 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Adversarial Computer Programs using Optimized Obfuscations
Mar 18, 2021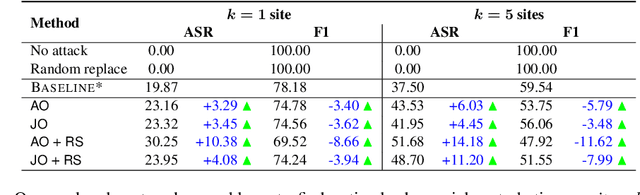

Machine learning (ML) models that learn and predict properties of computer programs are increasingly being adopted and deployed. These models have demonstrated success in applications such as auto-completing code, summarizing large programs, and detecting bugs and malware in programs. In this work, we investigate principled ways to adversarially perturb a computer program to fool such learned models, and thus determine their adversarial robustness. We use program obfuscations, which have conventionally been used to avoid attempts at reverse engineering programs, as adversarial perturbations. These perturbations modify programs in ways that do not alter their functionality but can be crafted to deceive an ML model when making a decision. We provide a general formulation for an adversarial program that allows applying multiple obfuscation transformations to a program in any language. We develop first-order optimization algorithms to efficiently determine two key aspects -- which parts of the program to transform, and what transformations to use. We show that it is important to optimize both these aspects to generate the best adversarially perturbed program. Due to the discrete nature of this problem, we also propose using randomized smoothing to improve the attack loss landscape to ease optimization. We evaluate our work on Python and Java programs on the problem of program summarization. We show that our best attack proposal achieves a $52\%$ improvement over a state-of-the-art attack generation approach for programs trained on a seq2seq model. We further show that our formulation is better at training models that are robust to adversarial attacks.
Deep Analysis of CNN-based Spatio-temporal Representations for Action Recognition
Oct 23, 2020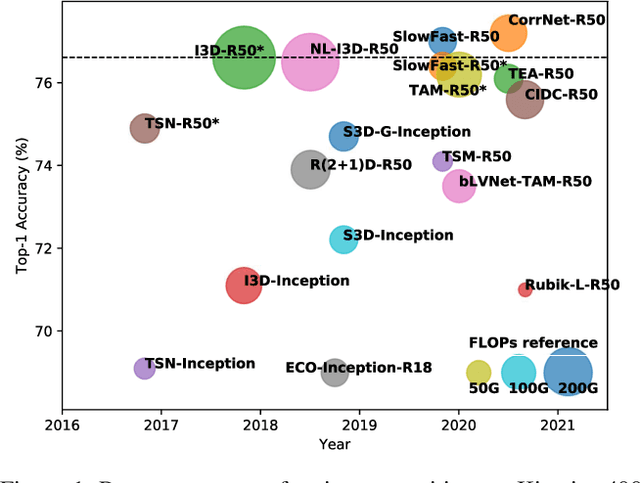
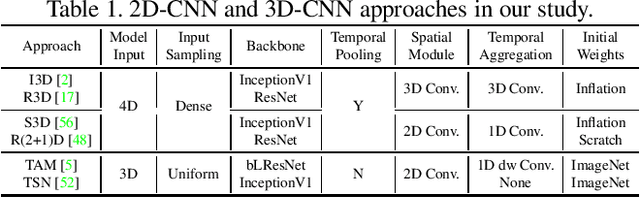
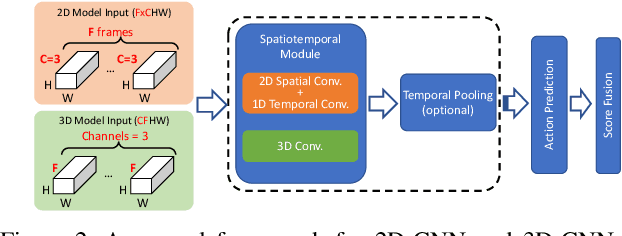
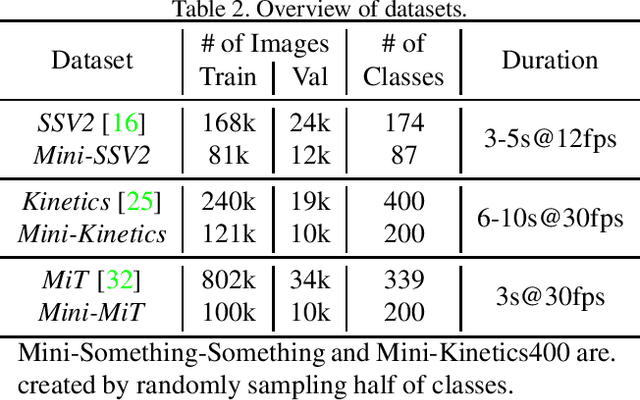
