methods and exhibit a higher attack transferability across classifiers. Our shape-aware adversarial attacks are orthogonal to existing point cloud based attacks and shed light on the vulnerability of 3D deep neural networks.
OctSqueeze: Octree-Structured Entropy Model for LiDAR Compression
May 14, 2020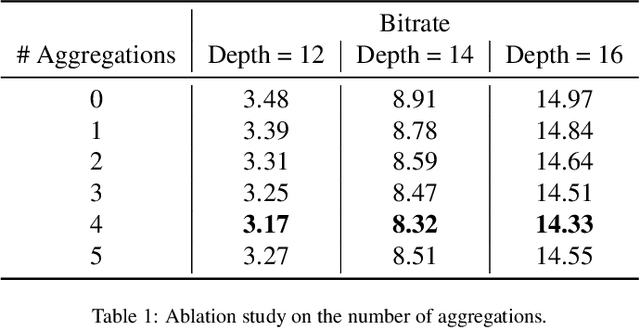
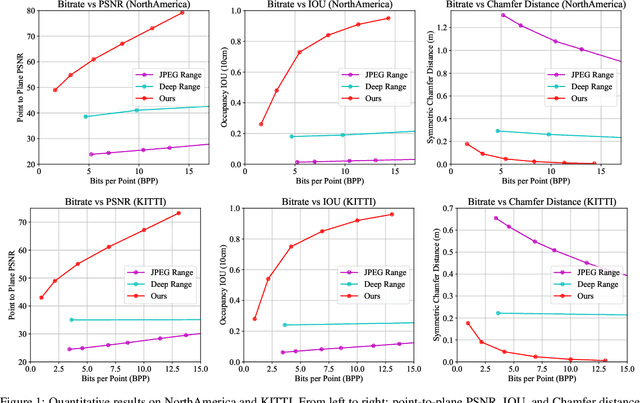
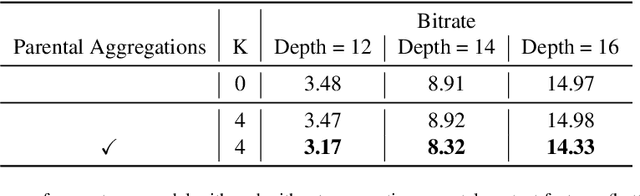
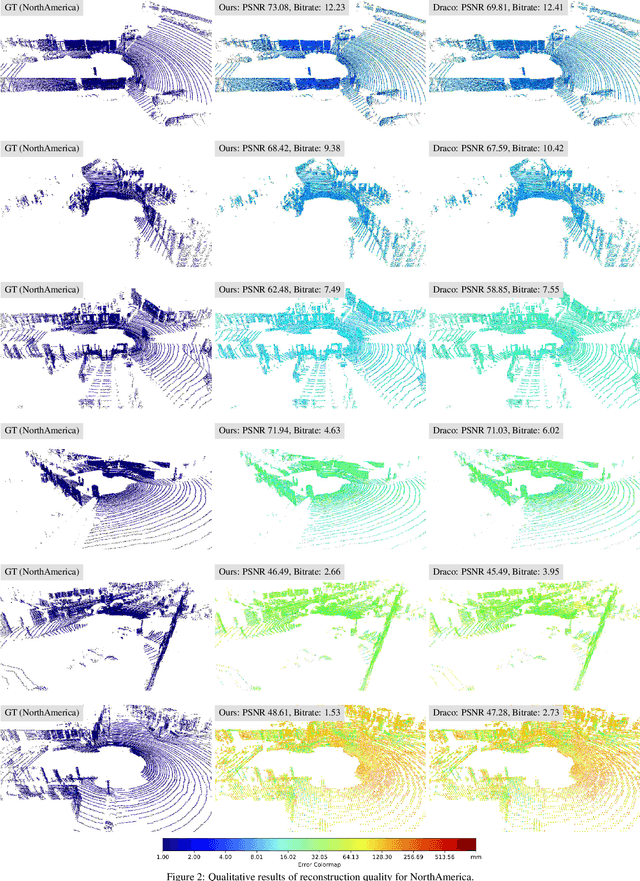
We present a novel deep compression algorithm to reduce the memory footprint of LiDAR point clouds. Our method exploits the sparsity and structural redundancy between points to reduce the bitrate. Towards this goal, we first encode the LiDAR points into an octree, a data-efficient structure suitable for sparse point clouds. We then design a tree-structured conditional entropy model that models the probabilities of the octree symbols to encode the octree into a compact bitstream. We validate the effectiveness of our method over two large-scale datasets. The results demonstrate that our approach reduces the bitrate by 10-20% at the same reconstruction quality, compared to the previous state-of-the-art. Importantly, we also show that for the same bitrate, our approach outperforms other compression algorithms when performing downstream 3D segmentation and detection tasks using compressed representations. Our algorithm can be used to reduce the onboard and offboard storage of LiDAR points for applications such as self-driving cars, where a single vehicle captures 84 billion points per day
