 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Goes beyond Multi-modal Fusion in One-stage Referring Expression Comprehension: An Empirical Study
Apr 17, 2022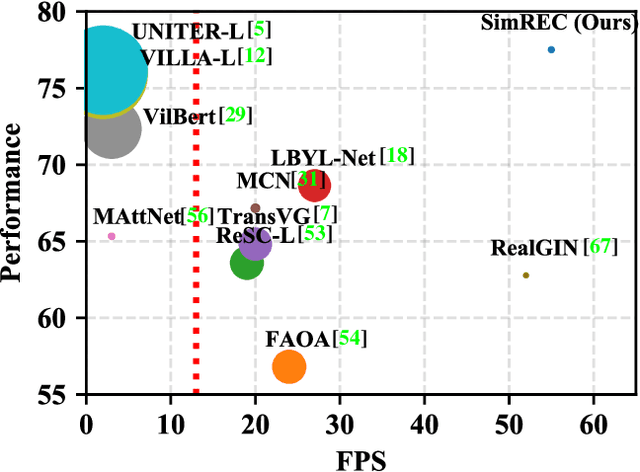
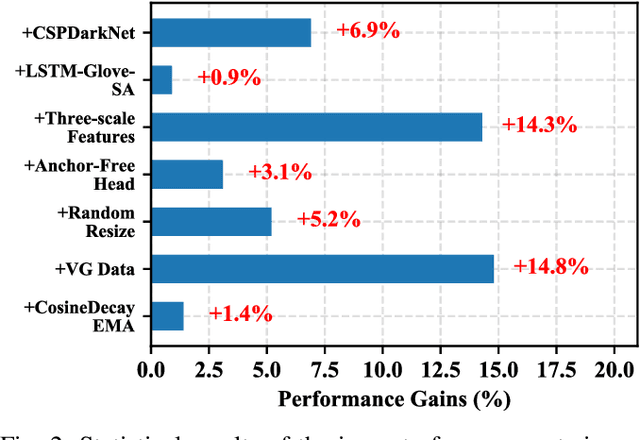
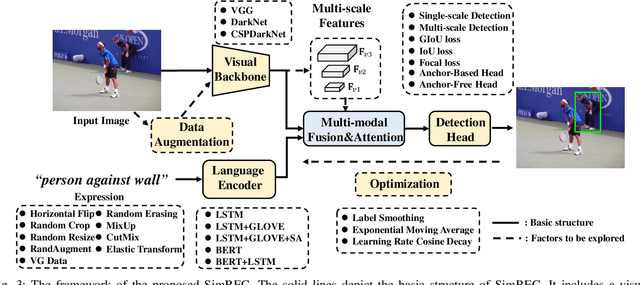
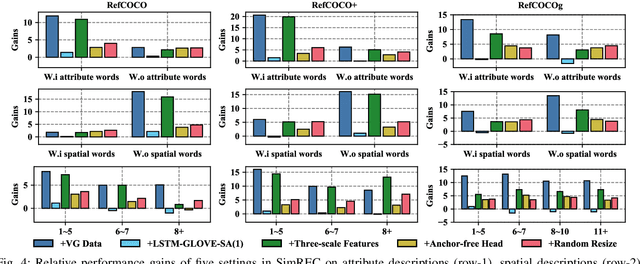
Most of the existing work in one-stage referring expression comprehension (REC) mainly focuses on multi-modal fusion and reasoning, while the influence of other factors in this task lacks in-depth exploration. To fill this gap, we conduct an empirical study in this paper. Concretely, we first build a very simple REC network called SimREC, and ablate 42 candidate designs/settings, which covers the entire process of one-stage REC from network design to model training. Afterwards, we conduct over 100 experimental trials on three benchmark datasets of REC. The extensive experimental results not only show the key factors that affect REC performance in addition to multi-modal fusion, e.g., multi-scale features and data augmentation, but also yield some findings that run counter to conventional understanding. For example, as a vision and language (V&L) task, REC does is less impacted by language prior. In addition, with a proper combination of these findings, we can improve the performance of SimREC by a large margin, e.g., +27.12% on RefCOCO+, which outperforms all existing REC methods. But the most encouraging finding is that with much less training overhead and parameters, SimREC can still achieve better performance than a set of large-scale pre-trained models, e.g., UNITER and VILLA, portraying the special role of REC in existing V&L research.
Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
Mar 27, 2022


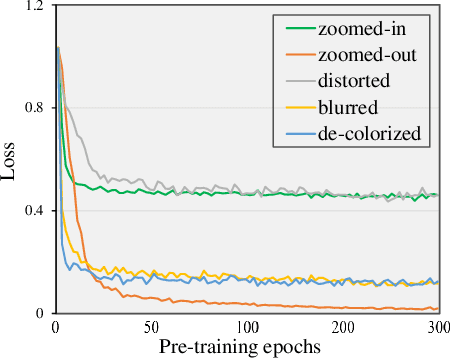
The past year has witnessed a rapid development of masked image modeling (MIM). MIM is mostly built upon the vision transformers, which suggests that self-supervised visual representations can be done by masking input image parts while requiring the target model to recover the missing contents. MIM has demonstrated promising results on downstream tasks, yet we are interested in whether there exist other effective ways to `learn by recovering missing contents'. In this paper, we investigate this topic by designing five other learning objectives that follow the same procedure as MIM but degrade the input image in different ways. With extensive experiments, we manage to summarize a few design principles for token-based pre-training of vision transformers. In particular, the best practice is obtained by keeping the original image style and enriching spatial masking with spatial misalignment -- this design achieves superior performance over MIM in a series of downstream recognition tasks without extra computational cost. The code is available at https://github.com/sunsmarterjie/beyond_masking.
Object Localization under Single Coarse Point Supervision
Mar 17, 2022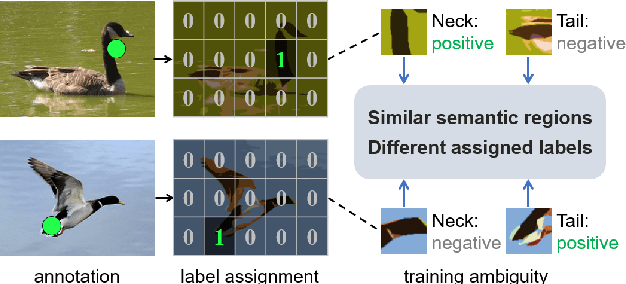
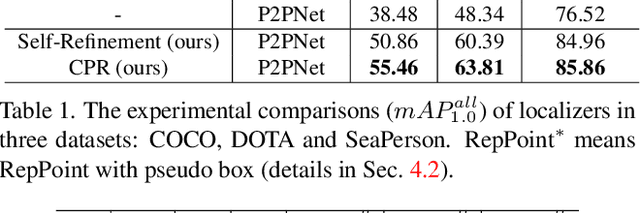

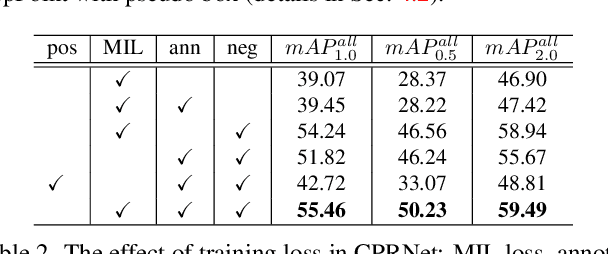
Point-based object localization (POL), which pursues high-performance object sensing under low-cost data annotation, has attracted increased attention. However, the point annotation mode inevitably introduces semantic variance for the inconsistency of annotated points. Existing POL methods heavily reply on accurate key-point annotations which are difficult to define. In this study, we propose a POL method using coarse point annotations, relaxing the supervision signals from accurate key points to freely spotted points. To this end, we propose a coarse point refinement (CPR) approach, which to our best knowledge is the first attempt to alleviate semantic variance from the perspective of algorithm. CPR constructs point bags, selects semantic-correlated points, and produces semantic center points through multiple instance learning (MIL). In this way, CPR defines a weakly supervised evolution procedure, which ensures training high-performance object localizer under coarse point supervision. Experimental results on COCO, DOTA and our proposed SeaPerson dataset validate the effectiveness of the CPR approach. The dataset and code will be available at https://github.com/ucas-vg/PointTinyBenchmark/.