In recent years, a number of approaches based on 2D CNNs and 3D CNNs have emerged for video action recognition, achieving state-of-the-art results on several large-scale benchmark datasets. In this paper, we carry out an in-depth comparative analysis to better understand the differences between these approaches and the progress made by them. To this end, we develop a unified framework for both 2D-CNN and 3D-CNN action models, which enables us to remove bells and whistles and provides a common ground for a fair comparison. We then conduct an effort towards a large-scale analysis involving over 300 action recognition models. Our comprehensive analysis reveals that a) a significant leap is made in efficiency for action recognition, but not in accuracy; b) 2D-CNN and 3D-CNN models behave similarly in terms of spatio-temporal representation abilities and transferability. Our analysis also shows that recent action models seem to be able to learn data-dependent temporality flexibly as needed. Our codes and models are available on https://github.com/IBM/action-recognition-pytorch.
More Is Less: Learning Efficient Video Representations by Big-Little Network and Depthwise Temporal Aggregation
Dec 02, 2019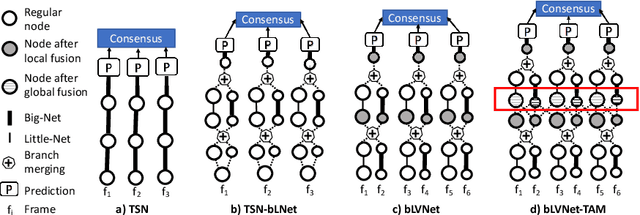
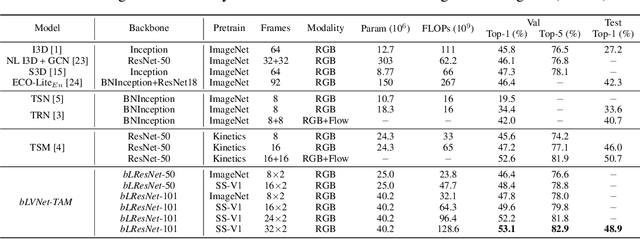
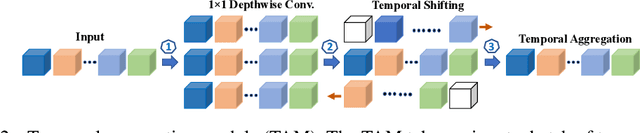
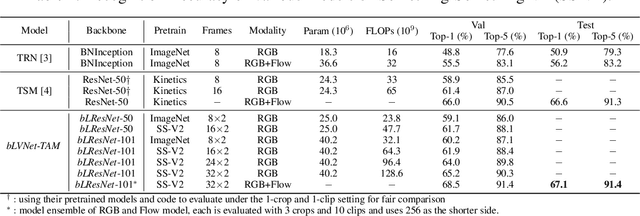
Current state-of-the-art models for video action recognition are mostly based on expensive 3D ConvNets. This results in a need for large GPU clusters to train and evaluate such architectures. To address this problem, we present a lightweight and memory-friendly architecture for action recognition that performs on par with or better than current architectures by using only a fraction of resources. The proposed architecture is based on a combination of a deep subnet operating on low-resolution frames with a compact subnet operating on high-resolution frames, allowing for high efficiency and accuracy at the same time. We demonstrate that our approach achieves a reduction by $3\sim4$ times in FLOPs and $\sim2$ times in memory usage compared to the baseline. This enables training deeper models with more input frames under the same computational budget. To further obviate the need for large-scale 3D convolutions, a temporal aggregation module is proposed to model temporal dependencies in a video at very small additional computational costs. Our models achieve strong performance on several action recognition benchmarks including Kinetics, Something-Something and Moments-in-time. The code and models are available at https://github.com/IBM/bLVNet-TAM.
