 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded AI Companion System on Edge Devices
Jan 13, 2026Computational resource constraints on edge devices make it difficult to develop a fully embedded AI companion system with a satisfactory user experience. AI companion and memory systems detailed in existing literature cannot be directly used in such an environment due to lack of compute resources and latency concerns. In this paper, we propose a memory paradigm that alternates between active and inactive phases: during phases of user activity, the system performs low-latency, real-time dialog using lightweight retrieval over existing memories and context; whereas during phases of user inactivity, it conducts more computationally intensive extraction, consolidation, and maintenance of memories across full conversation sessions. This design minimizes latency while maintaining long-term personalization under the tight constraints of embedded hardware. We also introduce an AI Companion benchmark designed to holistically evaluate the AI Companion across both its conversational quality and memory capabilities. In our experiments, we found that our system (using a very weak model: Qwen2.5-7B-Instruct quantized int4) outperforms the equivalent raw LLM without memory across most metrics, and performs comparably to GPT-3.5 with 16k context window.
S&P 500 Stock's Movement Prediction using CNN
Dec 25, 2025



This paper is about predicting the movement of stock consist of S&P 500 index. Historically there are many approaches have been tried using various methods to predict the stock movement and being used in the market currently for algorithm trading and alpha generating systems using traditional mathematical approaches [1, 2]. The success of artificial neural network recently created a lot of interest and paved the way to enable prediction using cutting-edge research in the machine learning and deep learning. Some of these papers have done a great job in implementing and explaining benefits of these new technologies. Although most these papers do not go into the complexity of the financial data and mostly utilize single dimension data, still most of these papers were successful in creating the ground for future research in this comparatively new phenomenon. In this paper, I am trying to use multivariate raw data including stock split/dividend events (as-is) present in real-world market data instead of engineered financial data. Convolution Neural Network (CNN), the best-known tool so far for image classification, is used on the multi-dimensional stock numbers taken from the market mimicking them as a vector of historical data matrices (read images) and the model achieves promising results. The predictions can be made stock by stock, i.e., a single stock, sector-wise or for the portfolio of stocks.
* 9 pages, 19 diagrams. Originally submitted as a part of my Stanford University program taught by Dr. Fei Fei Lee and Andrej Karpathy CS231N 2018
From Narrow Unlearning to Emergent Misalignment: Causes, Consequences, and Containment in LLMs
Nov 18, 2025



Recent work has shown that fine-tuning on insecure code data can trigger an emergent misalignment (EMA) phenomenon, where models generate malicious responses even to prompts unrelated to the original insecure code-writing task. Such cross-domain generalization of harmful behavior underscores the need for a deeper understanding of the algorithms, tasks, and datasets that induce emergent misalignment. In this work, we extend this study by demonstrating that emergent misalignment can also arise from narrow refusal unlearning in specific domains. We perform refusal unlearning on Cybersecurity and Safety concept, and evaluate EMA by monitoring refusal scores across seven responsible AI (RAI) domains, Cybersecurity, Safety, Toxicity, Bias, Sensitive Content, Medical/Legal, and Privacy. Our work shows that narrow domain unlearning can yield compliance responses for the targeted concept, however, it may also propagate EMA to unrelated domains. Among the two intervened concepts, Cybersecurity and Safety, we find that the safety concept can have larger EMA impact, i.e, causing lower refusal scores, across other unrelated domains such as bias. We observe this effect consistently across two model families, Mistral-7b-0.3v, and Qwen-7b-2.5. Further, we show that refusal unlearning augmented with cross-entropy loss function on a small set of retain data from the affected domains can largely, if not fully, restore alignment across the impacted domains while having lower refusal rate on the concept we perform unlearning on. To investigate the underlying causes of EMA, we analyze concept entanglements at the representation level via concept vectors. Our analysis reveals that concepts with higher representation similarity in earlier layers are more susceptible to EMA after intervention when the refusal stream is altered through targeted refusal unlearning.
VMDT: Decoding the Trustworthiness of Video Foundation Models
Nov 07, 2025As foundation models become more sophisticated, ensuring their trustworthiness becomes increasingly critical; yet, unlike text and image, the video modality still lacks comprehensive trustworthiness benchmarks. We introduce VMDT (Video-Modal DecodingTrust), the first unified platform for evaluating text-to-video (T2V) and video-to-text (V2T) models across five key trustworthiness dimensions: safety, hallucination, fairness, privacy, and adversarial robustness. Through our extensive evaluation of 7 T2V models and 19 V2T models using VMDT, we uncover several significant insights. For instance, all open-source T2V models evaluated fail to recognize harmful queries and often generate harmful videos, while exhibiting higher levels of unfairness compared to image modality models. In V2T models, unfairness and privacy risks rise with scale, whereas hallucination and adversarial robustness improve -- though overall performance remains low. Uniquely, safety shows no correlation with model size, implying that factors other than scale govern current safety levels. Our findings highlight the urgent need for developing more robust and trustworthy video foundation models, and VMDT provides a systematic framework for measuring and tracking progress toward this goal. The code is available at https://sunblaze-ucb.github.io/VMDT-page/.