Physically Realizable Adversarial Examples for LiDAR Object Detection
Apr 02, 2020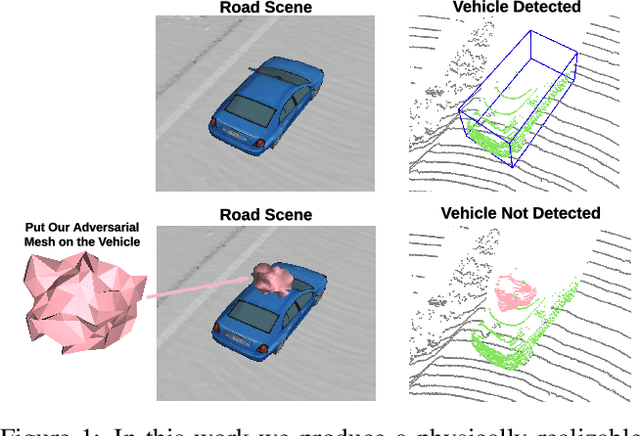
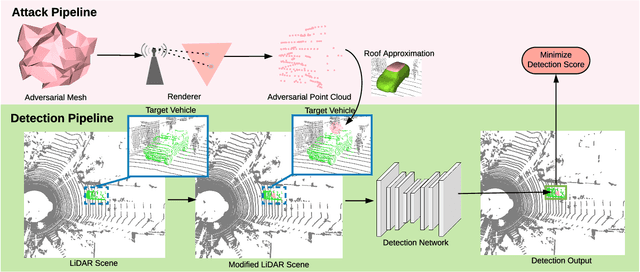
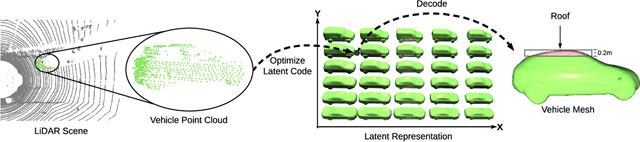

Modern autonomous driving systems rely heavily on deep learning models to process point cloud sensory data; meanwhile, deep models have been shown to be susceptible to adversarial attacks with visually imperceptible perturbations. Despite the fact that this poses a security concern for the self-driving industry, there has been very little exploration in terms of 3D perception, as most adversarial attacks have only been applied to 2D flat images. In this paper, we address this issue and present a method to generate universal 3D adversarial objects to fool LiDAR detectors. In particular, we demonstrate that placing an adversarial object on the rooftop of any target vehicle to hide the vehicle entirely from LiDAR detectors with a success rate of 80%. We report attack results on a suite of detectors using various input representation of point clouds. We also conduct a pilot study on adversarial defense using data augmentation. This is one step closer towards safer self-driving under unseen conditions from limited training data.