Adversarial T-shirt! Evading Person Detectors in A Physical World
Nov 27, 2019It is known that deep neural networks (DNNs) are vulnerable to adversarial attacks. The so-called physical adversarial examples deceive DNN-based decision makers by attaching adversarial patches to real objects. However, most of the existing works on physical adversarial attacks focus on static objects such as glass frames, stop signs and images attached to cardboard. In this work, we propose Adversarial T-shirts, a robust physical adversarial example for evading person detectors even if it could undergo non-rigid deformation due to a moving person's pose changes. To the best of our knowledge, this is the first work that models the effect of deformation for designing physical adversarial examples with respect to non-rigid objects such as T-shirts. We show that the proposed method achieves 74% and 57% attack success rates in digital and physical worlds respectively against YOLOv2. In contrast, the state-of-the-art physical attack method to fool a person detector only achieves 18% attack success rate. Furthermore, by leveraging min-max optimization, we extend our method to the ensemble attack setting against two object detectors YOLO-v2 and Faster R-CNN simultaneously.
Multi-Moments in Time: Learning and Interpreting Models for Multi-Action Video Understanding
Nov 04, 2019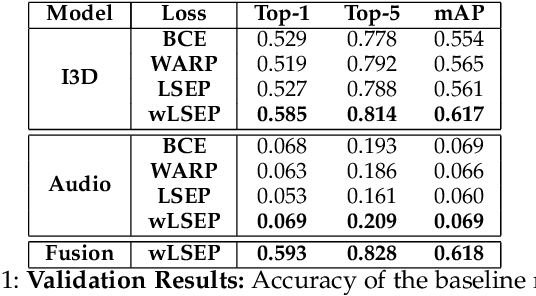
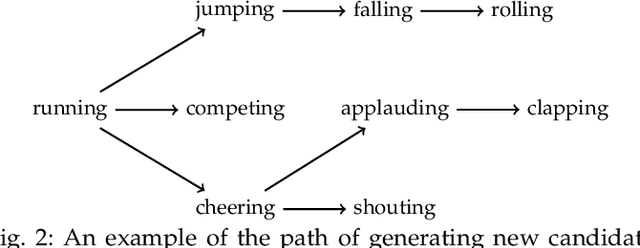


An event happening in the world is often made of different activities and actions that can unfold simultaneously or sequentially within a few seconds. However, most large-scale datasets built to train models for action recognition provide a single label per video clip. Consequently, models can be incorrectly penalized for classifying actions that exist in the videos but are not explicitly labeled and do not learn the full spectrum of information that would be mandatory to more completely comprehend different events and eventually learn causality between them. Towards this goal, we augmented the existing video dataset, Moments in Time (MiT), to include over two million action labels for over one million three second videos. This multi-label dataset introduces novel challenges on how to train and analyze models for multi-action detection. Here, we present baseline results for multi-action recognition using loss functions adapted for long tail multi-label learning and provide improved methods for visualizing and interpreting models trained for multi-label action detection.
Reasoning About Human-Object Interactions Through Dual Attention Networks
Sep 10, 2019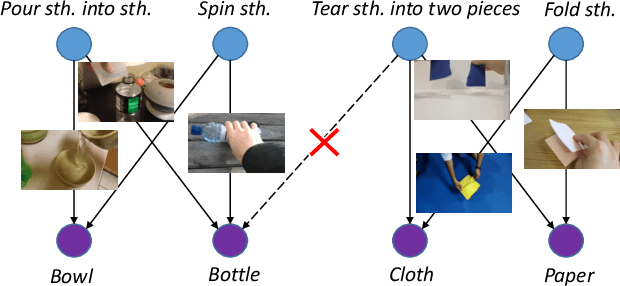

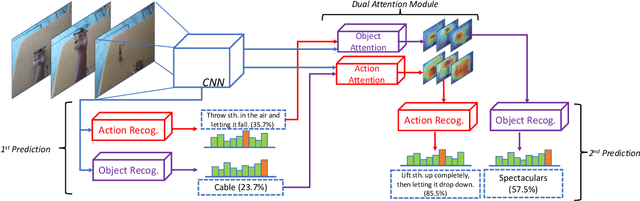
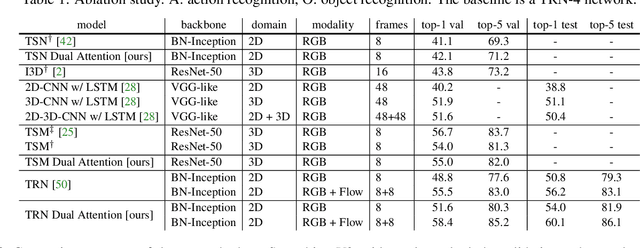
Objects are entities we act upon, where the functionality of an object is determined by how we interact with it. In this work we propose a Dual Attention Network model which reasons about human-object interactions. The dual-attentional framework weights the important features for objects and actions respectively. As a result, the recognition of objects and actions mutually benefit each other. The proposed model shows competitive classification performance on the human-object interaction dataset Something-Something. Besides, it can perform weak spatiotemporal localization and affordance segmentation, despite being trained only with video-level labels. The model not only finds when an action is happening and which object is being manipulated, but also identifies which part of the object is being interacted with. Project page: \url{https://dual-attention-network.github.io/}.
