 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Dynamic Gaussian Splatting
Feb 03, 2026While Dynamic Gaussian Splatting enables high-fidelity 4D reconstruction, its deployment is severely hindered by a fundamental dilemma: unconstrained densification leads to excessive memory consumption incompatible with edge devices, whereas heuristic pruning fails to achieve optimal rendering quality under preset Gaussian budgets. In this work, we propose Constrained Dynamic Gaussian Splatting (CDGS), a novel framework that formulates dynamic scene reconstruction as a budget-constrained optimization problem to enforce a strict, user-defined Gaussian budget during training. Our key insight is to introduce a differentiable budget controller as the core optimization driver. Guided by a multi-modal unified importance score, this controller fuses geometric, motion, and perceptual cues for precise capacity regulation. To maximize the utility of this fixed budget, we further decouple the optimization of static and dynamic elements, employing an adaptive allocation mechanism that dynamically distributes capacity based on motion complexity. Furthermore, we implement a three-phase training strategy to seamlessly integrate these constraints, ensuring precise adherence to the target count. Coupled with a dual-mode hybrid compression scheme, CDGS not only strictly adheres to hardware constraints (error < 2%}) but also pushes the Pareto frontier of rate-distortion performance. Extensive experiments demonstrate that CDGS delivers optimal rendering quality under varying capacity limits, achieving over 3x compression compared to state-of-the-art methods.
Pairing-free Group-level Knowledge Distillation for Robust Gastrointestinal Lesion Classification in White-Light Endoscopy
Jan 14, 2026White-Light Imaging (WLI) is the standard for endoscopic cancer screening, but Narrow-Band Imaging (NBI) offers superior diagnostic details. A key challenge is transferring knowledge from NBI to enhance WLI-only models, yet existing methods are critically hampered by their reliance on paired NBI-WLI images of the same lesion, a costly and often impractical requirement that leaves vast amounts of clinical data untapped. In this paper, we break this paradigm by introducing PaGKD, a novel Pairing-free Group-level Knowledge Distillation framework that that enables effective cross-modal learning using unpaired WLI and NBI data. Instead of forcing alignment between individual, often semantically mismatched image instances, PaGKD operates at the group level to distill more complete and compatible knowledge across modalities. Central to PaGKD are two complementary modules: (1) Group-level Prototype Distillation (GKD-Pro) distills compact group representations by extracting modality-invariant semantic prototypes via shared lesion-aware queries; (2) Group-level Dense Distillation (GKD-Den) performs dense cross-modal alignment by guiding group-aware attention with activation-derived relation maps. Together, these modules enforce global semantic consistency and local structural coherence without requiring image-level correspondence. Extensive experiments on four clinical datasets demonstrate that PaGKD consistently and significantly outperforms state-of-the-art methods, achieving relative AUC improvements of 3.3%, 1.1%, 2.8%, and 3.2%, respectively, establishing a new direction for cross-modal learning from unpaired data.
Agentic Retoucher for Text-To-Image Generation
Jan 08, 2026Text-to-image (T2I) diffusion models such as SDXL and FLUX have achieved impressive photorealism, yet small-scale distortions remain pervasive in limbs, face, text and so on. Existing refinement approaches either perform costly iterative re-generation or rely on vision-language models (VLMs) with weak spatial grounding, leading to semantic drift and unreliable local edits. To close this gap, we propose Agentic Retoucher, a hierarchical decision-driven framework that reformulates post-generation correction as a human-like perception-reasoning-action loop. Specifically, we design (1) a perception agent that learns contextual saliency for fine-grained distortion localization under text-image consistency cues, (2) a reasoning agent that performs human-aligned inferential diagnosis via progressive preference alignment, and (3) an action agent that adaptively plans localized inpainting guided by user preference. This design integrates perceptual evidence, linguistic reasoning, and controllable correction into a unified, self-corrective decision process. To enable fine-grained supervision and quantitative evaluation, we further construct GenBlemish-27K, a dataset of 6K T2I images with 27K annotated artifact regions across 12 categories. Extensive experiments demonstrate that Agentic Retoucher consistently outperforms state-of-the-art methods in perceptual quality, distortion localization and human preference alignment, establishing a new paradigm for self-corrective and perceptually reliable T2I generation.