Global2Local: A Joint-Hierarchical Attention for Video Captioning
Mar 13, 2022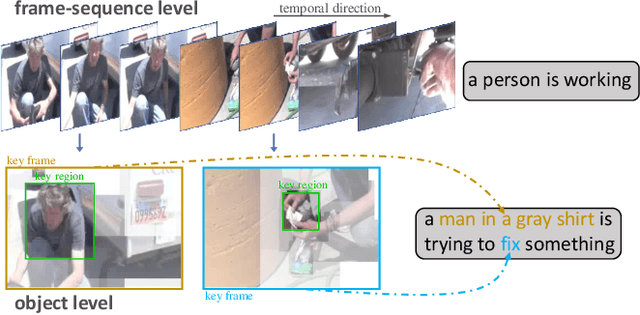
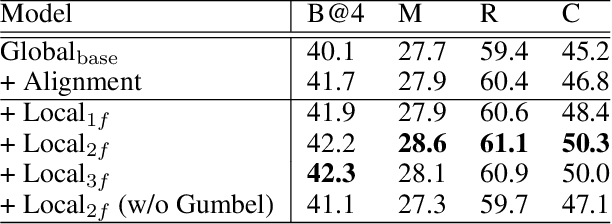
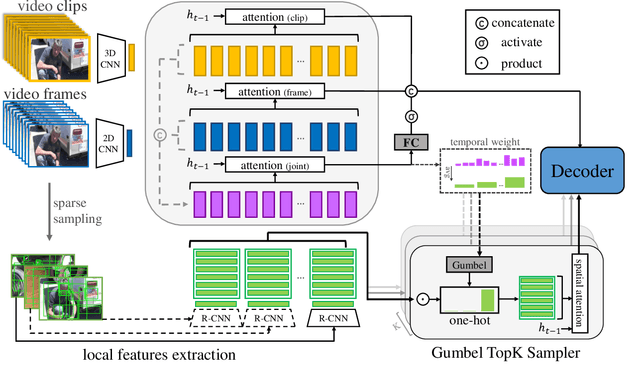
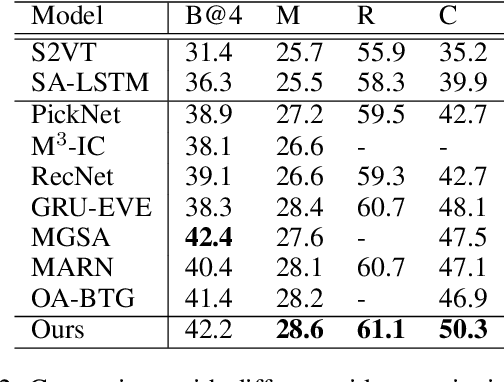
Recently, automatic video captioning has attracted increasing attention, where the core challenge lies in capturing the key semantic items, like objects and actions as well as their spatial-temporal correlations from the redundant frames and semantic content. To this end, existing works select either the key video clips in a global level~(across multi frames), or key regions within each frame, which, however, neglect the hierarchical order, i.e., key frames first and key regions latter. In this paper, we propose a novel joint-hierarchical attention model for video captioning, which embeds the key clips, the key frames and the key regions jointly into the captioning model in a hierarchical manner. Such a joint-hierarchical attention model first conducts a global selection to identify key frames, followed by a Gumbel sampling operation to identify further key regions based on the key frames, achieving an accurate global-to-local feature representation to guide the captioning. Extensive quantitative evaluations on two public benchmark datasets MSVD and MSR-VTT demonstrates the superiority of the proposed method over the state-of-the-art methods.