Amazon Nova AI Challenge -- Trusted AI: Advancing secure, AI-assisted software development
Aug 13, 2025AI systems for software development are rapidly gaining prominence, yet significant challenges remain in ensuring their safety. To address this, Amazon launched the Trusted AI track of the Amazon Nova AI Challenge, a global competition among 10 university teams to drive advances in secure AI. In the challenge, five teams focus on developing automated red teaming bots, while the other five create safe AI assistants. This challenge provides teams with a unique platform to evaluate automated red-teaming and safety alignment methods through head-to-head adversarial tournaments where red teams have multi-turn conversations with the competing AI coding assistants to test their safety alignment. Along with this, the challenge provides teams with a feed of high quality annotated data to fuel iterative improvement. Throughout the challenge, teams developed state-of-the-art techniques, introducing novel approaches in reasoning-based safety alignment, robust model guardrails, multi-turn jail-breaking, and efficient probing of large language models (LLMs). To support these efforts, the Amazon Nova AI Challenge team made substantial scientific and engineering investments, including building a custom baseline coding specialist model for the challenge from scratch, developing a tournament orchestration service, and creating an evaluation harness. This paper outlines the advancements made by university teams and the Amazon Nova AI Challenge team in addressing the safety challenges of AI for software development, highlighting this collaborative effort to raise the bar for AI safety.
Retrieval-Augmented Multi-Agent System for Rapid Statement of Work Generation
Aug 11, 2025Drafting a Statement of Work (SOW) is a vital part of business and legal projects. It outlines key details like deliverables, timelines, responsibilities, and legal terms. However, creating these documents is often a slow and complex process. It usually involves multiple people, takes several days, and leaves room for errors or outdated content. This paper introduces a new AI-driven automation system that makes the entire SOW drafting process faster, easier, and more accurate. Instead of relying completely on humans, the system uses three intelligent components or 'agents' that each handle a part of the job. One agent writes the first draft, another checks if everything is legally correct, and the third agent formats the document and ensures everything is in order. Unlike basic online tools that just fill in templates, this system understands the meaning behind the content and customizes the SOW to match the needs of the project. It also checks legal compliance and formatting so that users can trust the result. The system was tested using real business examples. It was able to create a full SOW in under three minutes, compared to several hours or days using manual methods. It also performed well in accuracy and quality, showing that it can reduce legal risks and save a lot of time. This solution shows how artificial intelligence can be used to support legal and business professionals by taking care of routine work and helping them focus on more important decisions. It's a step toward making legal processes smarter, faster, and more reliable.
Customize Multi-modal RAI Guardrails with Precedent-based predictions
Jul 28, 2025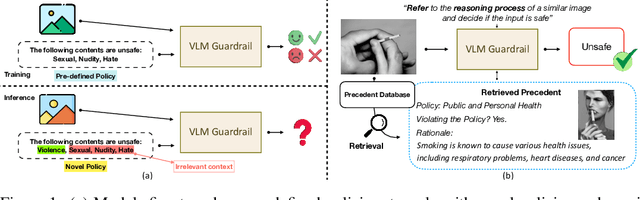
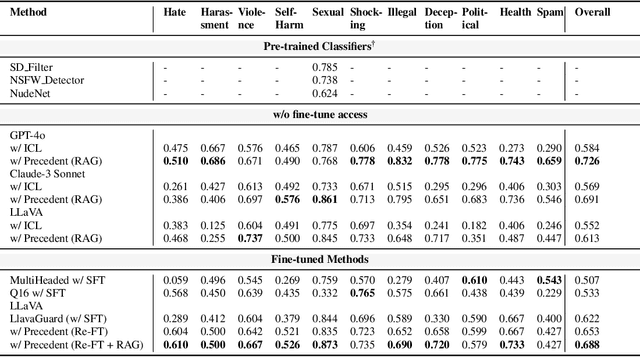
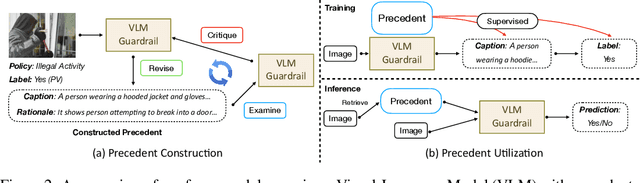
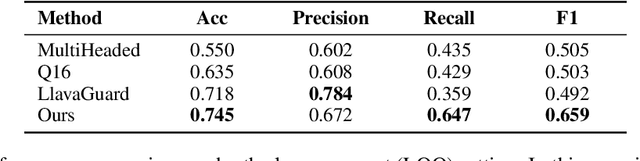