MultiEgo: A Multi-View Egocentric Video Dataset for 4D Scene Reconstruction
Dec 12, 2025Multi-view egocentric dynamic scene reconstruction holds significant research value for applications in holographic documentation of social interactions. However, existing reconstruction datasets focus on static multi-view or single-egocentric view setups, lacking multi-view egocentric datasets for dynamic scene reconstruction. Therefore, we present MultiEgo, the first multi-view egocentric dataset for 4D dynamic scene reconstruction. The dataset comprises five canonical social interaction scenes: meetings, performances, and a presentation. Each scene provides five authentic egocentric videos captured by participants wearing AR glasses. We design a hardware-based data acquisition system and processing pipeline, achieving sub-millisecond temporal synchronization across views, coupled with accurate pose annotations. Experiment validation demonstrates the practical utility and effectiveness of our dataset for free-viewpoint video (FVV) applications, establishing MultiEgo as a foundational resource for advancing multi-view egocentric dynamic scene reconstruction research.
ManipShield: A Unified Framework for Image Manipulation Detection, Localization and Explanation
Nov 18, 2025



With the rapid advancement of generative models, powerful image editing methods now enable diverse and highly realistic image manipulations that far surpass traditional deepfake techniques, posing new challenges for manipulation detection. Existing image manipulation detection and localization (IMDL) benchmarks suffer from limited content diversity, narrow generative-model coverage, and insufficient interpretability, which hinders the generalization and explanation capabilities of current manipulation detection methods. To address these limitations, we introduce \textbf{ManipBench}, a large-scale benchmark for image manipulation detection and localization focusing on AI-edited images. ManipBench contains over 450K manipulated images produced by 25 state-of-the-art image editing models across 12 manipulation categories, among which 100K images are further annotated with bounding boxes, judgment cues, and textual explanations to support interpretable detection. Building upon ManipBench, we propose \textbf{ManipShield}, an all-in-one model based on a Multimodal Large Language Model (MLLM) that leverages contrastive LoRA fine-tuning and task-specific decoders to achieve unified image manipulation detection, localization, and explanation. Extensive experiments on ManipBench and several public datasets demonstrate that ManipShield achieves state-of-the-art performance and exhibits strong generality to unseen manipulation models. Both ManipBench and ManipShield will be released upon publication.
PrismGS: Physically-Grounded Anti-Aliasing for High-Fidelity Large-Scale 3D Gaussian Splatting
Oct 09, 20253D Gaussian Splatting (3DGS) has recently enabled real-time photorealistic rendering in compact scenes, but scaling to large urban environments introduces severe aliasing artifacts and optimization instability, especially under high-resolution (e.g., 4K) rendering. These artifacts, manifesting as flickering textures and jagged edges, arise from the mismatch between Gaussian primitives and the multi-scale nature of urban geometry. While existing ``divide-and-conquer'' pipelines address scalability, they fail to resolve this fidelity gap. In this paper, we propose PrismGS, a physically-grounded regularization framework that improves the intrinsic rendering behavior of 3D Gaussians. PrismGS integrates two synergistic regularizers. The first is pyramidal multi-scale supervision, which enforces consistency by supervising the rendering against a pre-filtered image pyramid. This compels the model to learn an inherently anti-aliased representation that remains coherent across different viewing scales, directly mitigating flickering textures. This is complemented by an explicit size regularization that imposes a physically-grounded lower bound on the dimensions of the 3D Gaussians. This prevents the formation of degenerate, view-dependent primitives, leading to more stable and plausible geometric surfaces and reducing jagged edges. Our method is plug-and-play and compatible with existing pipelines. Extensive experiments on MatrixCity, Mill-19, and UrbanScene3D demonstrate that PrismGS achieves state-of-the-art performance, yielding significant PSNR gains around 1.5 dB against CityGaussian, while maintaining its superior quality and robustness under demanding 4K rendering.