Dense RepPoints: Representing Visual Objects with Dense Point Sets
Dec 24, 2019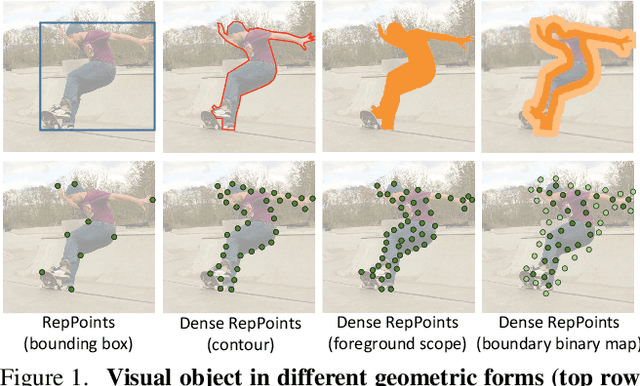
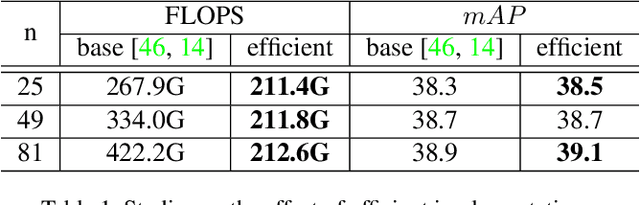
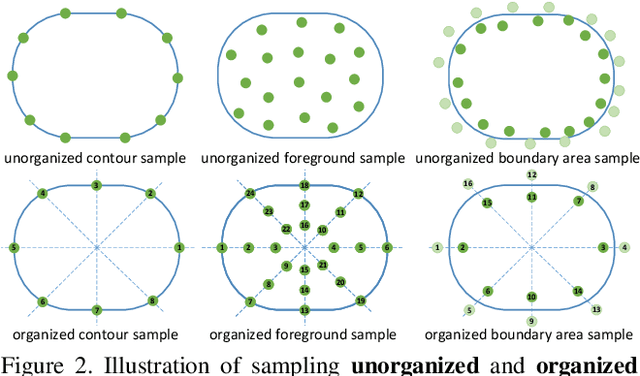
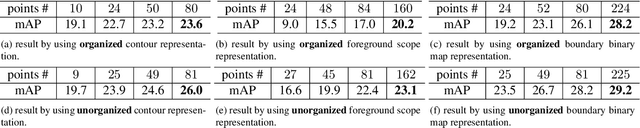
We present an object representation, called \textbf{Dense RepPoints}, for flexible and detailed modeling of object appearance and geometry. In contrast to the coarse geometric localization and feature extraction of bounding boxes, Dense RepPoints adaptively distributes a dense set of points to semantically and geometrically significant positions on an object, providing informative cues for object analysis. Techniques are developed to address challenges related to supervised training for dense point sets from image segments annotations and making this extensive representation computationally practical. In addition, the versatility of this representation is exploited to model object structure over multiple levels of granularity. Dense RepPoints significantly improves performance on geometrically-oriented visual understanding tasks, including a $1.6$ AP gain in object detection on the challenging COCO benchmark.
PolyTransform: Deep Polygon Transformer for Instance Segmentation
Dec 06, 2019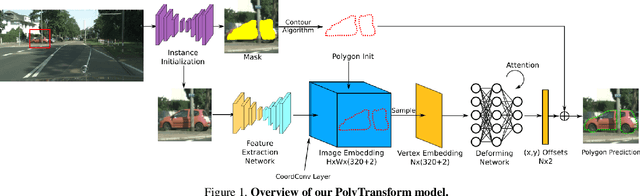
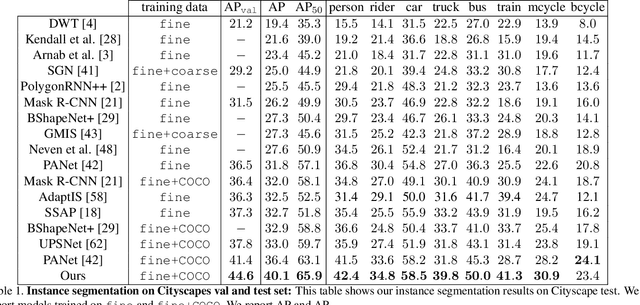
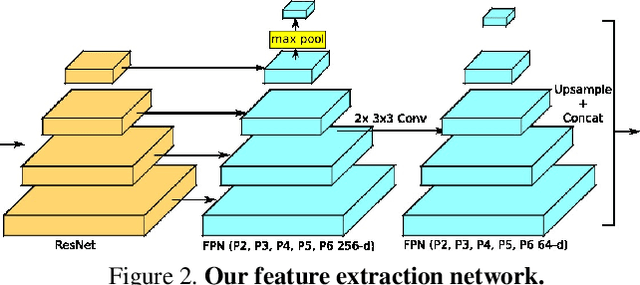

In this paper, we propose PolyTransform, a novel instance segmentation algorithm that produces precise, geometry-preserving masks by combining the strengths of prevailing segmentation approaches and modern polygon-based methods. In particular, we first exploit a segmentation network to generate instance masks. We then convert the masks into a set of polygons that are then fed to a deforming network that transforms the polygons such that they better fit the object boundaries. Our experiments on the challenging Cityscapes dataset show that our PolyTransform significantly improves the performance of the backbone instance segmentation network and ranks 1st on the Cityscapes test-set leaderboard. We also show impressive gains in the interactive annotation setting.