Mitigating the Mutual Error Amplification for Semi-Supervised Object Detection
Jan 26, 2022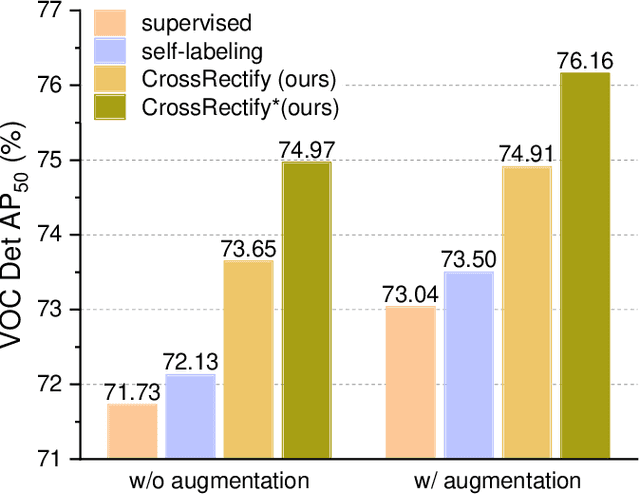
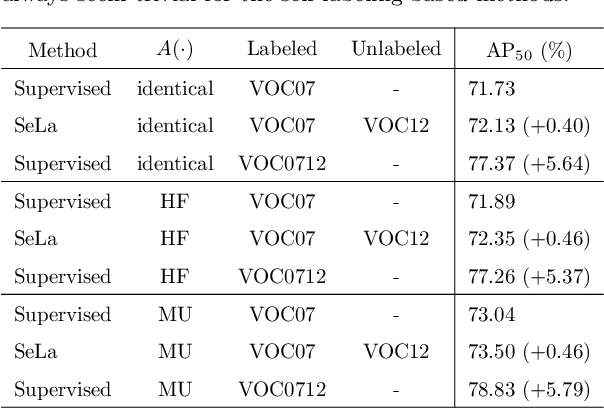
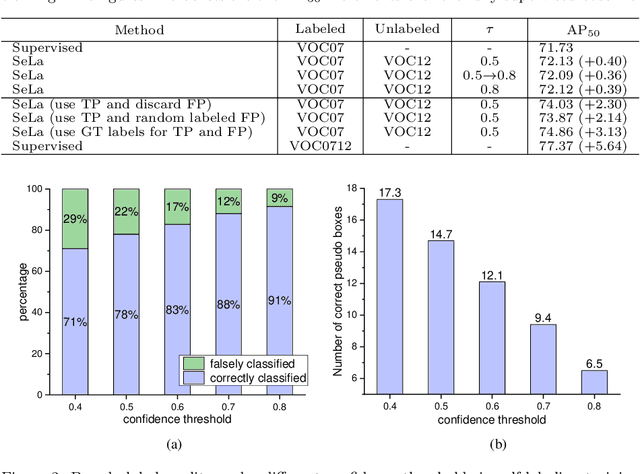
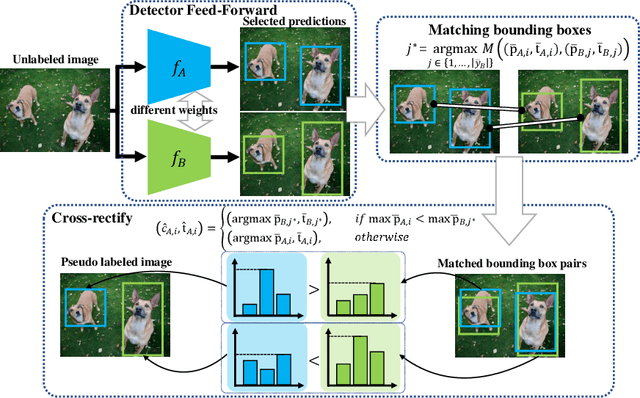
Semi-supervised object detection (SSOD) has achieved substantial progress in recent years. However, it is observed that the performances of self-labeling SSOD methods remain limited. Based on our experimental analysis, we reveal that the reason behind such phenomenon lies in the mutual error amplification between the pseudo labels and the trained detector. In this study, we propose a Cross Teaching (CT) method, aiming to mitigate the mutual error amplification by introducing a rectification mechanism of pseudo labels. CT simultaneously trains multiple detectors with an identical structure but different parameter initialization. In contrast to existing mutual teaching methods that directly treat predictions from other detectors as pseudo labels, we propose the Label Rectification Module (LRM), where the bounding boxes predicted by one detector are rectified by using the corresponding boxes predicted by all other detectors with higher confidence scores. In this way, CT can enhance the pseudo label quality compared with self-labeling and existing mutual teaching methods, and reasonably mitigate the mutual error amplification. Over two popular detector structures, i.e., SSD300 and Faster-RCNN-FPN, the proposed CT method obtains consistent improvements and outperforms the state-of-the-art SSOD methods by 2.2% absolute mAP improvements on the Pascal VOC and MS-COCO benchmarks. The code is available at github.com/machengcheng2016/CrossTeaching-SSOD.