AlignGS: Aligning Geometry and Semantics for Robust Indoor Reconstruction from Sparse Views
Oct 09, 2025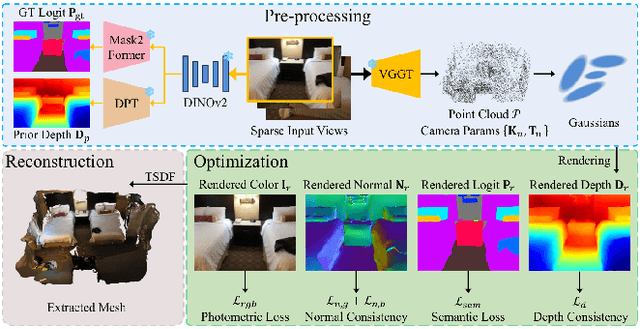
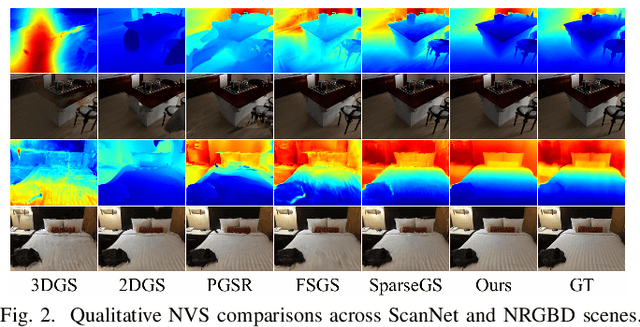
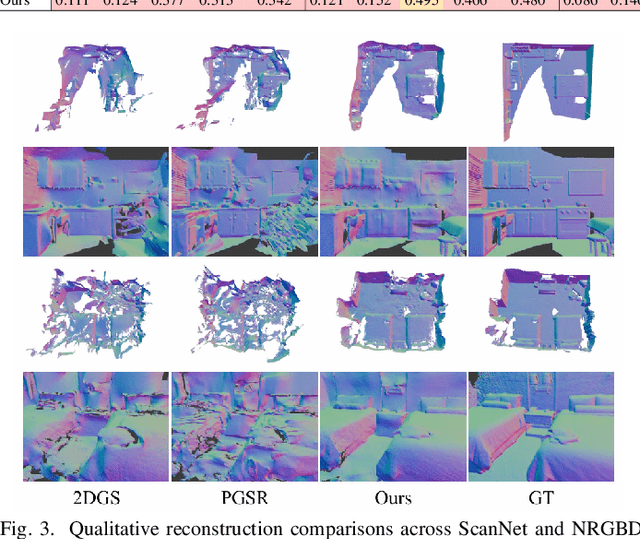
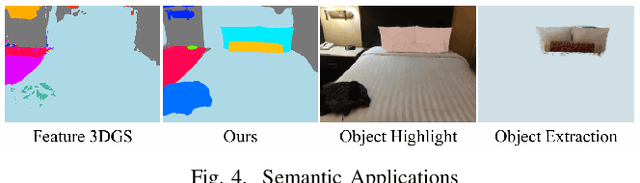
The demand for semantically rich 3D models of indoor scenes is rapidly growing, driven by applications in augmented reality, virtual reality, and robotics. However, creating them from sparse views remains a challenge due to geometric ambiguity. Existing methods often treat semantics as a passive feature painted on an already-formed, and potentially flawed, geometry. We posit that for robust sparse-view reconstruction, semantic understanding instead be an active, guiding force. This paper introduces AlignGS, a novel framework that actualizes this vision by pioneering a synergistic, end-to-end optimization of geometry and semantics. Our method distills rich priors from 2D foundation models and uses them to directly regularize the 3D representation through a set of novel semantic-to-geometry guidance mechanisms, including depth consistency and multi-faceted normal regularization. Extensive evaluations on standard benchmarks demonstrate that our approach achieves state-of-the-art results in novel view synthesis and produces reconstructions with superior geometric accuracy. The results validate that leveraging semantic priors as a geometric regularizer leads to more coherent and complete 3D models from limited input views. Our code is avaliable at https://github.com/MediaX-SJTU/AlignGS .