Identifying Unknown Instances for Autonomous Driving
Oct 24, 2019
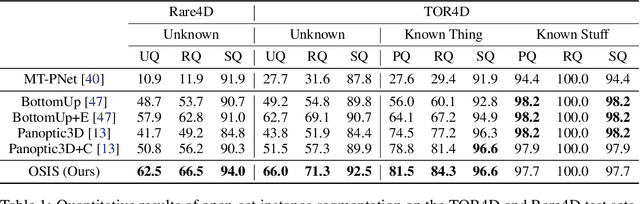
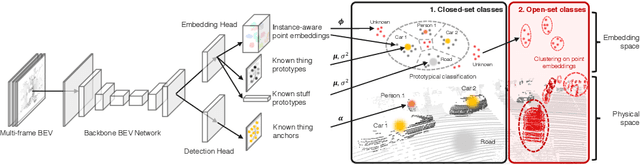
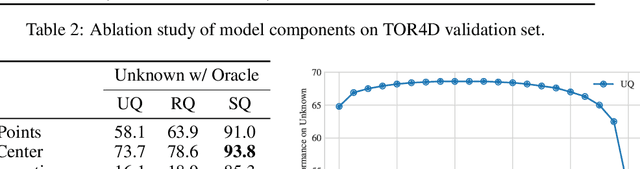
In the past few years, we have seen great progress in perception algorithms, particular through the use of deep learning. However, most existing approaches focus on a few categories of interest, which represent only a small fraction of the potential categories that robots need to handle in the real-world. Thus, identifying objects from unknown classes remains a challenging yet crucial task. In this paper, we develop a novel open-set instance segmentation algorithm for point clouds which can segment objects from both known and unknown classes in a holistic way. Our method uses a deep convolutional neural network to project points into a category-agnostic embedding space in which they can be clustered into instances irrespective of their semantics. Experiments on two large-scale self-driving datasets validate the effectiveness of our proposed method.
Spatially-Aware Graph Neural Networks for Relational Behavior Forecasting from Sensor Data
Oct 18, 2019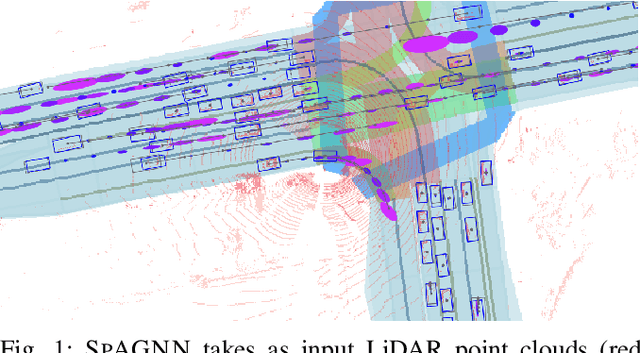
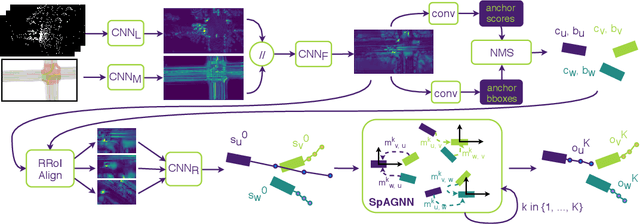
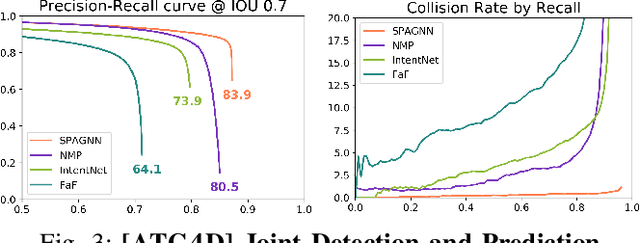
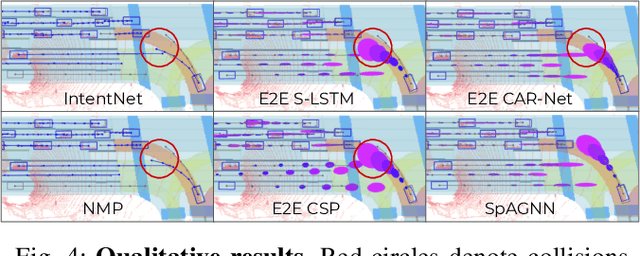
In this paper, we tackle the problem of relational behavior forecasting from sensor data. Towards this goal, we propose a novel spatially-aware graph neural network (SpAGNN) that models the interactions between agents in the scene. Specifically, we exploit a convolutional neural network to detect the actors and compute their initial states. A graph neural