P2P-Loc: Point to Point Tiny Person Localization
Jan 05, 2022

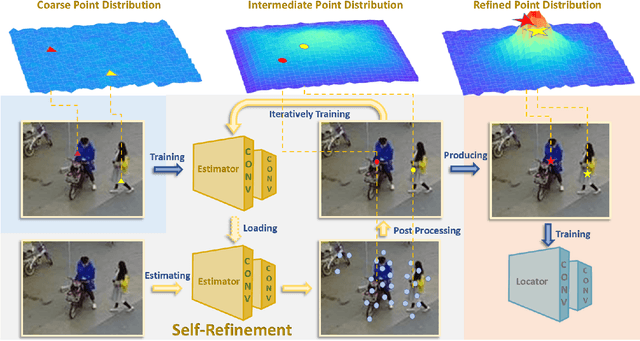

Bounding-box annotation form has been the most frequently used method for visual object localization tasks. However, bounding-box annotation relies on a large amount of precisely annotating bounding boxes, and it is expensive and laborious. It is impossible to be employed in practical scenarios and even redundant for some applications (such as tiny person localization) that the size would not matter. Therefore, we propose a novel point-based framework for the person localization task by annotating each person as a coarse point (CoarsePoint) instead of an accurate bounding box that can be any point within the object extent. Then, the network predicts the person's location as a 2D coordinate in the image. Although this greatly simplifies the data annotation pipeline, the CoarsePoint annotation inevitably decreases label reliability (label uncertainty) and causes network confusion during training. As a result, we propose a point self-refinement approach that iteratively updates point annotations in a self-paced way. The proposed refinement system alleviates the label uncertainty and progressively improves localization performance. Experimental results show that our approach has achieved comparable object localization performance while saving up to 80$\%$ of annotation cost.
Exploring Complicated Search Spaces with Interleaving-Free Sampling
Dec 05, 2021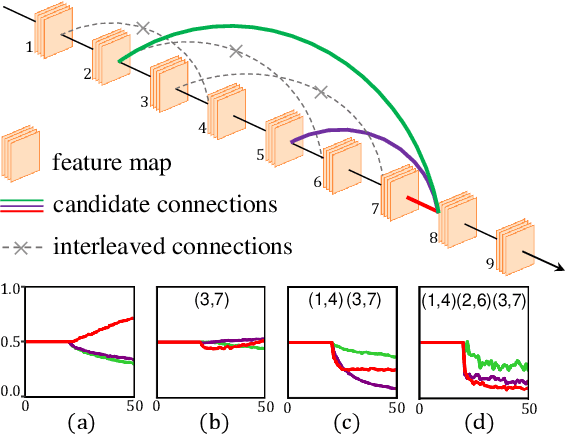


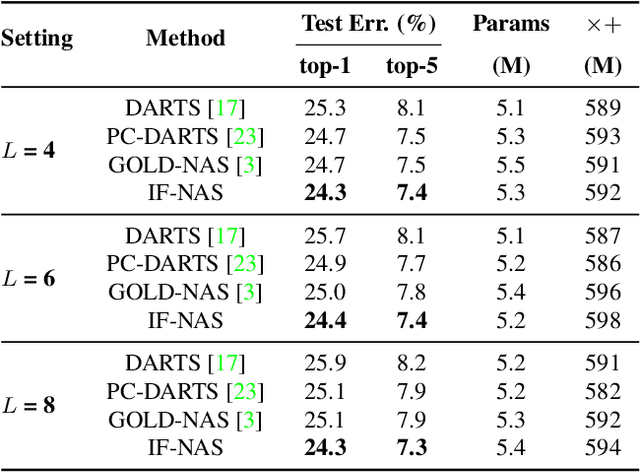