AutoEmpirical: LLM-Based Automated Research for Empirical Software Fault Analysis
Oct 06, 2025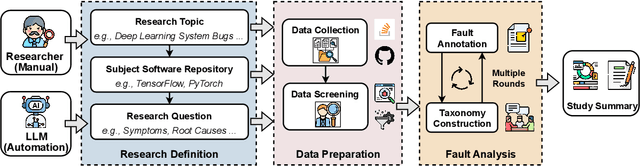

Understanding software faults is essential for empirical research in software development and maintenance. However, traditional fault analysis, while valuable, typically involves multiple expert-driven steps such as collecting potential faults, filtering, and manual investigation. These processes are both labor-intensive and time-consuming, creating bottlenecks that hinder large-scale fault studies in complex yet critical software systems and slow the pace of iterative empirical research. In this paper, we decompose the process of empirical software fault study into three key phases: (1) research objective definition, (2) data preparation, and (3) fault analysis, and we conduct an initial exploration study of applying Large Language Models (LLMs) for fault analysis of open-source software. Specifically, we perform the evaluation on 3,829 software faults drawn from a high-quality empirical study. Our results show that LLMs can substantially improve efficiency in fault analysis, with an average processing time of about two hours, compared to the weeks of manual effort typically required. We conclude by outlining a detailed research plan that highlights both the potential of LLMs for advancing empirical fault studies and the open challenges that required be addressed to achieve fully automated, end-to-end software fault analysis.
Rethinking Testing for LLM Applications: Characteristics, Challenges, and a Lightweight Interaction Protocol
Aug 28, 2025Applications of Large Language Models~(LLMs) have evolved from simple text generators into complex software systems that integrate retrieval augmentation, tool invocation, and multi-turn interactions. Their inherent non-determinism, dynamism, and context dependence pose fundamental challenges for quality assurance. This paper decomposes LLM applications into a three-layer architecture: \textbf{\textit{System Shell Layer}}, \textbf{\textit{Prompt Orchestration Layer}}, and \textbf{\textit{LLM Inference Core}}. We then assess the applicability of traditional software testing methods in each layer: directly applicable at the shell layer, requiring semantic reinterpretation at the orchestration layer, and necessitating paradigm shifts at the inference core. A comparative analysis of Testing AI methods from the software engineering community and safety analysis techniques from the AI community reveals structural disconnects in testing unit abstraction, evaluation metrics, and lifecycle management. We identify four fundamental differences that underlie 6 core challenges. To address these, we propose four types of collaborative strategies (\emph{Retain}, \emph{Translate}, \emph{Integrate}, and \emph{Runtime}) and explore a closed-loop, trustworthy quality assurance framework that combines pre-deployment validation with runtime monitoring. Based on these strategies, we offer practical guidance and a protocol proposal to support the standardization and tooling of LLM application testing. We propose a protocol \textbf{\textit{Agent Interaction Communication Language}} (AICL) that is used to communicate between AI agents. AICL has the test-oriented features and is easily integrated in the current agent framework.
FreeVPS: Repurposing Training-Free SAM2 for Generalizable Video Polyp Segmentation
Aug 27, 2025Existing video polyp segmentation (VPS) paradigms usually struggle to balance between spatiotemporal modeling and domain generalization, limiting their applicability in real clinical scenarios. To embrace this challenge, we recast the VPS task as a track-by-detect paradigm that leverages the spatial contexts captured by the image polyp segmentation (IPS) model while integrating the temporal modeling capabilities of segment anything model 2 (SAM2). However, during long-term polyp tracking in colonoscopy videos, SAM2 suffers from error accumulation, resulting in a snowball effect that compromises segmentation stability. We mitigate this issue by repurposing SAM2 as a video polyp segmenter with two training-free modules. In particular, the intra-association filtering module eliminates spatial inaccuracies originating from the detecting stage, reducing false positives. The inter-association refinement module adaptively updates the memory bank to prevent error propagation over time, enhancing temporal coherence. Both modules work synergistically to stabilize SAM2, achieving cutting-edge performance in both in-domain and out-of-domain scenarios. Furthermore, we demonstrate the robust tracking capabilities of FreeVPS in long-untrimmed colonoscopy videos, underscoring its potential reliable clinical analysis.