Interpreting Adversarial Examples by Activation Promotion and Suppression
Apr 03, 2019
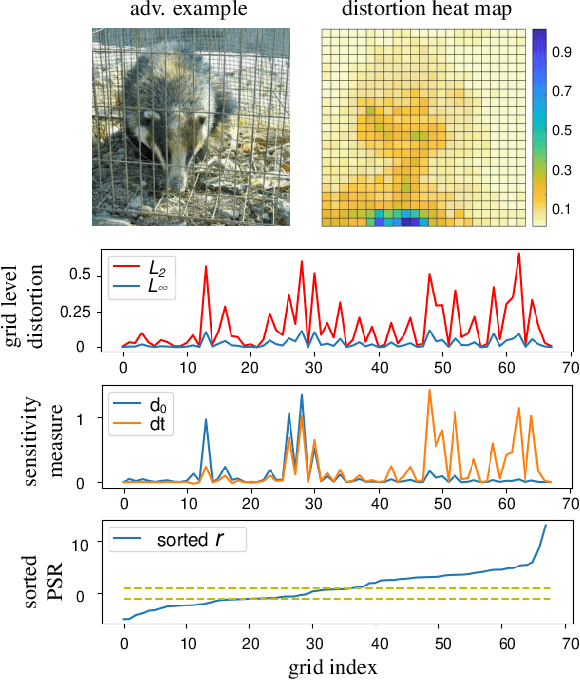

It is widely known that convolutional neural networks (CNNs) are vulnerable to adversarial examples: crafted images with imperceptible perturbations. However, interpretability of these perturbations is less explored in the literature. This work aims to better understand the roles of adversarial perturbations and provide visual explanations from pixel, image and network perspectives. We show that adversaries make a promotion and suppression effect (PSE) on neurons' activation and can be primarily categorized into three types: 1)suppression-dominated perturbations that mainly reduce the classification score of the true label, 2)promotion-dominated perturbations that focus on boosting the confidence of the target label, and 3)balanced perturbations that play a dual role on suppression and promotion. Further, we provide the image-level interpretability of adversarial examples, which links PSE of pixel-level perturbations to class-specific discriminative image regions localized by class activation mapping. Lastly, we analyze the effect of adversarial examples through network dissection, which offers concept-level interpretability of hidden units. We show that there exists a tight connection between the sensitivity (against attacks) of internal response of units with their interpretability on semantic concepts.