The existing neural architecture search algorithms are mostly working on search spaces with short-distance connections. We argue that such designs, though safe and stable, obstacles the search algorithms from exploring more complicated scenarios. In this paper, we build the search algorithm upon a complicated search space with long-distance connections, and show that existing weight-sharing search algorithms mostly fail due to the existence of \textbf{interleaved connections}. Based on the observation, we present a simple yet effective algorithm named \textbf{IF-NAS}, where we perform a periodic sampling strategy to construct different sub-networks during the search procedure, avoiding the interleaved connections to emerge in any of them. In the proposed search space, IF-NAS outperform both random sampling and previous weight-sharing search algorithms by a significant margin. IF-NAS also generalizes to the micro cell-based spaces which are much easier. Our research emphasizes the importance of macro structure and we look forward to further efforts along this direction.
Feature-Gate Coupling for Dynamic Network Pruning
Nov 29, 2021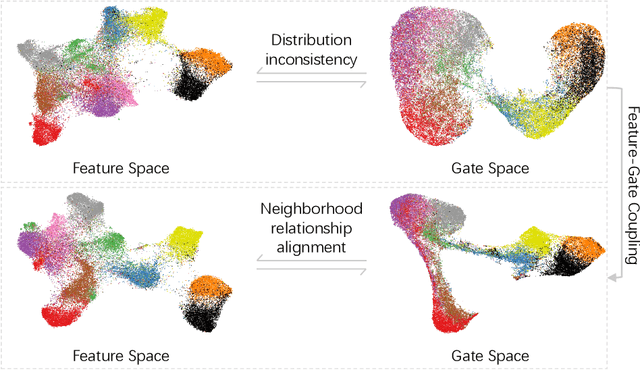
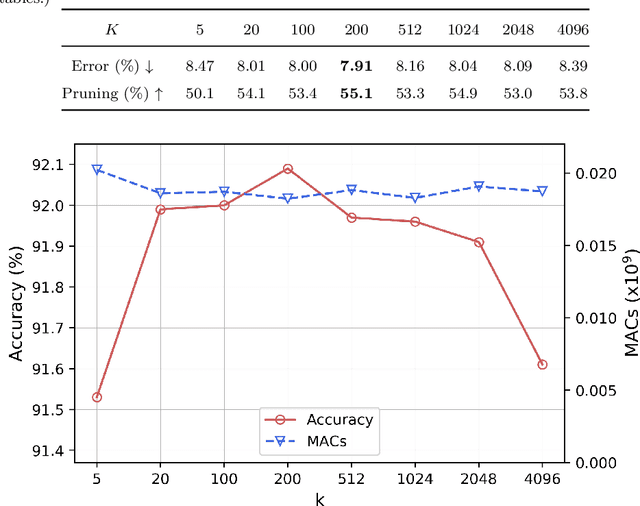
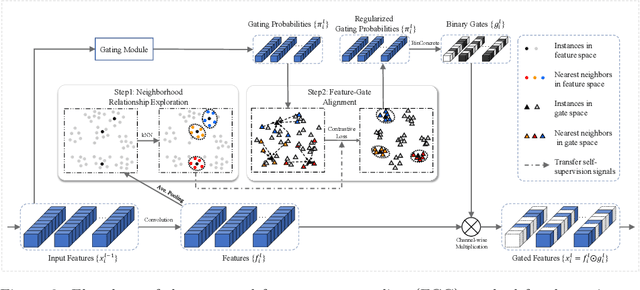
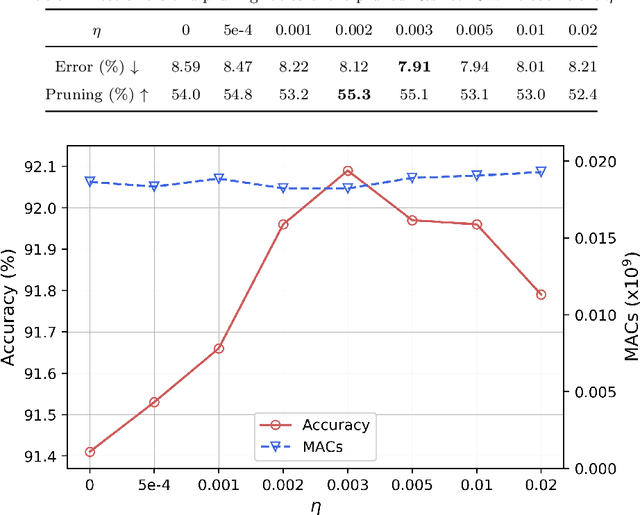
Gating modules have been widely explored in dynamic network pruning to reduce the run-time computational cost of deep neural networks while preserving the representation of features. Despite the substantial progress, existing methods remain ignoring the consistency between feature and gate distributions, which may lead to distortion of gated features. In this paper, we propose a feature-gate coupling (FGC) approach aiming to align distributions of features and gates. FGC is a plug-and-play module, which consists of two steps carried out in an iterative