 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter and Computation Efficient Transfer Learning for Vision-Language Pre-trained Models
Sep 06, 2023With ever increasing parameters and computation, vision-language pre-trained (VLP) models exhibit prohibitive expenditure in downstream task adaption. Recent endeavors mainly focus on parameter efficient transfer learning (PETL) for VLP models by only updating a small number of parameters. However, excessive computational overhead still plagues the application of VLPs. In this paper, we aim at parameter and computation efficient transfer learning (PCETL) for VLP models. In particular, PCETL not only needs to limit the number of trainable parameters in VLP models, but also to reduce the computational redundancy during inference, thus enabling a more efficient transfer. To approach this target, we propose a novel dynamic architecture skipping (DAS) approach towards effective PCETL. Instead of directly optimizing the intrinsic architectures of VLP models, DAS first observes the significances of their modules to downstream tasks via a reinforcement learning (RL) based process, and then skips the redundant ones with lightweight networks, i.e., adapters, according to the obtained rewards. In this case, the VLP model can well maintain the scale of trainable parameters while speeding up its inference on downstream tasks. To validate DAS, we apply it to two representative VLP models, namely ViLT and METER, and conduct extensive experiments on a bunch of VL tasks. The experimental results not only show the great advantages of DAS in reducing computational complexity, e.g. -11.97% FLOPs of METER on VQA2.0, but also confirm its competitiveness against existing PETL methods in terms of parameter scale and performance. Our source code is given in our appendix.
Approximated Prompt Tuning for Vision-Language Pre-trained Models
Jun 27, 2023



Prompt tuning is a parameter-efficient way to deploy large-scale pre-trained models to downstream tasks by adding task-specific tokens. In terms of vision-language pre-trained (VLP) models, prompt tuning often requires a large number of learnable tokens to bridge the gap between the pre-training and downstream tasks, which greatly exacerbates the already high computational overhead. In this paper, we revisit the principle of prompt tuning for Transformer-based VLP models and reveal that the impact of soft prompt tokens can be actually approximated via independent information diffusion steps, thereby avoiding the expensive global attention modeling and reducing the computational complexity to a large extent. Based on this finding, we propose a novel Approximated Prompt Tuning (APT) approach towards efficient VL transfer learning. To validate APT, we apply it to two representative VLP models, namely ViLT and METER, and conduct extensive experiments on a bunch of downstream tasks. Meanwhile, the generalization of APT is also validated on CLIP for image classification. The experimental results not only show the superior performance gains and computation efficiency of APT against the conventional prompt tuning methods, e.g., +6.6% accuracy and -64.62% additional computation overhead on METER, but also confirm its merits over other parameter-efficient transfer learning approaches.
Adapting Pre-trained Language Models to Vision-Language Tasks via Dynamic Visual Prompting
Jun 01, 2023Pre-trained language models (PLMs) have played an increasing role in multimedia research. In terms of vision-language (VL) tasks, they often serve as a language encoder and still require an additional fusion network for VL reasoning, resulting in excessive memory overhead. In this paper, we focus on exploring PLMs as a stand-alone model for VL reasoning tasks. Inspired by the recently popular prompt tuning, we first prove that the processed visual features can be also projected onto the semantic space of PLMs and act as prompt tokens to bridge the gap between single- and multi-modal learning. However, this solution exhibits obvious redundancy in visual information and model inference, and the placement of prompt tokens also greatly affects the final performance. Based on these observations, we further propose a novel transfer learning approach for PLMs, termed Dynamic Visual Prompting (DVP). Concretely, DVP first deploys a cross-attention module to obtain text-related and compact visual prompt tokens, thereby greatly reducing the input length of PLMs. To obtain the optimal placement, we also equip DVP with a reinforcement-learning based search algorithm, which can automatically merge DVP with PLMs for different VL tasks via a very short search process. In addition, we also experiment DVP with the recently popular adapter approach to keep the most parameters of PLMs intact when adapting to VL tasks, helping PLMs achieve a quick shift between single- and multi-modal tasks. We apply DVP to two representative PLMs, namely BERT and T5, and conduct extensive experiments on a set of VL reasoning benchmarks including VQA2.0, GQA and SNLIVE. The experimental results not only show the advantage of DVP on efficiency and performance, but also confirm its superiority in adapting pre-trained language models to VL tasks.