Structured Adversarial Attack: Towards General Implementation and Better Interpretability
Oct 04, 2018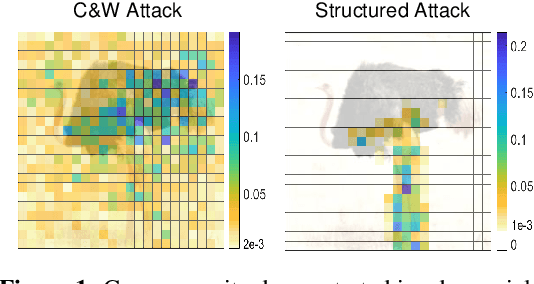
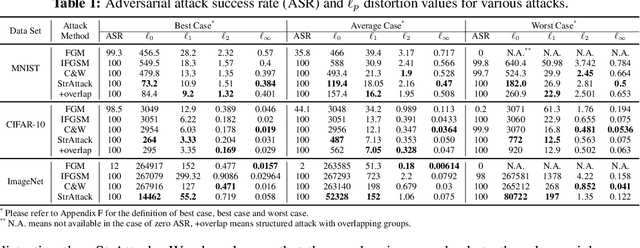
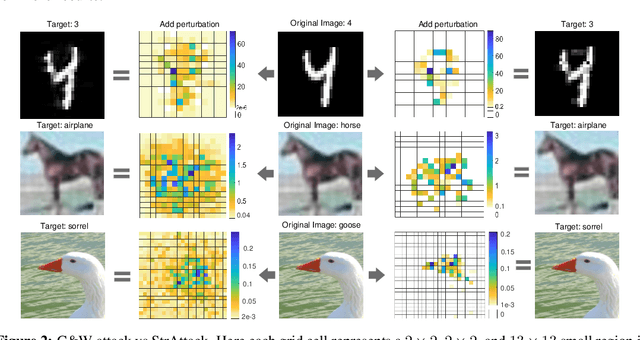

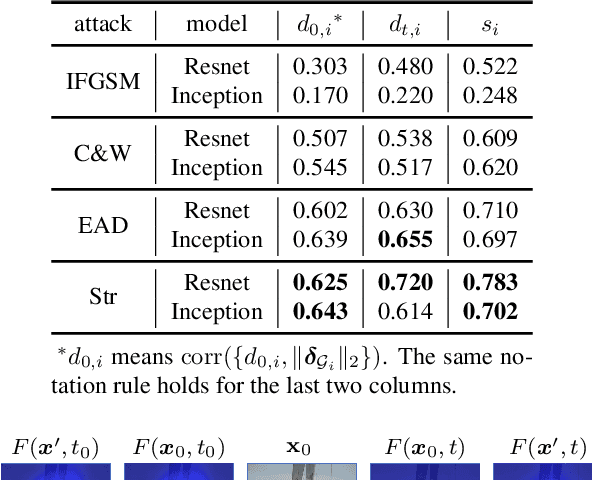
When generating adversarial examples to attack deep neural networks (DNNs), Lp norm of the added perturbation is usually used to measure the similarity between original image and adversarial example. However, such adversarial attacks perturbing the raw input spaces may fail to capture structural information hidden in the input. This work develops a more general attack model, i.e., the structured attack (StrAttack), which explores group sparsity in adversarial perturbations by sliding a mask through images aiming for extracting key spatial structures. An ADMM (alternating direction method of multipliers)-based framework is proposed that can split the original problem into a sequence of analytically solvable subproblems and can be generalized to implement other attacking methods. Strong group sparsity is achieved in adversarial perturbations even with the same level of Lp norm distortion as the state-of-the-art attacks. We demonstrate the effectiveness of StrAttack by extensive experimental results onMNIST, CIFAR-10, and ImageNet. We also show that StrAttack provides better interpretability (i.e., better correspondence with discriminative image regions)through adversarial saliency map (Papernot et al., 2016b) and class activation map(Zhou et al., 2016).
Efficient Fusion of Sparse and Complementary Convolutions
Sep 11, 2018
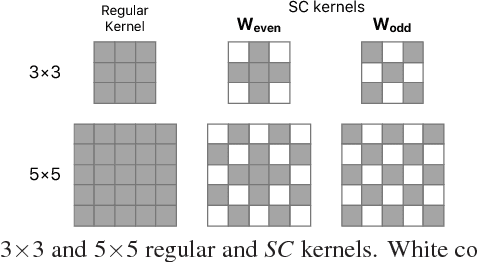

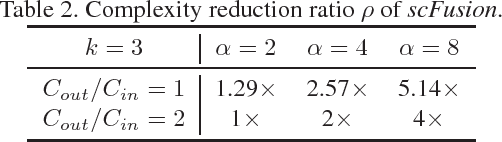
We propose a new method to create compact convolutional neural networks (CNNs) by exploiting sparse convolutions. Different from previous works that learn sparsity in models, we directly employ hand-crafted kernels with regular sparse patterns, which result in the computational gain in practice without sophisticated and dedicated software or hardware. The core of our approach is an efficient network module that linearly combines sparse kernels to yield feature representations as strong as those from regular kernels. We integrate this module into various network architectures and demonstrate its effectiveness on three vision tasks, object classification, localization and detection. For object classification and localization, our approach achieves comparable or better performance than several baselines and related works while providing lower computational costs with fewer parameters (on average, a $2-4\times$ reduction of convolutional parameters and computation). For object detection, our approach leads to a VGG-16-based Faster RCNN detector that is 12.4$\times$ smaller and about 3$\times$ faster than the baseline.