self-supervised manner. In the first step, FGC utilizes the $k$-Nearest Neighbor method in the feature space to explore instance neighborhood relationships, which are treated as self-supervisory signals. In the second step, FGC exploits contrastive learning to regularize gating modules with generated self-supervisory signals, leading to the alignment of instance neighborhood relationships within the feature and gate spaces. Experimental results validate that the proposed FGC method improves the baseline approach with significant margins, outperforming the state-of-the-arts with better accuracy-computation trade-off. Code is publicly available.
Semantic-Aware Generation for Self-Supervised Visual Representation Learning
Nov 25, 2021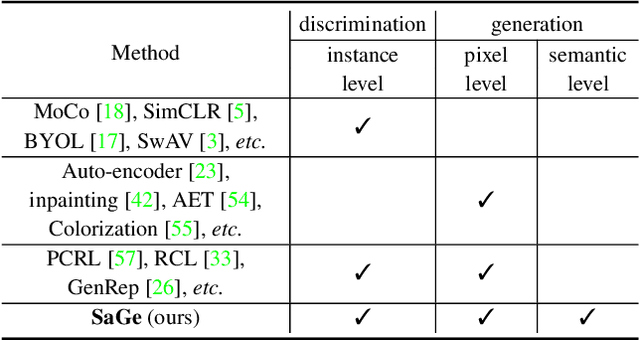
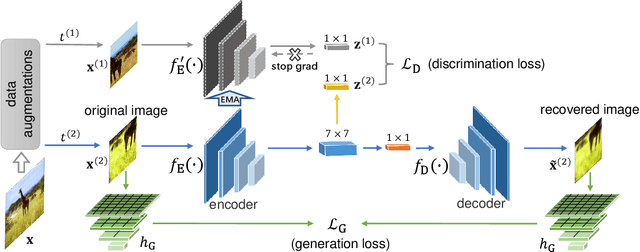

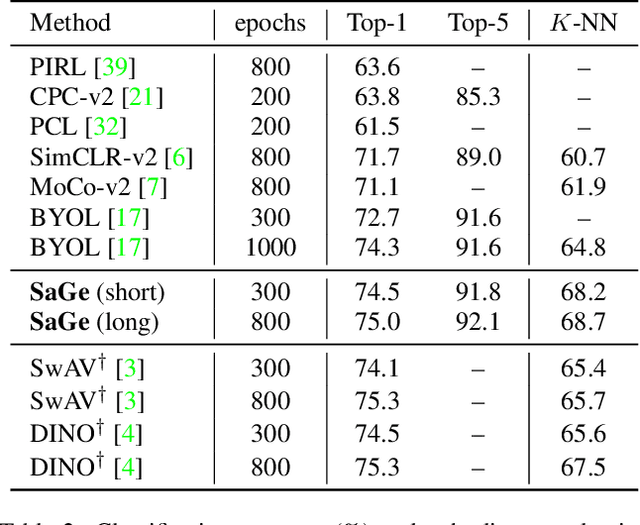
In this paper, we propose a self-supervised visual representation learning approach which involves both generative and discriminative proxies, where we focus on the former part by requiring the target network to recover the original image based on the mid-level features. Different from prior work that mostly focuses on pixel-level similarity between the original and generated images, we advocate for Semantic-aware Generation (SaGe) to facilitate richer semantics rather than details to be preserved in the generated image. The core idea of implementing SaGe is to use an evaluator, a deep network that is pre-trained without labels, for extracting semantic-aware features. SaGe complements the target network with view-specific features and thus alleviates the semantic degradation brought by intensive data augmentations. We execute SaGe on ImageNet-1K and evaluate the pre-trained models on five downstream tasks including nearest neighbor test, linear classification, and fine-scaled image recognition, demonstrating its ability to learn stronger visual representations.