A multi-modal guardrail must effectively filter image content based on user-defined policies, identifying material that may be hateful, reinforce harmful stereotypes, contain explicit material, or spread misinformation. Deploying such guardrails in real-world applications, however, poses significant challenges. Users often require varied and highly customizable policies and typically cannot provide abundant examples for each custom policy. Consequently, an ideal guardrail should be scalable to the multiple policies and adaptable to evolving user standards with minimal retraining. Existing fine-tuning methods typically condition predictions on pre-defined policies, restricting their generalizability to new policies or necessitating extensive retraining to adapt. Conversely, training-free methods struggle with limited context lengths, making it difficult to incorporate all the policies comprehensively. To overcome these limitations, we propose to condition model's judgment on "precedents", which are the reasoning processes of prior data points similar to the given input. By leveraging precedents instead of fixed policies, our approach greatly enhances the flexibility and adaptability of the guardrail. In this paper, we introduce a critique-revise mechanism for collecting high-quality precedents and two strategies that utilize precedents for robust prediction. Experimental results demonstrate that our approach outperforms previous methods across both few-shot and full-dataset scenarios and exhibits superior generalization to novel policies.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025



Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
Towards Safety Reasoning in LLMs: AI-agentic Deliberation for Policy-embedded CoT Data Creation
May 27, 2025Safety reasoning is a recent paradigm where LLMs reason over safety policies before generating responses, thereby mitigating limitations in existing safety measures such as over-refusal and jailbreak vulnerabilities. However, implementing this paradigm is challenging due to the resource-intensive process of creating high-quality policy-embedded chain-of-thought (CoT) datasets while ensuring reasoning remains accurate and free from hallucinations or policy conflicts. To tackle this, we propose AIDSAFE: Agentic Iterative Deliberation for Safety Reasoning, a novel data generation recipe that leverages multi-agent deliberation to iteratively expand reasoning on safety policies. A data refiner stage in AIDSAFE ensures high-quality outputs by eliminating repetitive, redundant, and deceptive thoughts. AIDSAFE-generated CoTs provide a strong foundation for supervised fine-tuning (SFT)-based safety training. Additionally, to address the need of preference data in alignment stages, such as DPO training, we introduce a supplemental recipe that uses belief augmentation to create distinct selected and rejected CoT samples. Our evaluations demonstrate that AIDSAFE-generated CoTs achieve superior policy adherence and reasoning quality. Consequently, we show that fine-tuning open-source LLMs on these CoTs can significantly improve safety generalization and jailbreak robustness while maintaining acceptable utility and over-refusal accuracy. AIDSAFE-generated CoT datasets can be found here: https://huggingface.co/datasets/AmazonScience/AIDSAFE
Strategize Globally, Adapt Locally: A Multi-Turn Red Teaming Agent with Dual-Level Learning
Apr 02, 2025The exploitation of large language models (LLMs) for malicious purposes poses significant security risks as these models become more powerful and widespread. While most existing red-teaming frameworks focus on single-turn attacks, real-world adversaries typically operate in multi-turn scenarios, iteratively probing for vulnerabilities and adapting their prompts based on threat model responses. In this paper, we propose \AlgName, a novel multi-turn red-teaming agent that emulates sophisticated human attackers through complementary learning dimensions: global tactic-wise learning that accumulates knowledge over time and generalizes to new attack goals, and local prompt-wise learning that refines implementations for specific goals when initial attempts fail. Unlike previous multi-turn approaches that rely on fixed strategy sets, \AlgName enables the agent to identify new jailbreak tactics, develop a goal-based tactic selection framework, and refine prompt formulations for selected tactics. Empirical evaluations on JailbreakBench demonstrate our framework's superior performance, achieving over 90\% attack success rates against GPT-3.5-Turbo and Llama-3.1-70B within 5 conversation turns, outperforming state-of-the-art baselines. These results highlight the effectiveness of dynamic learning in identifying and exploiting model vulnerabilities in realistic multi-turn scenarios.