network then iteratively updates the actor states via a message passing process. Inspired by Gaussian belief propagation, we design the messages to be spatially-transformed parameters of the output distributions from neighboring agents. Our model is fully differentiable, thus enabling end-to-end training. Importantly, our probabilistic predictions can model uncertainty at the trajectory level. We demonstrate the effectiveness of our approach by achieving significant improvements over the state-of-the-art on two real-world self-driving datasets: ATG4D and nuScenes.
Discrete Residual Flow for Probabilistic Pedestrian Behavior Prediction
Oct 17, 2019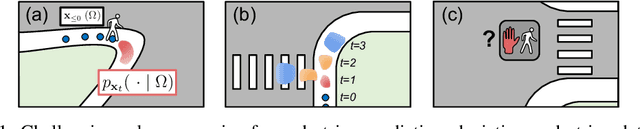
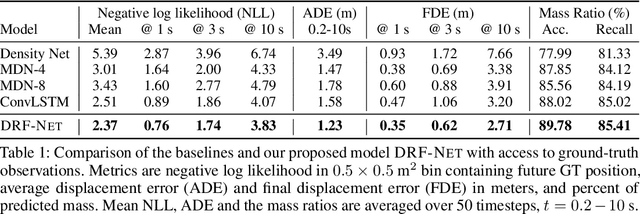
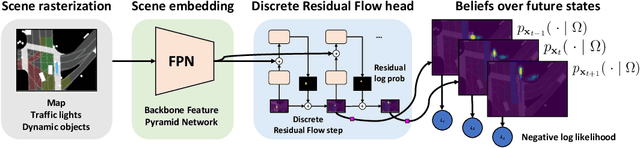
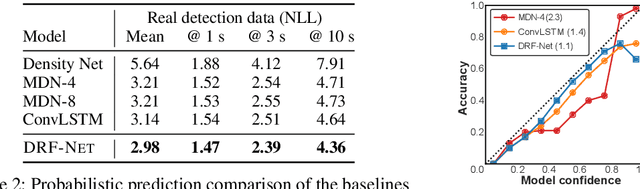
Self-driving vehicles plan around both static and dynamic objects, applying predictive models of behavior to estimate future locations of the objects in the environment. However, future behavior is inherently uncertain, and models of motion that produce deterministic outputs are limited to short timescales. Particularly difficult is the prediction of human behavior. In this work, we propose the discrete residual flow network (DRF-Net), a convolutional neural network for human motion prediction that captures the uncertainty inherent in long-range motion forecasting. In particular, our learned network effectively captures multimodal posteriors over future human motion by predicting and updating a discretized distribution over spatial locations. We compare our model against several strong competitors and show that our model outperforms all baselines.