Big-Little Net: An Efficient Multi-Scale Feature Representation for Visual and Speech Recognition
Jul 10, 2018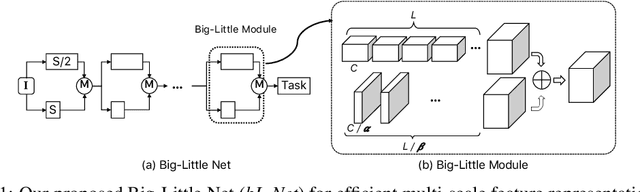
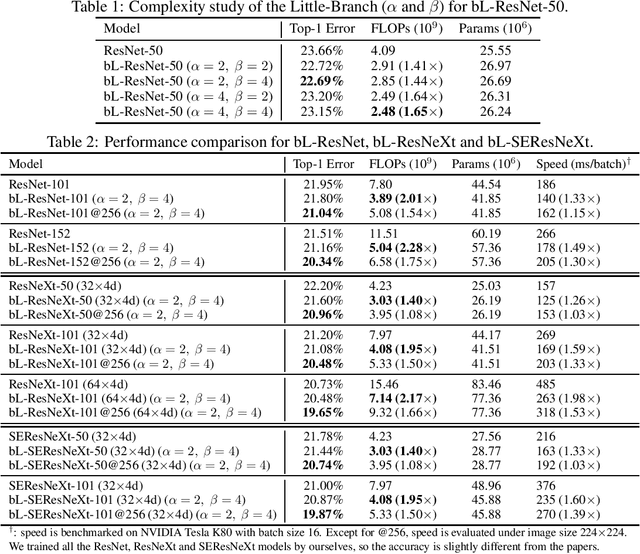
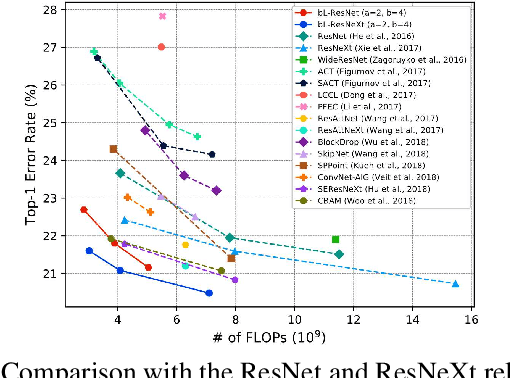
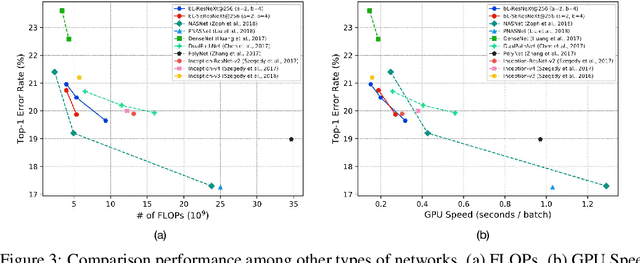
In this paper, we propose a novel Convolutional Neural Network (CNN) architecture for learning multi-scale feature representations with good tradeoffs between speed and accuracy. This is achieved by using a multi-branch network, which has different computational complexity at different branches. Through frequent merging of features from branches at distinct scales, our model obtains multi-scale features while using less computation. The proposed approach demonstrates improvement of model efficiency and performance on both object recognition and speech recognition tasks,using popular architectures including ResNet and ResNeXt. For object recognition, our approach reduces computation by 33% on object recognition while improving accuracy with 0.9%. Furthermore, our model surpasses state-of-the-art CNN acceleration approaches by a large margin in accuracy and FLOPs reduction. On the task of speech recognition, our proposed multi-scale CNNs save 30% FLOPs with slightly better word error rates, showing good generalization across domains.