Discovery-and-Selection: Towards Optimal Multiple Instance Learning for Weakly Supervised Object Detection
Oct 18, 2021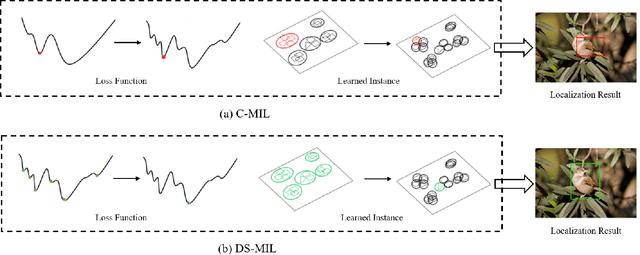
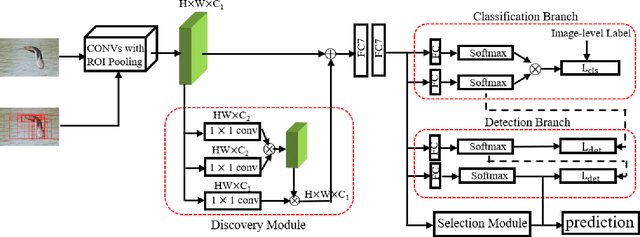
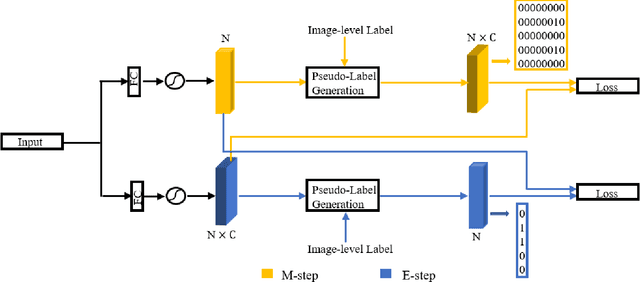

Weakly supervised object detection (WSOD) is a challenging task that requires simultaneously learn object classifiers and estimate object locations under the supervision of image category labels. A major line of WSOD methods roots in multiple instance learning which regards images as bags of instance and selects positive instances from each bag to learn the detector. However, a grand challenge emerges when the detector inclines to converge to discriminative parts of objects rather than the whole objects. In this paper, under the hypothesis that optimal solutions are included in local minima, we propose a discoveryand-selection approach fused with multiple instance learning (DS-MIL), which finds rich local minima and select optimal solutions from multiple local minima. To implement DS-MIL, an attention module is designed so that more context information can be captured by feature maps and more valuable proposals can be collected during training. With proposal candidates, a re-rank module is designed to select informative instances for object detector training. Experimental results on commonly used benchmarks show that our proposed DS-MIL approach can consistently improve the baselines, reporting state-of-the-art performance.