What Goes beyond Multi-modal Fusion in One-stage Referring Expression Comprehension: An Empirical Study
Apr 17, 2022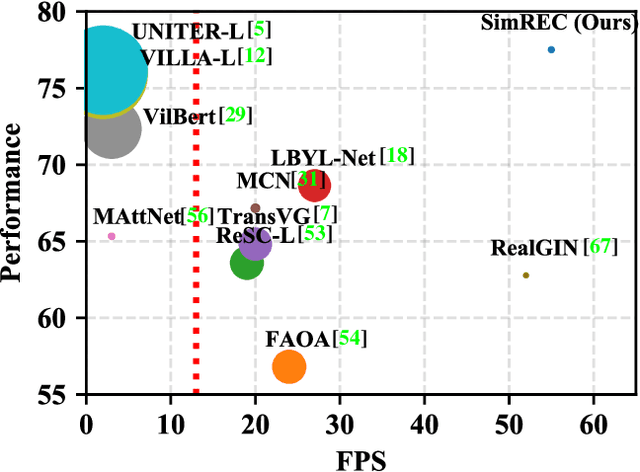
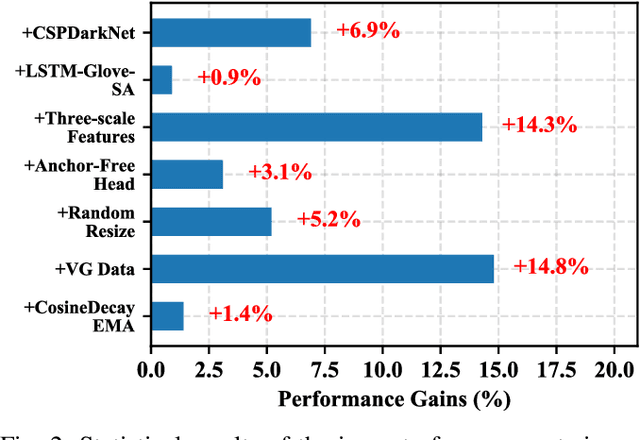
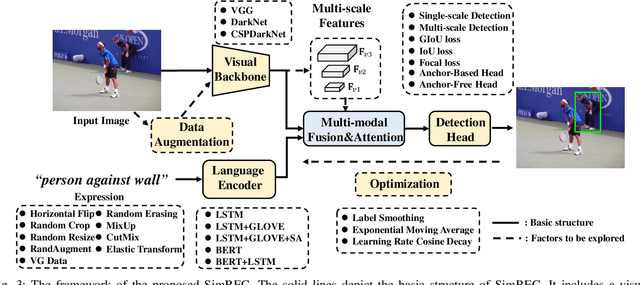
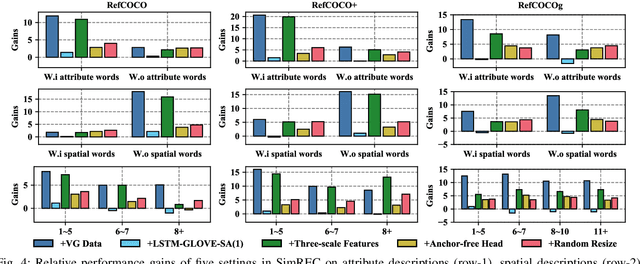
Most of the existing work in one-stage referring expression comprehension (REC) mainly focuses on multi-modal fusion and reasoning, while the influence of other factors in this task lacks in-depth exploration. To fill this gap, we conduct an empirical study in this paper. Concretely, we first build a very simple REC network called SimREC, and ablate 42 candidate designs/settings, which covers the entire process of one-stage REC from network design to model training. Afterwards, we conduct over 100 experimental trials on three benchmark datasets of REC. The extensive experimental results not only show the key factors that affect REC performance in addition to multi-modal fusion, e.g., multi-scale features and data augmentation, but also yield some findings that run counter to conventional understanding. For example, as a vision and language (V&L) task, REC does is less impacted by language prior. In addition, with a proper combination of these findings, we can improve the performance of SimREC by a large margin, e.g., +27.12% on RefCOCO+, which outperforms all existing REC methods. But the most encouraging finding is that with much less training overhead and parameters, SimREC can still achieve better performance than a set of large-scale pre-trained models, e.g., UNITER and VILLA, portraying the special role of REC in existing V&L research.